Big Data
Bei Big Data handelt es sich um eine Begrifflichkeit aus der Fachliteratur, die allerdings auch in der medialen Welt Einzug gefunden hat und aufgrund ihrer breiten Themendeckung oft mit in Diskussionen einfließt. Big Data hat seinen Ursprung in der Wissenschaft als auch bei webbasierten Firmen, die zudem Technologien entwickelten, die heutzutage zu den bekanntesten Big Data-Technologien gehören (Fasel und Meier 2016, S. 4-5).
Einordnung
Eine Herausforderung bei der Definition von Big Data ist seine Variabilität, die je nach Betrachtungsweise zu einer anderen Sicht führt. So könnte der Term Big Data als relativ betrachtet werden. Dies ist darauf zurückzuführen, dass der Bezug zur Größe je nach Einsatzgebiet unterschiedlich interpretiert werden kann. So ist eine Datenmenge, die um die 10 Terabyte umfasst, für ein mittelständisches Unternehmen ausreichend, um als Big Data bezeichnet zu werden. Allerdings würde ein international agierender Pharmakonzern eher ab einer Menge von 500 Terabyte über Big Data sprechen. Für eine staatliche Behörde würde eine Datenmenge von einem Petabyte vergleichsweise gering sein und somit nicht als Big Data bezeichnet werden (Minelli et al. 2012, S. 9).
In der Industrie bzw. aus der Geschäftsperspektive wird in der Zwischenzeit auf eine gemeinsame Definition zurückgegriffen. Danach wird Big Data in den sogenannten 3Vs beschrieben. Die 3Vs stehen dabei für die englischen Begriffe „Volume“, „Velocity“ und „Variety“, welche übersetzt für Datenvolumen, Geschwindigkeit und Vielfalt stehen. Die 3Vs bilden drei Dimensionen bzw. Charakteristiken, deren Schnittmenge als Big Data zu begreifen ist (Russom 2011, S. 6); (Minelli et al. 2012, S. 9);(Williams 2016, S. 33). In einer von IBM durchgeführten Studie im Jahr 2012, in der 1.144 Fachleute aus 95 Ländern und 26 Branchen bezüglich Big Data befragt wurden, wurde sich einer Definition angenähert. Bei der Auswertung und Formulierung bezüglich der Definition von Big Data ließ sich ebenfalls eine starke Tendenz zu der etablierten Definition der 3Vs beobachten. IBM selbst erweitert die Definition allerdings um ein weiteres Element und bezeichnet es als „Veracity“ – Richtigkeit (Schroeck et al. 2012, S. 4).
Fasel und Meier beziehen sich bei ihrer Definition zu Big Data auf die Definitionen von Adrian Merv und dem McKinsey Global Institute und kategorisieren Big Data ebenfalls in die oben genannten 3Vs (Fasel und Meier 2016, S. 5-6).
Annährung an eine Definition
Im Folgenden werden die drei Charakteristika, welche Big Data definieren, genauer erläutert, und um eine weitere, auch in der Literatur teilweise hinzugefügte Dimension („Richtigkeit“) ergänzt.
Volume: Wie bereits erwähnt, ist das Volumen bzw. die Datenmenge eine relative Variable. Auch bei der näheren Betrachtung des Charakteristikums Volumen bleibt diese Betrachtungsweise bestehen. IBM schlussfolgert nach deren Studie, dass „groß“ je nach Branche und Region verschieden verstanden wird und somit in Zahlen die Spanne zwischen einem Terabyte und einem Petabyte liegen kann. Allerdings gaben auch 10 % der Befragten an, dass allein der Begriff „groß“ schon schwer verständlich in Bezug auf eine Datenmenge ist. Als Quintessenz wurde allerdings festgehalten, dass eine Datenmenge, die als aktuell bezeichnet wird, in naher oder ferner Zukunft wiederum verhältnismäßig klein erscheinen wird (Schroeck et al. 2012, S. 4).
In der Ausarbeitung von Fasel und Meier hingegen wird die Spanne der Größe von Big Data zwischen dem Terra- und Zetabyte-Bereich betrachtet (Fasel und Meier 2016, S. 6). Die Gartner Group Inc. sieht, was die Datenmenge betrifft, allerdings eine zusätzliche Problematik. Zwar bietet die Hinterlegung bzw. Speicherung der Daten kein Problem mehr, allerdings führt die Größe des Datenbestandes zu Problemen bei der Analyse und Auswertung (Gartner 2011).
Variety: Das Charakteristikum Variety bzw. Vielfalt beschreibt die Menge der unterschiedlichen Datentypen, -formate und -quellen. Daten werden in dieser Hinsicht als strukturiert, semi-strukturiert und unstrukturiert klassifiziert. Da Daten nicht ausschließlich innerhalb des eigenen Unternehmens anfallen, muss diesbezüglich zudem zwischen internen und externen Daten unterschieden werden (Schroeck et al. 2012, S. 4).
Unter unstrukturierten Daten werden dabei Bilder, Videos, kleinere Clips, Textnachrichten und Weblogs verstanden. Auch sollte die Bezeichnung Daten in dieser Hinsicht vorsichtig gewählt sein, da es sich im engeren Sinne um Inhalt handelt (Williams 2016, S. 34).
Bei semi-strukturierten Daten handelt es sich weiterhin um unstrukturierte Daten, allerdings mit dem signifikanten Unterschied, dass diese semantische Inhalte aufweisen und somit einer bestimmten Hierarchie untergliedert werden können (Minelli et al. 2012, S. 11).
Strukturierte Daten sind hingegen leicht zu definieren, speichern und analysieren (Minelli et al. 2012, S. 11). Diese sind in Entitäten organisiert, welche ein definiertes Format aufweisen, wie beispielweise XML-Dokumente oder Datensatztabellen, die einem vordefinierten Schema entsprechen (White 2012, S. 5).
Die Gartner Group Inc. gliedert das Charakteristikum Vielfalt in tabellierte Datenbestände, hierarchische Daten, Dokumente, E-Mails, Messdaten etc. (Gartner 2011).
Velocity: Die Geschwindigkeit ist jenes Charakteristikum, welches die schnelle Erzeugung von Daten, deren Verarbeitung und Analyse beschreibt. Die Tendenz der Geschwindigkeit ist dabei fortwährend steigend. Zurückführen lässt sich dies unter anderem auf die in Echtzeit generierenden Daten. Allerdings ist die „[…] Notwendigkeit, Datenströme in die Geschäftsprozesse und die Entscheidungsfindung zu integrieren […]“ (Schroeck et al. 2012, S. 4), ebenfalls wichtig.
Die Geschwindigkeit bei der Speicherung von Daten hat sich im Verhältnis zur Vergangenheit ebenfalls geändert. So werden Datenmengen, die in der Vergangenheit innerhalb eines oder mehrerer Monate erzeugt wurden, heute in einer Minute erzeugt. Soziale Netzwerke und der Gebrauch des Internets lassen zudem in Sekunden enorme Datenbestände entstehen (Williams 2016, S. 34).
Wie bereits erwähnt, gibt es weitere Elemente, mit denen die Definition von Big Data erweitert werden kann. Die vorliegende Bachelorarbeit versteht, angelehnt an der Definition von IBM, das Charakteristikum Veracity bzw. Richtigkeit ebenfalls als eine Schnittmenge von Big Data.
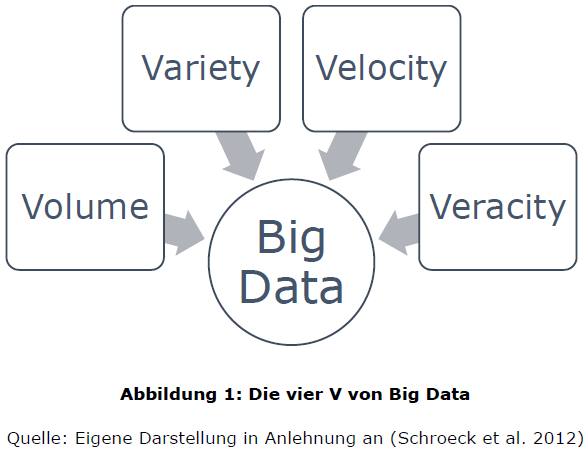
Veracity: Richtigkeit ist ein Charakteristikum, welches die Glaubhaftigkeit von bezogenen Daten bzw. Informationen hervorhebt. Um allerdings zuverlässige Informationen wiederzugeben, ist es notwendig, qualitativ hochwertige Daten zu haben. Big Data ist, wie im Punkt Variety beschrieben, eine Ansammlung unterschiedlichster Daten. Dies führt dazu, dass durchaus Daten mitaufgenommen werden, welche die Auswertung erschweren können. So sind unter anderem Wetterdaten und wirtschaftliche Entwicklungen trotz Unmengen gesammelter Daten schwer vorhersagbar (Schroeck et al. 2012, S. 5).
Unterschiedliche Technologien können bei Big Data für verschiedene Zwecke verwendet werden. Dementsprechend kann bei Big Data zwischen erzeugenden, verarbeitenden, integrierenden, speichernden und auswertenden Technologien unterschieden werden. Zur Erzeugung von Big Data sind beispielweise Sensoren oder auch Geo-Tagging als unterstützende Technologien nutzbar. Streaming und Virtualisierung sind dabei die unterstützenden Technologien für die Verbreitung und Integration. Die Cloud oder analytische Plattformen stellen dabei die Basis für die Speicherung von großen Datenmengen. Letztlich dienen Visualisierungen und Advanced Analytics der Auswertung bzw. Analyse der generierten Daten (Gluchowski und Chamoni 2015, S. 61).
Recent Comments