Eine in [Bacher et al., 2010] beschriebene Mazahl zur Bestimmung der formalen Gultigkeit ist der in Abschnitt 4.1.8 bereits beschriebene Silhouettekoeffizient. Da die Berechnung sehr ressourcenintensiv ist, wird im Rahmen der Predictive Analysis Library fur die Ermittlung der optimalen Anzahl von Clustern k eine angenaherte Mazahl, die Slight Silhouette verwendet. Diese stellt Performanz in der Vordergrund, allerdings schatzt diese den Silhouettenkoeffizienten nur. Um den richtigen Silhouettenkoeffizienten zu berechnen, wird zunachst eine weitere Zwischentabelle definiert, die in Abbildung 27 zu sehen ist. Diese Tabelle wird lediglich mit der ID der Datensatze

Abb. 27: SQL-Code zur Denition der temporaren Tabelle zur Bestimmung des Silhouettenkoezienten fur die erste Iteration der Clusteranalyse
und der Zuordnung zu den jeweiligen Clustern befullt. Das Fullen der Tabellen erfolgt uber die Ergebnistabelle der Clusteranalyse, weshalb in Abschnitt 4.1.7 die Ergebnisse auch in physischen Tabellen festgehalten werden mussten. Abbildung 28 zeigt das notwendige SQL-Statement, um diese Tabelle mit den benotigten Datensatzen zu befullen. Auch diese PAL-Prozedur zur Validierung der Ergebnisse des k-Means- Algorithmus setzt eine Parametertabelle voraus. Die hierfur notwendige Definition der Parametertabelle und des Codes zur Ausfuhrung der Prozedur ist in Abbildung 29 zu sehen. Als Parameter ist zum einen die in Abschnitt 4.1.7 bereits erlauterte THREAD RATIO erforderlich, als auch die Anzahl der Variablen VARIABLE NUM, die fur die vorangehende Clusteranalyse herangezogen wurden. Die PAL-Prozedur
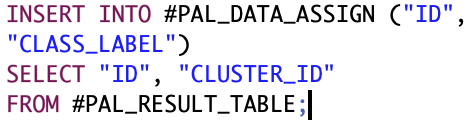
Abb. 28: SQL-Code zum Befullen der temporaren Tabelle zur Bestimmung des Silhouettenkoeffizienten fur die erste Iteration der Clusteranalyse

Abb. 29: SQLScript-Code zur Festlegung der Parameter und der darauf folgenden Validierung des k-Means-Algorithmus zur Ermittlung des Silhouettenkoeffizienten der ersten Iteration der Clusteranalyse
basiert genau wie die Durchfuhrung des k-Means-Algorithmus auf einer Datentabelle, diese muss ein ID-Feld besitzen und daraufhin durfen nur Attribute folgen.
Das Ergebnis dieser Berechnung ist fur die Clusterlosung basierend auf der euklidischen Distanz und der Initialisierungsmethode der ersten k Observationen ein Silhouettenkoeffizient von 0.6443. Dies weicht zwar von der geschatzten Slight Silhouette ab, allerdings befindet sich die Abweichung noch im Rahmen. Der Wert ist dennoch immer noch gut, sodass die Clusterlosung zumindest nach formalen Kriterien als eine gute Clusterlosung betrachtet werden kann.
Recent Comments