Folgender Abschnitt wird eine erste Clusteranalyse durchfuhren und sowohl die Ergebnisse, als auch die notwendigen Implementierungsschritte erlautert und evaluieren. Aufgrund dieser Erkenntnisse konnen dann in nachfolgenden Iterationen bestimmte
Auswahl der Variablen
Da die Auswahl der Variablen einen essentiellen Schritt einer Clusteranalyse darstellt, der konzeptionelles Fundament erfordert, erfolgt die Identi_kation der relevanten Variablen bereits in Abschnitt 3.5 mit Hilfe ausfuhrlicher Uberlegungen und Begr undungen. Das Resultat dieses Analyseschritts ist eine Menge von Kennzeichen fur Lokalitatstypen, nach denen uber die Google Places API gesucht werden kann und in Anbetracht einer moglichen Preisdi_erenzierung als relevante Faktoren betrachtet werden konnen. In Abbildung 4 ist eine Ubersicht aller als relevant identi_zierten Kennzeichen zu sehen.

identizierten Lokalitatstypen
Auf Basis der Erkenntnisse aus dem diesem Abschnitt wird hier also beschrieben, wie die identi_zierten, relevanten Variablen konkret im Hinblick auf das in Abschnitt 3.2 vorgestellte Anwendungsbeispiel ermittelt werden.
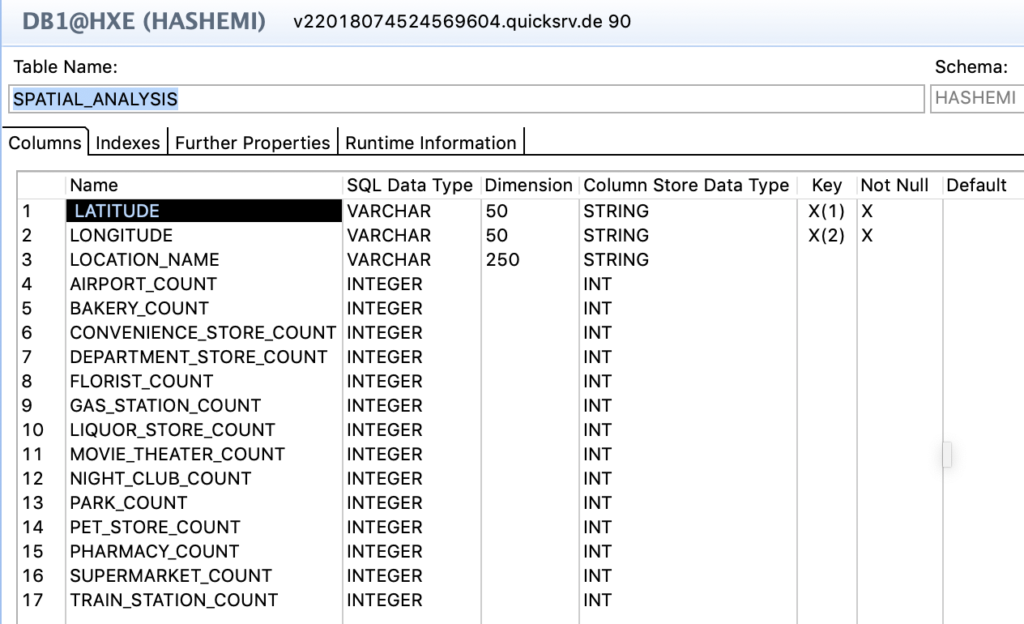
Tabellarischer Aufbau der Datenmatrix
Der Aufbau des Tabellenschemas der zu untersuchenden Datenmatrix ist in Abbildung 5 zu sehen. Die Datensatze reprasentieren jeweils die unterschiedlichen Filialen, eindeutig identi_ziert durch die Kombination von Breitengrad (in besagter Abbildung als das Feld LATITUDE) und Langengrad (in besagter Abbildung als das Feld LONGITUDE), oder alternativ durch den Bezeichner LOCATION NAME, der zu Kontrollzwecken ebenfalls aufgefuhrt ist1. Jede der in Abschnitt 3.5 identi_zierten Variablen wird durch ein Feld im Tabellenschema reprasentiert, welches einen Integer-Zahler darstellt. Dieser Zahler halt die Hau_gkeit von Lokalitaten mit ebenjenem Kennzeichen in einer Ganzzahl fest, beispielsweise halt der Zahler AIRPORT COUNT die Anzahl der Flughafen im spezi_zierten Radius fest, der Zahler SUPERMARKET COUNT die Anzahl der Supermarkte und analog hierzu erfolgt auch die Benennung der anderen Felder. Die Koordinaten und der Identi_kator werden durch einen textuellen Datentypen reprasentiert.
Java-IDE “Eclipse” aus der SAP HANA Modeler Perspective)
Abruf und Transformation der Daten
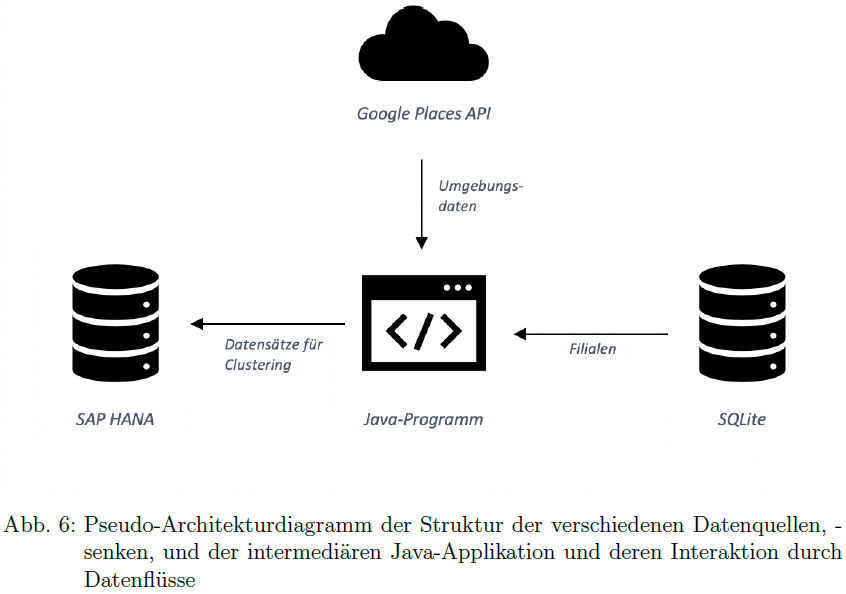
Der Abruf von Umgebungsdaten erfolgt, wie bereits in Abschnitt 3.3.2 beschrieben, uber RESTful Webservices der Google Places API. In Abbildung 2 und 3 wurden bereits ein exemplarische API-Aufruf und die entsprechende Ruckmeldung hinsichtlich des Aufbaus und der Funktionsweise der API vorgestellt. Allerdings soll der Abruf der Umgebungsdaten zu einzelnen EDEKA-Filialen selbstverstandlich nicht manuell erfolgen, sondern muss automatisiert werden, da die Anzahl der einzelnen APIAufrufe schon bei diesem uberschaubaren Anwendungsfall sehr hoch wird. Fur diesen Zweck wird eine intermediare Applikation in Java entwickelt, die fur den Abruf der Daten aus der API, sowie die persistente Speicherung in der HANA-Datenbank verantwortlich ist2. Die Rolle als intermediare Applikation zwischen den Technologien und die Datenusse in und aus der Java-Applikation wird in Abbildung 6 in einem Pseudo-Architekturdiagramm visualisiert. Es zeigt, dass die Java-Applikation als Bindeglied zwischen der SQLite-Datenbasis (die eine Ubersicht der zu untersuchenden Filialen beinhaltet), der Google Places API (die via Webservice Umgebungsdaten zur Verfugung stellt) und SAP HANA (dem Datenbanksystem, in dem die eigentliche Clusteranalyse durchgefuhrt wird) fungiert, indem es die Daten aus SQLite und der API zusammenfuhrt, transformiert und in SAP HANA uberfuhrt.
Betrachtet man die Applikation im Detail, iteriert sie durch jede Filiale der imfolgenden Vorgehensschritt behandelten Datenbasis und identi_ziert fur jede Filialedie umliegenden Lokalitaten uber die API. Fur diesen Zweck werden zunachst dieKoordinaten von allen Filialen aus der lokal vorliegenden SQLite-Datenbank ermittelt.Details zur grundlegenden Datenbasis werden im nachsten Abschnitt erlautert, andieser Stelle reicht es aus anzunehmen, dass gultige geogra_sche Koordinaten ermitteltwerden. Auf Basis dieser Koordinaten wird je Lokalitatstyp ein eigener API-Aufrufdurchgefuhrt, der in einem JSON-String resultiert. Abbildung 7 zeigt die Implementierung,die zu einem solchen API-Aufruf fuhrt. Die Anfrage basiert, wie bereits inAbschnitt 3.3.2 beschrieben, auf den Koordinaten des Standorts, fur die eine Suchestatt_ndet, dem Kennzeichen des Lokalitatstypen, nach dem gesucht werden, sowiedem Radius, innerhalb dessen gesucht werden soll, dementsprechend sehen auch dieParameter dieser Funktion diese Felder vor. Der ruckgemeldete JSON-String wirddaraufhin in ein JSONObject uberfuhrt, welches mehr Semantik bietet, als ein reiner String. Dementsprechend kann uber die Array-Methode .length() sehr einfach die Gro_edes Ergebnis-Arrays ‘result’ ermittelt werden, welches alle ruckgemeldeten Lokalitatenbeinhaltet. Somit wird die Anzahl der Lokalitaten ermittelt, die sich laut der GooglePlaces API im de_nierten Umkreis um die Koordinaten be_nden und das spezi_zierteKennzeichen aufweisen.

Abb. 7: Implementierung der Methode, die den API-Aufruf und die Ermittlung der Anzahl der umliegenden Lokalitaten eines bestimmten Typens realisiert (Screenshot aus der Java-IDE “Eclipse”)
Da analog zu den in Abschnitt 3.5 identi_zierten Variablen insgesamt 14 Kennzeichenje Filiale – also je Koordinatenpaar – berucksichtigt werden, mussen aufgrund der inAbschnitt 3.3.2 beschriebenen Struktur der API 14 separate API-Aufrufe je Filialedurchgefuhrt werden. Erst nachdem die Anzahl der Lokalitaten fur jedes als relevantidenti_zierte Kennzeichen ermittelt wurde, kann der _nale Datensatz erzeugt werdenund in die eigentliche SAP HANA Datenbank persistent abgelegt werden, mehr dazuim folgenden Abschnitt. Abbildung 8 zeigt die 14 separaten Aufrufe an die API,der Parameter b reprasentiert hierbei eine Filiale3 und besitzt dementsprechend dieAttribute longitude und latitude, die Langengrad und Breitengrad reprasentieren. Fur jedes Kennzeichen wird die demnach Methode aus Abbildung 7 durchgefuhrt, um dieAnzahl der umliegenden Lokalitaten mit dem Kennzeichen zu ermitteln. Die Ergebnisseder einzelnen Aufrufe werden in lokalen Variablen festgehalten, um sie via Parameteran die Methode aus Abbildung 9 zu ubergeben, die wiederum fur die persistenteSpeicherung zustandig ist und im nachsten Abschnitt erlautert wird.

Abb. 8: Implementierung der Methode, die fur eine Filiale je Kennzeichen einen einzelnen API-Aufruf veranlasst (Screenshot aus der Java-IDE “Eclipse”)
Speicherung der Daten in SAP HANA
Zur Erleichterung der Datenpege gibt es fur SAP HANA einen eigenen JDBC (JavaDatabase Connectivity) Treiber, sodass uber Programmcode eines Java-Programmsmit wenig Aufwand mit einer SAP HANA Datenbank interagiert werden kann. Zudiesem Zweck muss die Datei ngdbc.jar aus der SAP HANA Client Installation indas Java-Projekt eingebunden sein. Die persistente Speicherung der transformiertenDaten aus dem vorangehenden Schritt erfolgt uber den Aufbau einer Verbindungzur SAP HANA Datenbank, woraufhin dann ein INSERT-Statement in SQL-Syntax(unter Berucksichtigung des SAP HANA-eigenen SQL-Dialekts) mit den jeweiligenWerten erzeugt wird und auf Basis der vorher aufgebauten Verbindung ausgefuhrtwird. Der fur diese Schritte notwendige Programmcode ist in Abbildung 9 zu sehen,eine Ubersicht der konstanten Textvariablen fur den Verbindungsaufbau in Abbildung10. Die Methode nimmt fur jedes der 14 relevanten Kennzeichen aus Abbildung 4 einenInteger-Parameter an und fugt sie an die jeweilige Stelle in das SQL-Statement, um dieTabelle aus Abbildung 5 mit einem gultigen und vollstandigen Datensatz zu befullen.Nach erfolgreichem Ausfuhren der Methode – ohne dass eine Ausnahmebehandlungnotwendig wird – ist der Datensatz persistent in SAP HANA gespeichert und kanndort fur die weitere Analyse verwendet werden.
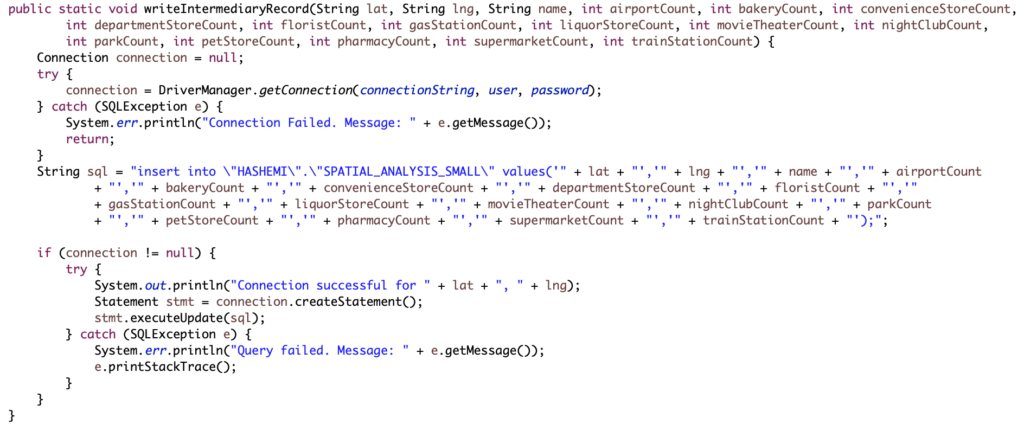
Abb. 9: Implementierung der Methode, die die endgultigen Datensatze persistent in die SAP HANA Datenbank schreibt (Screenshot aus der Java-IDE “Eclipse”)
Recent Comments