Nach vielen weiteren Versuchen mit unterschiedlichen Variablenkombinationen und teils unterschiedlichen Radien fur die Untersuchung, hat sich diese Iteration via trialand- error als erwahnenswert herausgestellt.
Auswahl der Variablen
Die Besonderheit bei der Auswahl der Variablen fur diese Iteration ist, dass hier eine Dichotomisierung der Variablen AIRPORT COUNT und TRAIN STATION durchgefuhrt wird, um sie zu einer kategorischen Variablen zu transformieren, woraus eine binare Skala resultiert. Der von SAP HANA bereitgestellte k-Means-Algorithmus ermoglicht die Nutzung von kategorischen Variablen, allerdings ist eine Berechnung des Silhouettekoeffizienten bei der Nutzung solcher Variablen nicht moglich. Das Resultat der Dichotomisierung ist eine JA/NEIN-Kategorisierung, die uber den in Abbildung 38 gezeigten Code realisiert wird.
Durchfuhrung der Clusteranalyse
Fur die Durchfuhrung der Clusteranalyse ist die Definition einer Zwischentabelle notwendig, die Text-Variablen festhalten kann, andererseits mussen die abgerufenen Werte aus der API so transformiert werden, dass diese den textuellen Daten entsprechen. Es muss allerdings aus statistischer Sicht gepruft werden, ob eine solche Transformation erlaubt ist, ohne die Ergebnisse zu verfalschen, und vor allem, ob sie korrekt vorgenommen wird, was beides im Rahmen dieser Arbeit nicht geschieht. Diese dichotomen Variablen konnen dann mit einer Gewichtung versehen werden, sodass die Existenz eines Flughafens oder einer Bahnstation starker ins Gewicht fallt. Fur diese Iteration wurde fur den Gewichtungsparameter eine Wert von 5 gewahlt, sodass die Existenz eines Flughafens so sehr ins Gewicht fallt, als waren funf Lokalitaten dieser Art gefunden. Hier wird explizit angemerkt, dass dies ein stark ergebnisorientierter Ansatz ist und statistischen Mastaben, die fur aussagekraftige Ergebnisse einer solchen Analyse notwendig sind, vermutlich nicht genugt. Insbesondere Aspekte bezuglich der Standardisierung von Variablen, die fur die ersten Iterationen als gegeben angenommen wurden (siehe Abschnitt 4.1.5 zur Transformation und Gewichtung von Variablen), mussen vor einer Verwendung der Ergebnisse dieser Iteration re-evaluiert werden.
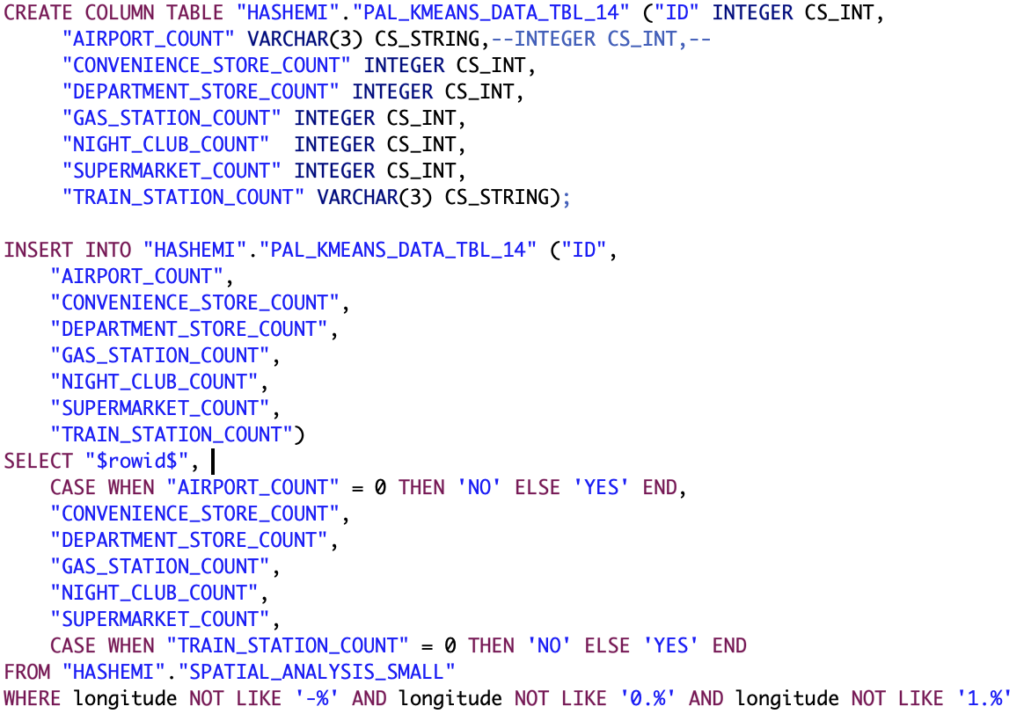
Abb. 38: SQL-Code zur Befullung der Zwischentabelle zur Reprasentation der Datenmatrix fur die funfte Iteration
Aufgrund der stark schwankenden Ergebnisse der Clusteranalyse werden diese direkt in Form der Stabilitatstests vorgestellt, ohne auf die Modellanpassung, inhaltliche Interpretation oder Validitat einzugehen.
Stabilitatstests
Bei dieser Iteration wird die Notwendigkeit mehrerer Durchfuhrungen einer Clusteranalyse besonders deutlich. Wie Abbildung 39 entnommen werden kann, hangt die Clusterlosung enorm von der Auswahl der Startpunkte ab. Hier lassen sich mehrere Durchfuhrungen pro Parameterkombination sehen, die allesamt zu vollig unterschiedlichen Ergebnissen fuhren. Auch eine Prazisierung der Abbruchschwelle und der maximalen Iterationen fuhrt zu keiner sonderlichen Verbesserung bezuglich der Stabilitat. Je nach der Kombination der ersten Clusterzentren lauft das Verfahren auf lokale Minima zu. Die fett gedruckten Werte in dieser Abbildung sind Werte, die sich tendenziell recht haufig wiederholt haben und potentiell globale Minima darstellen konnen. Insbesondere bei Initilaisierungsmethoden, die eine zufallige Auswahl von Startpunkten beinhalten, treten sehr unterschiedliche Losungen auf. Einzig die Initialisierungsmethode der ersten k Observationen bietet naturgema konsistente Ergebnisse. In [Bacher et al., 2010] wird vorgeschlagen, dieselbe Analyse mit
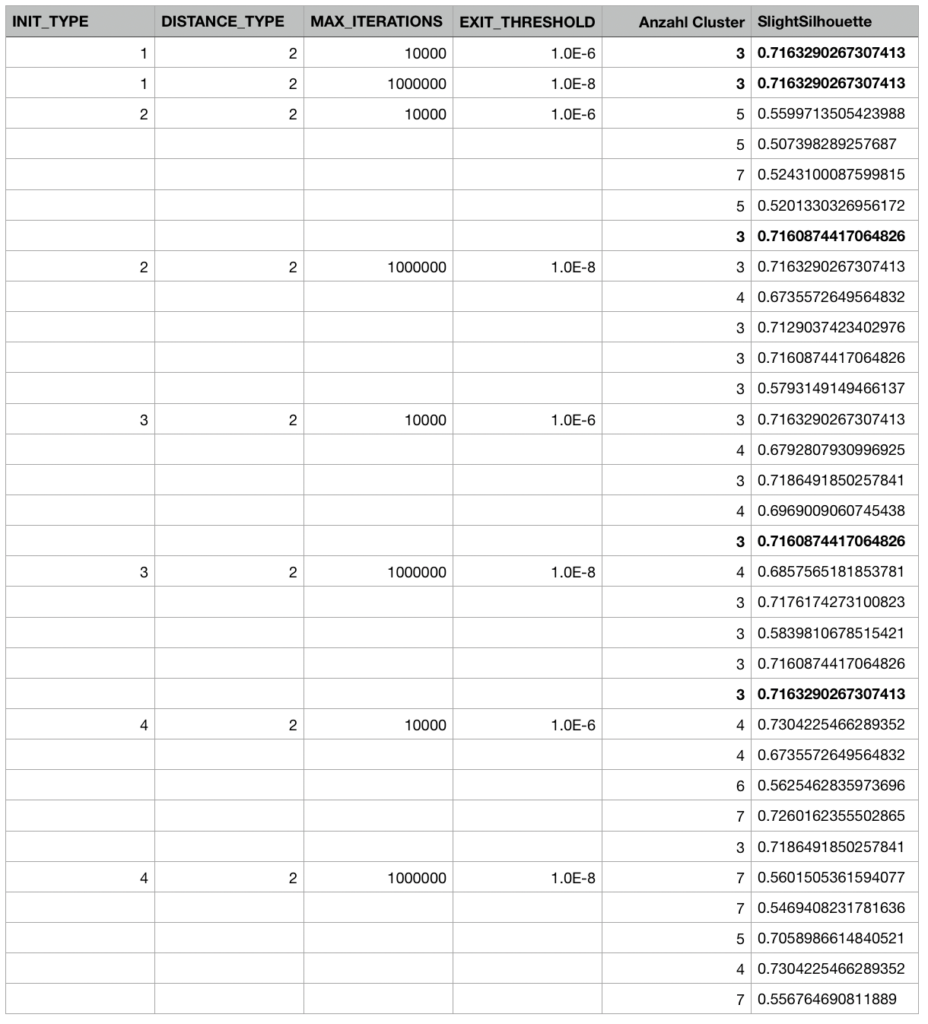
Abb. 39: Verschiedene Parameterkombinationen fur die funfte Iteration der Clusteranalyse und die daraus resultierenden Werte der Slight Silhouette der jeweiligen Clusterlosung
unterschiedlichen Startpunkten wiederholt durchzufuhren, um stabile globale Minima zu finden. Hierfur konnen jedoch je nach Clustergroe jenseits von 1000 Versuchen benotigt sein, was im Rahmen dieser Untersuchung keinen realisierbaren Ansatz darstellt. Dementsprechend wird auf diese Iteration zwar im Hinblick auf die genutzten Variablen und vorgenommenen Gewichtung hingewiesen, allerdings kann sie nicht zu einer stabilen Clusterlosung gefuhrt werden und bietet somit keine Grundlage fur eine standortspezifische Preisdifferenzierung. Hierzu tragt auch die eingangs angesprochene fehlende statistische Fundierung bezuglich der Transformation und Gewichtung der Variablen bei.
Fur diese Iteration wurden keine unterschiedlichen Distanzmae betrachtet, da die Losung bereits fur die euklidischen Distanz als Distanzma sehr instabil zu sein scheint.
In vorangehendem Kapitel wurden die Implementierungsschritte gezeigt, die notwendig sind, um mittels SAP HANA eine Clusteranalyse durchzufuhren. Da ein Teil der verwendeten Daten aus der Google Places API stammt, war im Zuge dessen die Implementierung einer intermediaren Java-Applikation notwendig, die diese Daten abruft und transformiert. Neben der eigentlichen Umsetzung wurden auch die Ergebnisse der Clusteranalyse prasentiert, die aus der Nutzung dieser Geodaten hervorgehen. Die Ergebnisse der Clusteranalyse fuhrten zu einer 2-Cluster-Losung, die zwar formal nicht als ungultig betrachtet werden kann, vor dem Kontext der Zielsetzung, eine Segmentierung als Grundlage fur eine folgende Preisdifferenzierung zu bieten, allerdings als nicht zufriedenstellend bewertet werden konnte. Folglich wurden verschiedene Iterationen der Clusteranalyse mit einer Anpassung des Versuchsaufbaus in Form von Reduktion der Variablen, als auch mit Anpassungen der Parameter durchgefuhrt. Auch in den folgenden Iterationen konnten keine stabilen Losungen mit mehr als zwei Clustern gefunden werden, demnach werden im nachfolgenden Kapitel eine Reihe von moglichen Ursachen und Fehlerquellen dargestellt.
Recent Comments