Eine Herausforderung des k-Means-Algorithmus ist die Notwendigkeit, im Vorfeld die Anzahl der Cluster zu de_nieren. In dem hier behandelt Anwendungsfall ist die Anzahl der Cluster die sich ergeben sollen, wie in vielen anderen Anwendungsfallen auch, jedoch nicht bekannt. Hair et al. beschreiben in [Hair et al., 2018] auf den Seiten
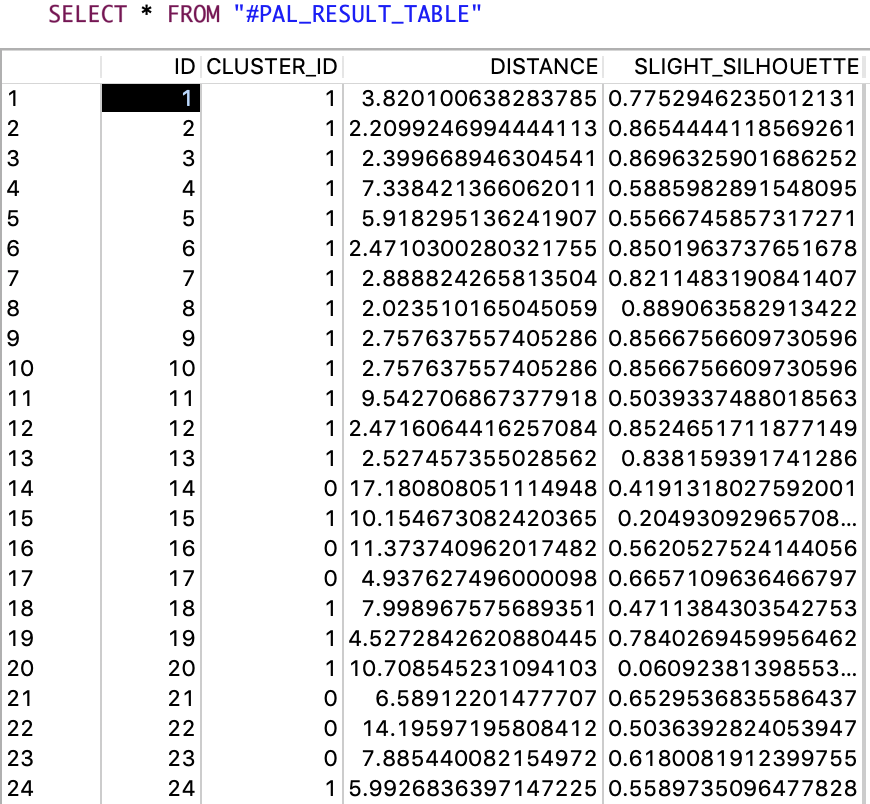
Abb. 21: Auszug der Werte der Ergebnistabelle #PAL RESULTS TABLE der ersten Iteration der Clusteranalyse zur Zuordnung der Beobachtungen zu den ermittelten Clustern (Screenshot aus der Java-IDE “Eclipse” aus der SAP
HANA Modeler Perspective)
222 _. verschiedene solcher Kriterien (fur hierarchische Clusteranalyseverfahren auch stopping rules genannt, vgl. hierzu [Backhaus et al., 2016], S. 496), wahrend Bacher et al. in [Bacher et al., 2010] auf Seiten 306 f. explizit fur das k-Means-Verfahren konkrete Ma_zahlen, wie etwa die erklarte Streuung vorschlagen. Im Rahmen des k- Means-Verfahrens der Predictive Analysis Library gibt es bereits eine Moglichkeit, vor der Clusteranalyse die minimal und maximal erwunschte Anzahl der Cluster festzulegen. Der Algorithmus iteriert damit durch die verschiedenen Moglichkeiten fur die Clusteranzahl k und liefert die Clusterlosung mit der Anzahl, die hinsichtlich der Slight Silhouette am besten abschneidet. Diese Ma_zahl ist eine Modi_kation des Silhouettenkoe_zienten, die im Rahmen der Predictive Analysis Library bereitgestellt wird, und eine Annaherung an den richtigen Silhouettenkoeffzienten darstellt.
Der Silhouettenkoeffzient gibt fur ein Cluster oder eine gesamte Clusterlosung an, inwieweit die Elemente innerhalb eines Clusters zueinander homogen und heterogen zu den Elementen des nachstgelegenen Clusters sind (vgl. [Rousseeuw, 1987]). Das Ergebnis der Silhouette eines Elements ist ein Wert zwischen -1 und 1, wobei ein negativerWert bedeutet, dass das Element eher ins nachstgelegene benachbarte Cluster gehoren wurde, da es eine gro_ere Ahnlichkeit mit den dort angesiedelten Elementen besitzt, als mit den Elementen des aktuellen Clusters. Umgekehrt bedeutet ein positiver
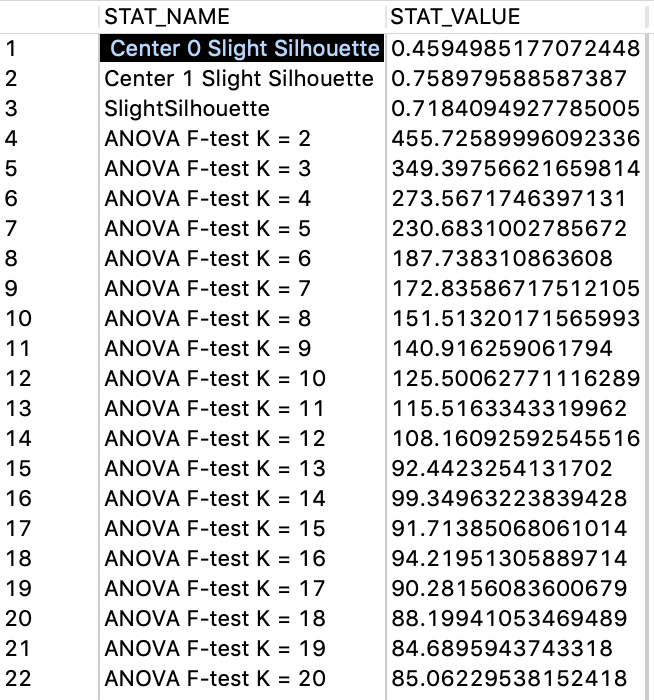
Abb. 23: Die Werte der Ergebnistabelle #PAL STATISTICS TABLE zur Veranschaulichung der Slight Silhouette-Werte der ersten Iteration der Clusteranalyse (Screenshot aus der Java-IDE “Eclipse” aus der SAP HANA Modeler Perspective)
Wert, dass ein Element eine hohe Ahnlichkeit mit den anderen Elementen seines Clusters aufweist, wenn man es mit den Elementen des nachstgelegenen benachbarten Clusters vergleicht, und somit, dass es ‘gut’ klassifiziert wurde. Durch das arithmetische Mittel aller einzelner Silhouetten kann die Silhouette eines gesamten Clusters oder einer ganzen Clusterlosung gebildet werden. Somit bietet der Silhouettenkoeffizient eine Moglichkeit, die Qualitat einer Clusterlosung hinsichtlich der Zuordnung der Elemente zu den jeweiligen Clustern zu bewerten. Da die Berechnung allerdings recht aufwendig ist, gibt es in der PAL mit Slight Silhouette eine performante Abwandlung, die eine vereinfachte Berechnung durchfuhrt. Anstelle des Vergleichs eines Elements mit jedem anderen Element wird nur mit dem Clusterzentrum verglichen, somit wird der eigentliche Silhouettenkoeffizient, der sich aus der jeweiligen Losung ergibt, angenahert. Nach dem Bilden der Cluster ist es moglich, den tatsachlichen Silhouettenkoeffizienten ebenfalls berechnen zu lassen, mehr hierzu in Abschnitt 4.1.13. Fur diese Iteration wird zunachst ein k zwischen 2 und 20 gewahlt, wobei das Spektrum angepasst wird, sollte sich herausstellen, dass womoglich mehr Cluster die naturliche Struktur der Daten besser widerspiegeln.
Recent Comments