Auf Basis der Erkenntnisse aus der vorherigen Iteration und der damit verbundenen, im Untersuchungskontext potentiell nicht validen Ergebnisse, wird erneut eine Clusteranalyse mit einem neuen Variablensatz durchgefuhrt, um zu prufen, ob sich durch Reduktion um eventuell falschlich als relevant identifizierten Variablen eine Losung mit mehr Gruppierungen ergibt. Es werden nicht alle Verfahrensschritte erneut zusammengefasst, da sich vieles uberschneidet. Lediglich die Vorgehensschritte, bei denen Unterschiede zur vorangehenden Iteration existieren, werden erlautert. Falls ein Vorgehensschritt nicht beschrieben wird, ist er identisch zur vorangehenden Iteration oder analog auf diese Iteration anzuwenden. Die Parameter werden genauso gewahlt, wie in der ersten Iteration, Abweichungen hiervon werden bei den Stabilitatstests vorgenommen.
Auswahl der Variablen
Fur diese Iteration werden die Variablen angepasst, und der initiale Variablensatz um FLORIST COUNT, PHARMACY COUNT, LIQUOR STORE COUNT und PARK COUNT gekurzt, sodass nur noch die zehn Variablen aus Abbildung 30 ubrig bleiben. Diese vier eliminierten Variablen wurden im Vergleich zu den restlichen als die

Abb. 30: Kennzeichen der als fur die zweite Iteration relevant fur eine Preisdifferenzierung identizierten Standorttypen
potentiellen Variablen mit der wenigsten Relevanz identifiziert. In einem Supermarkt gibt es im Vergleich zu den anderen betrachteten Lokalitaten wenige Produkte, die eine Uberschneidungsmenge mit den Produkten einer Apotheke oder eines Blumenladens hat. Dementsprechend wurden diese Kennzeichen als erstes eliminiert. Spirituosenladen im Sinne der Google Places API sind in Deutschland relativ selten, verglichen etwa mit der Situation in den Vereinigten Staaten, daher wurden daraufhin Spirituosenladen als Kennzeichen eliminiert. Parks wurden eliminiert, da sie im Vergleich zu den anderen Lokalitaten recht generische Points-of-Interest sind, deren Ein uss auf die Zahlungsbereitschaft von Kunden nicht so eindeutig ist, wie etwa die eines Flughafens. Die verbleibenden Variablen sind im besten Fall die Variablen mit hochster Relevanz fur die Untersuchung, daher wird mit den selben Vorgehensschritten wie in der ersten, ausfuhrlich beschriebenen Iteration, eine Clusteranalyse durchgefuhrt und nur abweichende Aspekte von der ersten Iteration beschrieben.
Durchfuhrung der Clusteranalyse
Zur Durchfuhrung der Clusteranalyse werden analog zur Herangehensweise aus der ersten Iteration neue Zwischentabellen definiert und mit den entsprechenden Daten befullt, da sich die Struktur aufgrund der Ausklammerung einiger Variablen andert. Daraufhin kann die Analyse mit unveranderten Parametern zur ersten Iteration durchgefuhrt werden.
Prufung der Modellanpassung
Diese Losung weist bei Nutzung der euklidischen Distanz und der Initialisierungsmethode der ersten k Observationen eine Slight Silhouette von 0.74 auf und besitzt somit eine gute Modellanpassung. Andere Parameterkombinationen werden in den Stabilitatstests behandelt.
Beschreibung und inhaltliche Interpretation
Auch hier stellt sich eine 2-Cluster-Losung als die beste Losung heraus. Die Attributsauspr agungen der Clusterzentren sind in Abbildung 31 zu sehen, demnach fuhrt diese Iteration zur selben Interpretation in eine Trennung von Filialen mit vielen Lokalitaten und wenigen Lokalitaten:
Cluster 0: Filialen mit einer hohen Anzahl an Konkurrenten und nachfragebeein ussender Points-of-Interest im unmittelbaren Umkreis.
Cluster 1: Filialen mit einer niedrigen Anzahl an Konkurrenten und nachfragebeein- ussender Points-of-Interest im unmittelbaren Umkreis.
Werden die Clusterzentren mit den Clusterzentren der ersten Iteration verglichen, so lasst sich eine enorme Ahnlichkeit feststellen. Die Attributsauspragungen der in beiden Iterationen auftauchenden Attribute weichen zwar leicht ab, allerdings in nur kleinem Ausma, sodass eine sehr ahnliche Zuordnung der Elemente angenommen werden kann und dass die Reduktion der Variablen die Clusterlosung kaum verandert hat.
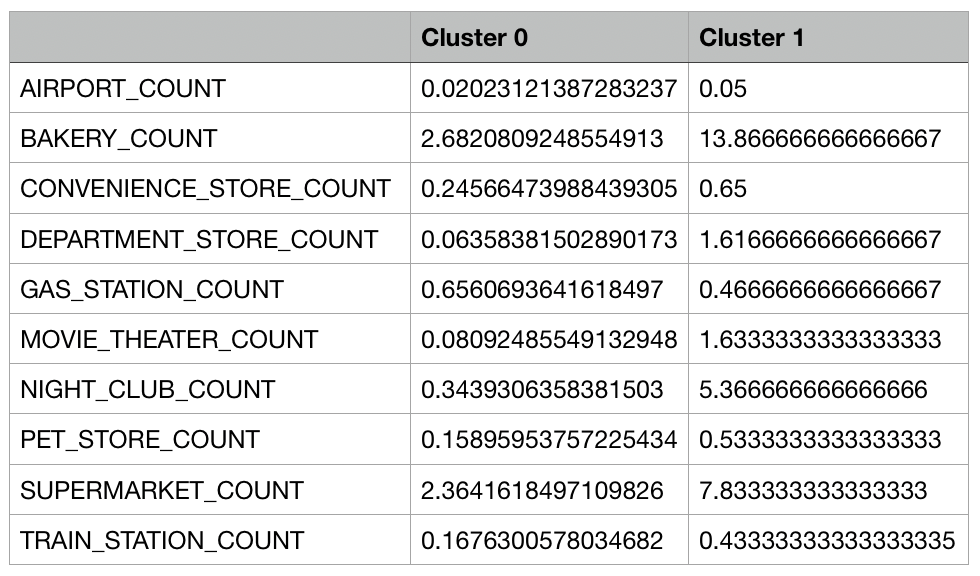
Abb. 31: Vollstandige Ubersicht der Attributsauspragungen der Clusterzentren der zweiten Iteration der Clusteranalyse
Inhaltliche Validitatsprufung
Hier ergeben sich analog zur Clusterlosung aus der ersten Iteration dieselben Bedenken bezuglich der Validitat der Losung. Die Losung entspricht keiner Gruppierung, auf Basis derer sich eine differenzierte Preisdifferenzierung anbietet, da wieder nur zwei Gruppen entstehen.
Stabilitatstests
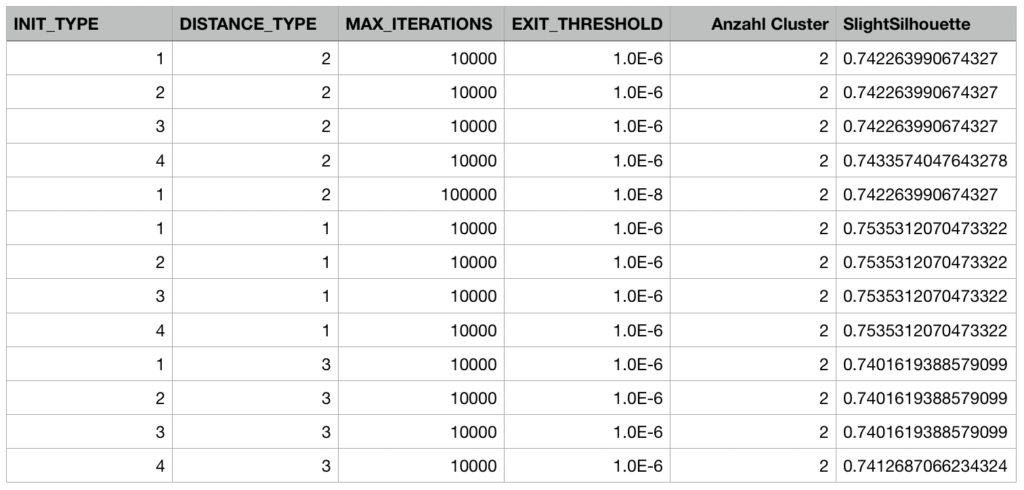
Abb. 32: Verschiedene Parameterkombinationen fur die zweite Iteration der Clusteranalyse und die daraus resultierenden Werte der Slight Silhouette der jeweiligen Clusterlosung
Zudem scheint die Losung ebenfalls uber verschiedene Parameterkombinationen hinweg stabil zu sein. Abbildung 32 zeigt die verschiedenen Slight Silhouette-Werte fur unterschiedliche Parameterkombinationen, auch hier wurden jeweils mehrere Durchfuhrungen vorgenommen, um zu kontrollieren, ob der Wert groeren Schwankungen unterliegt, was nicht der Fall war.
Formale Gultigkeitsprufung
Wird der Silhouettenkoeffizient zur Prufung formaler Kriterien der Gultigkeit berechnet, ergibt sich ein Wert von 0.6673, was bedeutet, dass die Losung aus formaler, statistischer Perspektive ziemlich gut ist.
Recent Comments