Fur die Bildung der Cluster wird in einem vorangehenden Abschnitt der k-Means-Algorithmus ausgewahlt. Im Rahmen der Predictive Analysis Library gibt es eine

zum Festhalten der resultierenden Clusterzuordnungen
vorde_nierte Prozedur, die diesen Algorithmus auf Basis von eingegebenen Parametern und einer ausgewahlten Datenquelle durchfuhrt und die Ergebnisse in mehreren Tabellen ausgibt. Hierbei gibt es verschiedene Moglichkeiten von Parameterkombinationen, wobei im Laufe dieses Abschnitts eine erste Kombination ermittelt und vorgestellt wird. Die Ergebnisse werden dann hinsichtlich der Qualitat der erreichten Clusterlosung bewertet und daraufhin werden die Parameter, sowie die eingehenden Daten in einer neuen Iteration der Analyse angepasst.
Um die Ergebnisse dieser PAL-Prozedur bezuglich des k-Means-Algorithmus nutzen zu konnen, etwa fur die formale Gultigkeitsprufung in Abschnitt 4.1.13, mussen im

zum Festhalten der resultierenden Clusterzentren und der dazugehorigen
Merkmalsauspragungen
Vorfeld physische Tabellen via SQL de_niert werden, die die jeweiligen Ergebnisdatenfesthalten. Hierfur reicht es aus, via SQL lokale, temporare Tabellen zu de_nieren,die bestehen bleiben, solange die Verbindung vom Client aufrechterhalten wird. DieAusfuhrung des k-Means-Algorithmus in der Predictive Analysis Library resultiert ineiner Reihe von Tabellen, die unterschiedlichen Zwecken dienen, die RESULT-Tabelledient etwa der Zuordnung jeder Beobachtung zu einem Cluster, inklusive der Distanzzum jeweiligen Clusterzentrum und der Slight Silhouette. Die De_nition der Tabelleund zugehorigen Felder via SQL ist in Abbildung 13 zu sehen.

Abb. 15: SQL-Code zur Denition der temporaren Tabelle #PAL MODEL TABLE zum Festhalten des resultierenden Clustermodells in einem JSON-String
Um mehrere unterschiedliche Ausfuhrungen der PAL-Prozedur innerhalb derselben Sitzung zu ermoglichen, wird vor der De_nition der temporaren Tabelle ebenjene geloscht, somit kann die gesamte Analyse in einem einzigen SQL-Query mit mehreren SQL-Anweisungen vonstatten gehen. Die CENTERS-Tabelle halt die Merkmalsauspr agungen der einzelnen Clusterzentren fest, also das Mittel der jeweiligen Zahler wie AIRPORT COUNT oder SUPERMARKET COUNT uber alle Elemente des jeweiligen Clusters. Die De_nition dieser Felder ist in Abbildung 14 zu sehen.

Abb. 16: SQL-Code zur De_nition der temporaren Tabelle #PAL STATISTICS TABLE zum Festhalten statistischer Kennzahlen
Die Tabelle MODEL halt das gesamte Cluster-Modell in einem JSON-String fest,dementsprechend kurz ist die De_nition dieser Tabelle in Abbildung 15. In der TabelleSTATISTICS werden statistische Ma_zahlen festgehalten, auch hier ist die De_nitionder Tabelle mit nur zwei Feldern sehr kurz, wie in Abbildung 16 ersichtlich wird.

Abb. 17: SQL-Code zur De_nition der temporaren Tabelle #PAL PLACEHOLDER TABLE zur Reservierung von Platzhalternfur kunftig kommende Ruckgabewerte
k festzulegen. Alternativ kann auch mit Hilfe der Parameter GROUP NUMBER MIN und GROUP NUMBER MAX ein Spektrum von ks festgelegt werden, wobei durch alle spezi_zierten Moglichkeiten fur k iteriert wird und die ‘beste’ Losung ausgewahlt wird, Details hierzu _nden sich im folgenden Abschnitt. Der Parameter DISTANCE LEVEL dient zur Festlegung des zu nutzenden Distanzma_es, etwa die euklidische Distanz oder Minkowski-Distanz. Verschiedene Integer-Werte reprasentieren als Identi_kator die jeweiligen Werte, beispielsweise steht eine 2 in diesem Parameter fur die euklidische Distanz14. Der Parameter INIT TYPE beschreibt die Auswahl der Startpunkte fur Cluster, wobei ebenfalls Integer-Werte die verschiedenen Moglichkeiten reprasentieren, beispielsweise werden mit dem Wert 1 die ersten k Beobachtungen als Startpunkte gewahlt15. Der Parameter MAX ITERATIONS legt fest, wie oft die Schritte des k-Means-Algorithmus maximal iteriert werden, wahrend der Parameter EXIT THRESHOLD festlegt, bei welchem Grenzwert des Qualitatszuwachses der Clusterlosung die Iterationen vorzeitig abgebrochen werden, mehr hierzu im folgenden Abschnitt. Der Parameter THREAD RATIO dient dazu, festzulegen, wieviele Threads der verfugbaren Threads des System verwendet werden sollen, um etwa die Ressourcenauslastung zu limitieren. Ein Wert von 0 bedeutet, dass nur ein einzelner Thread verwendet wird, wahrend ein Wert von 1 bedeutet, dass alle verfugbaren Threads verwendet werden. Dezimalwerte, die sich zwischen 0 und 1 be_nden, beschreiben demnach das einzuhaltende Verhaltnis der zu nutzenden Threads zu den verfugbaren Threads. Ein Wert von 0.5 wurde demnach bedeuten, dass die Halfte aller aktuell verfugbaren Threads fur die Prozedur in Anspruch genommen werden. Der Parameter CATEGORY WEIGHTS beschreibt das Gewicht, welches kategorischen Attributen zugeordnet wird. Daruber hinaus existieren noch weitere Parameter fur diese PALProzedur, die allerdings im Rahmen dieser Untersuchung keine weitere Betrachtung erfordern.
Fur die Durchfuhrung der entsprechenden PAL-Prozedur ist es zudem notwendig, die Tabelle anzugeben, auf Basis derer die Analyse durchgefuhrt werden soll. Da womoglich mehrere Iterationen der Analyse notwendig werden, die teilweise um Variablen gekurzt werden, wird nicht direkt die Tabelle verwendet, die im Rahmen der Java-Applikation mit Datensatzen befullt wird. Vielmehr werden die notwendigen Daten vorher in eine Zwischentabelle kopiert, die die zu untersuchende Datenmatrix darstellt, sodass fur jede Iteration eine eigene Tabelle existiert und die grundlegende Datenbasis mit bereits abgerufenen Geodaten durch eventuelle Streichung oder Transformation von Variablen nicht verandert wird. Anderenfalls ware es zudem fur jede Iteration notwendig, samtliche API-Aufrufe erneut durchzufuhren, was zwar Aktualitat der Daten bedeutet,

Abb. 18: SQLScript-Code zur Festlegung der Parameter und der darauf folgenden Durchfuhrung des k-Means-Algorithmus mit den Parametern der ersten Iteration mit Ausgabe in vorher denierte Tabellen
allerdings im Rahmen dieser prototypischen Untersuchung nicht notwendig ist und nur zusatzliche Ressourcen erfordert. Fur diesen Zweck wird, wie in Abbildung 19 eine einfache Tabelle de_niert und daraufhin direkt mit den Daten aus der Tabelle mit den abgerufenen Umgebungsdaten zu den Filialen befullt, dies ist in Abbildung 20 zu sehen. Da fur die Clusteranalyse uber den k-Means-Algorithmus in der PAL eine ID fur die einzelnen Datensatze notwendig ist, wird fur jeden Datensatz zudem die implizite ID der jeweiligen Zeile abgerufen und ubertragen.
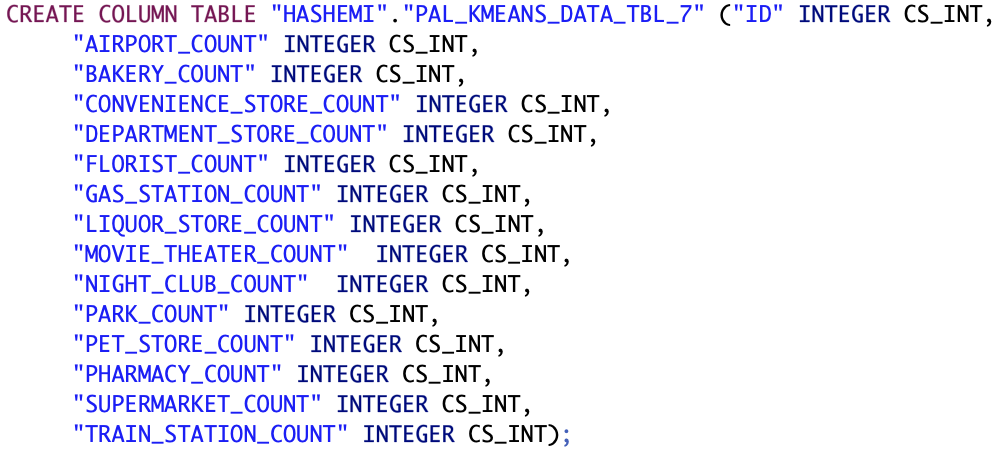
Abb. 19: SQL-Code zur Denition der Zwischentabelle zur Reprasentation der Datenmatrix fur die erste Iteration
Abbildung 18 zeigt den Code, der notwendig ist, um die PAL-Prozedur aufzurufen und mit Hilfe des k-Means-Algorithmus eine Clusteranalyse durchzufuhren, wobei die Ergebnisse in den vorher de_nierten Tabellen festgehalten werden. Als Parameter werden an die Prozedur sowohl die beschriebene Zwischentabelle, als auch die Tabelle mit den Parametern fur den k-Means-Algorithmus ubergeben, sowie die Ergebnistabellen an den jeweils notwendigen Stellen. Das Schlusselwort WITH OVERVIEW dient dazu, dass die Ergebnisse direkt in physische Tabellen ausgegeben werden, was es ermoglicht, die Daten weiter zu verwenden.
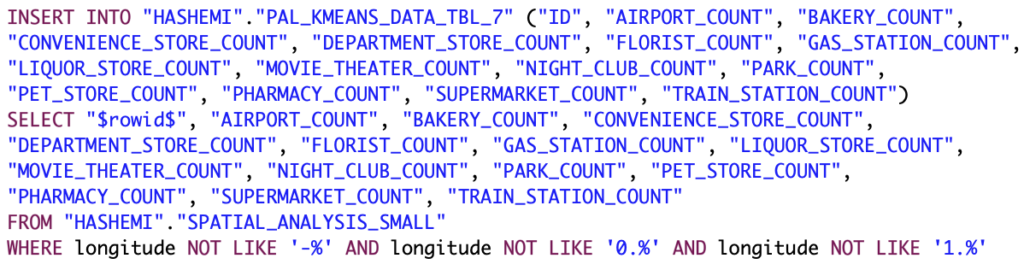
Abb. 20: SQL-Code zum Befullen der Zwischentabelle zur Reprasentation der Datenmatrix fur die erste Iteration
Fur die Durchfuhrung dieser Iteration der Clusteranalyse wird eine Reihe von Parametern gewahlt, die im Folgenden de_niert werden:
INIT TYPE Fur den Parameter INIT TYPE derWert 1 gewahlt, was die Startpunkte der Cluster auf die ersten k Beobachtungen festlegt.
DISTANCE LEVEL Der DISTANCE LEVEL-Parameter ist auf dem Wert 2, welcher die euklidische Distanz reprasentiert. Auf Basis dieser zufalligen Startpunkte und mit Hilfe der euklidischen Distanz als Ahnlichkeitsma_ wird dann das k-Means- Verfahren durchgefuhrt.
GROUP NUMBER MIN Abweichend vom ublichen Verstandnis des k-Means- Algorithmus muss in der Predictive Analysis Library kein _xer Wert fur die Anzahl der Cluster k de_niert werden, sondern es kann ein gewisses Spektrum de_niert werden, indem eine untere und eine obere Grenze fur k festgelegt wird. Der Algorithmus berechnet die Clusterlosungen fur alle ks und gibt die Losung fur das k zuruck, fur welches die Datenmenge am besten reprasentiert wurde, mehr hierzu in Abschnitt 4.1.8. Die untere Grenze dieses Spektrums muss im Rahmen der Predictive Analysis Library mindestens bei einem Wert von 2 liegen und wird uber den Parameter GROUP NUMBER MIN gesetzt.
GROUP NUMBER MAX Die obere Grenze wird fur diese Iteration bei einer Anzahl von 20 Clustern gewahlt, da eine gro_ere Anzahl an Gruppen unwahrscheinlich scheint. Dies geschieht uber den Parameter GROUP NUMBER MAX.
CATEGORY WEIGHTS Die Gewichtung der Kategorien spielt fur diese Iteration keine Rolle, da keine kategorischen Variablen mit in die Analyse einbezogen wurden. Der Parameter CATEGORY WEIGHTS muss demnach in dieser Iteration nicht auftauchen, _ndet allerdings zu Erklarungszwecken in dieser Ubersicht Platz.
THREAD RATIO Der Parameter THREAD RATIO steht auf 0.5, um eine schnellere Analyse zu ermoglichen, als der Standardwert es zulassen wurde, ohne dabei das System vollends auszulasten.
MAX ITERATION Das k-Means-Verfahren im Rahmen der Predictive Analysis Library (zur Unterscheidung des allgemeinen Verfahrens und der im Rahmen der PAL realisierten Implementierung wird zwischen k-Means-Verfahren und k-Means-Algorithmus unterschieden) wird auf Basis von Lloyd’s Algorithmus durchgefuhrt16, welcher aus zwei Schritten besteht. Im ersten Schritt werden alle Objekte dem – je nach verwendetem Distanzma_ – nachsten Cluster zugeordnet, wahrend im zweiten Schritt auf Basis aller Elemente eines Clusters das jeweilige Clusterzentrum neu berechnet wird (vgl. [SAP SE, 2017a]). Durch das neue Clusterzentrum konnen die Objekte ein anderes, nachstes Cluster besitzen, daher wird durch diese beiden Schritte iteriert, bis eine Abbruchbedingung erfullt wird. In diesem Fall wird uber den Parameter MAX ITERATION eine maximale Menge von 10000 Iterationen festgelegt. EXIT THRESHOLD Mit Hilfe des Parameters
EXIT THRESHOLD ein Schwellenwert von 0.000001 festgelegt, das bedeutet, dass dieser Algorithmus so oft iteriert, bis entweder die 10000 Iterationen von MAX ITERATION erreicht sind, oder die Slight Silhouette zwischen zwischen zwei Iterationen um weniger als 0.000001 zunimmt, mehr dazu im nachsten Abschnitt.
Die Ergebnisse der Clusteranalysen, die in den eingangs de_nierten Tabellen festgehalten werden, sind in den Abbildungen 21, 22, 23 und 24 zu sehen und werden in den folgenden Abschnitten naher erlautert. Die Platzhalter-Tabelle ist leer, da sie fur kunftige kommende Erweiterungen der Predictive Analysis Library reserviert ist, und wird demnach nicht aufgefuhrt.
Recent Comments