Sowohl für die Implementierung des Prototyps als auch für die Ausführung des Prototyps muss zuerst Node.js auf dem lokalen Computer installiert werden. Im Rahmen der Arbeit wurde (durch entsprechende Fehlermeldungen von Node.js) festgestellt, dass bei der aktuellen Version Node 10 Inkompatibilitätsprobleme mit dem Node-Package-Manager (kurz: npm) auftreten können. Deswegen sollte zu diesem Zeitpunkt eine der Node 8.x Versionen genutzt werden. Der Autor dieser Arbeit hat Node 8.12.0 genutzt (Node.js Foundation 2018). Wenn Node.js auf dem Computer installiert wurde, kann mit der Kommandozeile in einen leeren Ordner navigiert werden, der das Projekt umfassen soll, und mit dem Befehl npm init –-yes ein Node.js-Projekt erstellt werden. Der npm erstellt dann in dem Projektordner eine JSON-Datei package.json, die von npm für das Abhän-gigkeitsmanagement des Projekts genutzt wird (Brown 2014, S. 20). Die benötigten externen Module bzw. Bibliotheken können jeweils mit npm install hin-zugefügt werden. Für die Programmierung mit Node.js wurde der Editor Atom genutzt.
Im ersten Unterkapitel wird die Implementierung des Frameworks erläutert, in dem die einzelnen Web-Scraper der Wettbewerber eingebettet werden können. Im zweiten Un-terkapitel wird die Implementierung der automatisierten Datenbeschaffung eines exemplarischen Wettbewerbers erläutert.
Erweiterbares Framework
Um die Schichtenarchitektur zu realisieren, wurden in dem Projektordner die drei Un-terordner „Datenbankzugriffsschicht“, „Anwendungsschicht“ und „Praesentations-schicht“ angelegt, in denen wiederum die JavaScript-Dateien datenbankzugriffs-schicht.js, anwendungsschicht.js und praesentationsschicht.js angelegt wurden, die den Quellcode der Schichten enthalten. Außerhalb der Schichtenordner wurde zudem eine JavaScript-Datei main.js erstellt, die den Eintrittspunkt in die Webapplikation darstellt. Sie ruft die Präsentationsschicht, d. h. praesentationsschicht.js, auf. Die Webapplikation bzw. der Web-Server kann in der Kommandozeile mit node main.js gestartet werden. Die Webapplikation nutzt als Web-Server den lokalen Computer, auf dem sie ausgeführt wird. Nach dem Start des Servers kann die Webapplikation mit dem Browser unter lo-calhost:8080 aufgerufen werden. In einer Schichtenarchitektur ruft die Präsentations-schicht die Anwendungsschicht auf, die wiederum die Datenbankzugriffsschicht aufruft. Im Folgenden wird mit der Erläuterung der Datenbankzugriffsschicht begonnen, sodass die von der jeweils höheren Schicht genutzte Schnittstelle transparent nachvollzogen werden kann.
Datenbankzugriffsschicht
Um mit Node.js eine HANA-Datenbanktransaktion auszuführen, kann das externe Modul hdb genutzt werden. Es kann in der Kommandozeile mit npm install hdb zum Projekt hinzugefügt werden (Koser et al. a o. J.). Anschließend kann es mit require(‘hdb‘) an eine Variable gebunden werden (Koser et al. b o. J.). Um im Rahmen der einzelnen Datenbanktransaktionen eine Verbindung zu der Datenbank herzustellen, muss zu-nächst ein Klient-Objekt definiert werden (Koser et al. b o. J.). Um einen Klienten zu erstellen, kann die Funktion createClient() des hdb-Moduls genutzt werden (Koser et al. b o. J.). Der Funktion muss als Parameter ein JavaScript-Objekt übergeben werden, das die Verbindungsdetails als Eigenschaften enthält (Koser et al. b o. J.). Für die in dieser Arbeit genutzte Datenbank müssen der Host, die Instanznummer und der Name der Datenbank sowie die Zugangsdaten angegeben werden. Der entsprechende Quellcode wird in der folgenden Abbildung dargestellt.
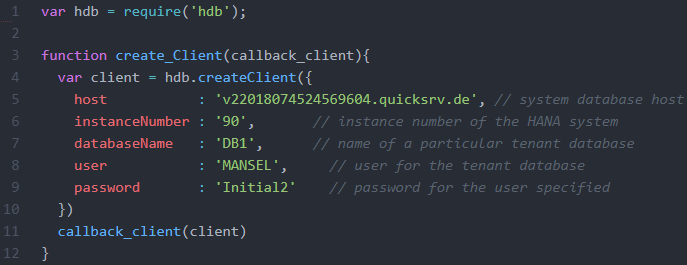
(Github b o. J.)
Da alle Middlewares der Datenbankzugriffsschicht das Klient-Objekt benötigen, wurde eine Funktion definiert, die es erstellt und zurückgibt. Um die asynchrone Architektur von Node.js einzuhalten, muss sie als Callback-Funktion definiert werden. Wie in Kapitel 4.3.2.4 erläutert, definiert der letzte Parameter (Zeile 3) einer Callback-Funktion das zurückzugebende Callback-Objekt. In Zeile 11 wird definiert, dass als Callback das er-stellte Klient-Objekt client zurückgegeben wird.
Auf der Datenbankzugriffsschicht wurden für das Basismanagement und Testing der Webapplikation zunächst drei Middlewares definiert, die das Anlegen der Datenbankta-belle, das Löschen der Datenbanktabelle sowie das Löschen aller Datensätze in der Da-tenbanktabelle realisieren. Die folgende Abbildung zeigt den Quellcode für die Middle-ware, die das Anlegen der Datenbanktabelle umsetzt. Wie in Kapitel 4.3.2.4 erläutert, wird eine exportierbare Middleware-Funktion durch module.exports.<Middlewarename> definiert. Das Callback-Objekt wurde hier callback genannt. Im Rahmen der Mi-ddleware muss zunächst die zuvor erläuterte Callback-Funktion create_Client() aufge-rufen werden, die als Callback das Klient-Objekt zurückgibt, dem hier der Name client zugewiesen wird. Anschließend kann die vordefinierte Callback-Funktion connect() des Klienten aufgerufen werden. Im Rahmen dieser Funktion werden die Datenbankverbin-dung zur HANA initialisiert und die Zugangsdaten durch die HANA überprüft (Koser et al. b o. J.). Bei erfolgreicher Authentifizierung wird eine Datenbank-Session gestartet und der Klient ist mit der HANA verbunden (Koser et al. b o. J.).
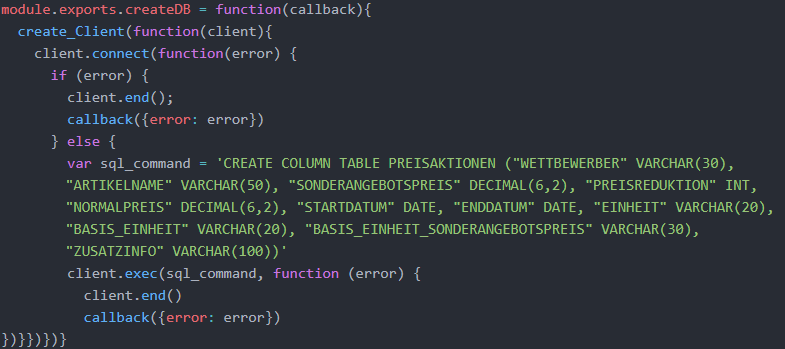
Für die Erstellung der Datenbanktabelle kann die Callback-Funktion exec() des Klienten-Objekts genutzt werden (Koser et al. c o. J.). Sie erwartet als ersten Parameter einen SQL-Befehl als String (Koser et al. c o. J.). Als Callback-Objekt gibt sie ein Error-Objekt zurück. Im Folgenden wird der SQL-Kommando-String zur Erstellung der Datenbankta-belle erklärt. Durch CREATE COLUMN TABLE wird explizit definiert, dass eine spaltenba-sierte Tabelle erzeugt werden soll (Koser und Dotchev o. J.). Als Spalten der Daten-banktabelle werden der Wettbewerber als String mit einer maximalen Länge von 30 Buchstaben (VARCHAR(30)), der Artikelname, der Sonderangebotspreis als Dezimalzahl mit maximal sechs Stellen vor dem Komma und zwei Stellen hinter dem Komma (DE-CIMAL(6,2)), die Höhe der Preisreduktion als Integer, der Normalpreis des Artikels sowie das Startdatum und das Enddatum des Sonderangebots als HANA-Datumstyp (DATE) definiert. Zudem werden die Einheit bzw. Größe des Artikels, die Angabe zu dem Preis pro Basiseinheit und der jeweiligen Basiseinheit sowie weitere Zusatzinformationen als Spalten aufgenommen.
Die Middlewares zum Löschen der Datenbanktabelle und zum Löschen der Datensätze in der Datenbanktabelle stimmen von der Struktur des Quellcodes mit der erläuterten Middleware zur Erstellung der Datenbanktabelle überein. Nur die SQL-Kommando-Strings divergieren. Mit DROP TABLE PREISAKTIONEN und DELETE FROM PREISAKTIO-NEN folgen die Kommandos der Standard-SQL-Syntax.
Im Folgenden wird die selectAll-Middleware erläutert, die alle in der HANA-Datenbank gespeicherten Datensätze zurückgibt. Die Struktur des Quellcodes ist ähnlich zu den vorherigen Middlewares. Ein Unterschied ist allerdings, dass die Callback-Funktion exec() bei einem SELECT-Kommando derart definiert ist, dass sie als Parameter nicht nur ein Error-Objekt zurückgibt, sondern dass als zweiter Parameter die selektierten Datensätze übergeben werden (Koser et al. c o. J.). Dieser Parameter, der im Quellcode rows benannt wurde, ist ein Array von JavaScript-Objekten, wobei jedes Objekt einen Datensatz darstellt (Koser et al. c o. J.). Auf die einzelnen Spalten-Werte eines Daten-satzes kann durch die gleich benannte Eigenschaft des Objekts zugegriffen werden (Ko-ser et al. c o. J.). Der Callback der selectAll-Middleware wurde derart definiert, dass er sowohl das Error-Objekt als auch das Datensatz-Array zurückgibt.
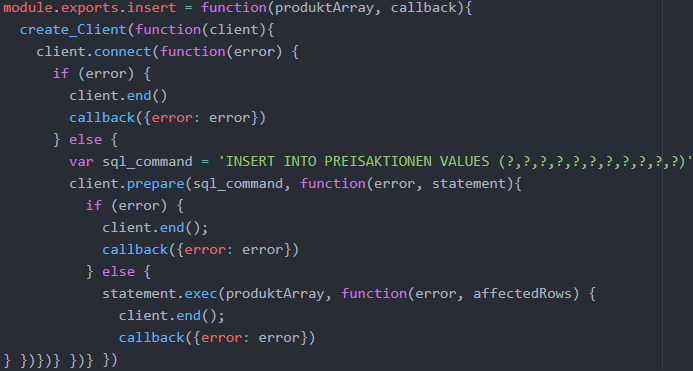
Im Folgenden wird die insert-Middleware erläutert, die von den Web-Scrapern genutzt werden kann, um die extrahierten Daten in die Datenbank zu schreiben. Der Quellcode der Middleware wird in der folgenden Abbildung dargestellt. Die Middleware ist in der Art definiert, dass sie nicht nur einen Callback zurückgibt, sondern dass sie einen Ein-gabeparameter annimmt, der im Quellcode produktArray genannt wurde. Bei diesem Eingabeparameter handelt es sich um die Datensätze, die in die Datenbank geschrieben werden sollen. Um die Datensätze in die Datenbank zu schreiben, muss ein Prepared-Statement genutzt werden (Koser et al. d o. J.).
Im Rahmen eines Prepared-Statements können im SQL-Kommando Platzhalter als Fra-gezeichen definiert werden, die bei der Ausführung des Statements durch ein Ja-vaScript-Array befüllt werden können (Koser et al. d o. J.). Da die Datenbanktabelle PREISAKTIONEN über 11 Spalten verfügt, müssen 11 Platzhalter definiert werden. Ein Prepared-Statement kann mit der Callback-Funktion prepare() des Klient-Objekts er-stellt werden, wobei der zweite Callback-Parameter das erstellte Statement umfasst (Koser et al. d o. J.). Um das Prepared-Statement auszuführen, muss dessen Funktion exec() aufgerufen werden, die als Eingabeparameter die zu schreibenden Datensätze erwartet. Der Eingabeparameter muss ein Array von Arrays sein, wobei die einzelnen inneren Arrays jeweils einen Datensatz repräsentieren. Die inneren Arrays müssen je-weils 11 Elemente aufweisen, weil 11 Platzhalter im Prepared-Statement definiert wur-den. Das erste Element des Arrays befüllt den ersten Platzhalter des Prepared-State-ments und so weiter. Die Callback-Funktion von exec() gibt ein Error-Objekt und ein Integer zurück, der die Anzahl der geschriebenen Datensätze angibt (Koser et al. d o. J.).
Im Folgenden wird die selectStartdatenWhereWettbewerber-Middleware erläutert, die von den Web-Scrapern genutzt werden kann, um zu überprüfen, ob eine bestimmte Preisaktion eines bestimmten Wettbewerbers bereits gescrapt wurde. Um zu überprü-fen, ob die Daten einer bestimmten Preisaktion eines Wettbewerbers bereits gescrapt wurden, kann abgefragt werden, ob das Startdatum dieser Preisaktion für diesen Wett-bewerber bereits in der Datenbank vorhanden ist. Die Middleware erwartet als Eingabe-parameter den entsprechenden Wettbewerber, der in der WHERE-Klausel der SELECT-Abfrage verwendet wird.
Das Startdatum selbst wird hier nicht an die Datenbanktransaktion weitergegeben, weil im Rahmen eines Web-Scrapers mehrere Ressourcen (URLs) einer Webseite gescrapt werden, und in diesem Fall nicht mehrere einzelne Datenbanktransaktionen erfolgen sollen. Im Rahmen des SQL-Statements wird allerdings DISTINCT für die Startdaten genutzt, sodass alle Duplikate für die Spalte Startdatum entfernt werden, und jede Preisaktion nur durch einen Eintrag repräsentiert wird. Auf diese Weise wird die Perfor-manz der HANA für aufwändige Datenbankaufgaben ausgenutzt, und der Aufwand für die Überprüfung der Existenz der Startdaten im Rahmen der Anwendungslogik fällt ge-ring aus. Der Wettbewerber muss als Eingabeparameter der exec()-Funktion als [wett-bewerber] angegeben werden, da auch ein Array erwartet wird, wenn nur ein einzelner Platzhalter existiert (Koser et al. d o. J.). Der Quellcode der Middleware wird in der folgenden Abbildung dargestellt.
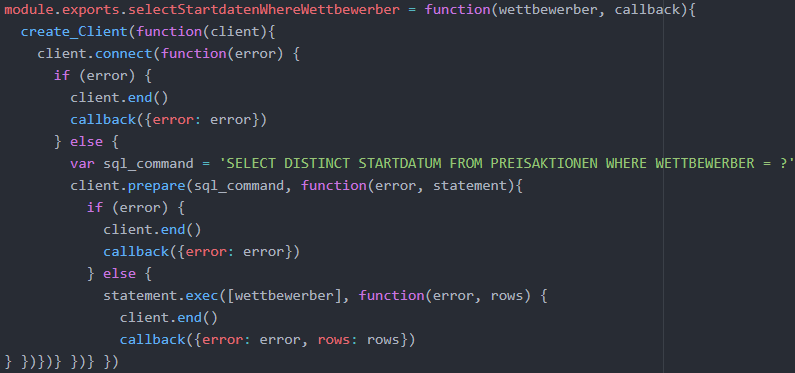
Anwendungsschicht
Im Folgenden wird die Anwendungsschicht des Frameworks erläutert. Zu Beginn müs-sen die im Rahmen der Anwendungsschicht benötigten Module importiert werden. Die folgende Abbildung zeigt die Importe. Zunächst wird das in dieser Arbeit definierte Mo-dul der Datenbankzugriffsschicht importiert, sodass die dort definierten Middlewares in der Anwendungsschicht genutzt werden können. Ferner wird für die Web-Scraper das externe Modul request benötigt. Mit diesem Modul können im Rahmen von Node.js-Applikationen HTTP-Anfragen an andere Webseiten realisiert werden (Rodgers o. J.). Das Modul zeichnet sich durch seine besonders einfache Nutzung aus (Rodgers o. J.).

Des Weiteren wird für das Web-Scraping ein HTML-Parser benötigt. Es wurde sich für das Node.js-Modul cheerio entschieden, weil es explizit für die serverseitige Program-mierung geeignet ist, besonders schnell, flexibel und leichtgewichtig ist, und angemes-sen dokumentiert ist (Böhm und Mueller o. J.). Zuletzt wird das Modul console impor-tiert, das die Anzeige von Nachrichten auf der Kommandozeile während der Ausführung der Webapplikation ermöglicht. Diese Funktionalität wird im Rahmen des beispielhaften Web-Scrapers genutzt, um potenzielle Fehlermeldungen der asynchron laufenden Scra-ping-Prozesse anzeigen zu können.
In der folgenden Abbildung wird dargestellt, wie die Anwendungsschicht des Frame-works aussieht. Für die einzelnen Web-Scraper werden einzelne Middlewares angelegt, die von der Präsentationsschicht aufgerufen bzw. gestartet werden können. In der Ab-bildung ist die Middleware scraper_aldi_nord dargestellt, wobei die Logik der Callback-Funktion hier minimiert ist, weil nur die Architektur des Prototyps erläutert werden soll.
Zudem wurden Middlewares erstellt, die von der Präsentationslogik aufgerufen werden, um die Einträge aus der Datenbank zu lesen, eine neue Datenbanktabelle zu erstellen, die Datenbanktabelle zu löschen und um die Datensätze in der Datenbank zu löschen. Im Gegensatz zur umfangreichen Anwendungslogik der Web-Scraper besteht die An-wendungslogik dieser Middlewares nur darin, die entsprechenden Middlewares der Da-tenbankzugriffsschicht aufzurufen und das zurückgegebene Callback-Objekt an die Prä-sentationsschicht weiterzuleiten. Da die Struktur dieser Middlewares gleich ist, wird nur die selectAll-Middleware in der Abbildung dargestellt, während die Logik der anderen Middlewares minimiert wurde.
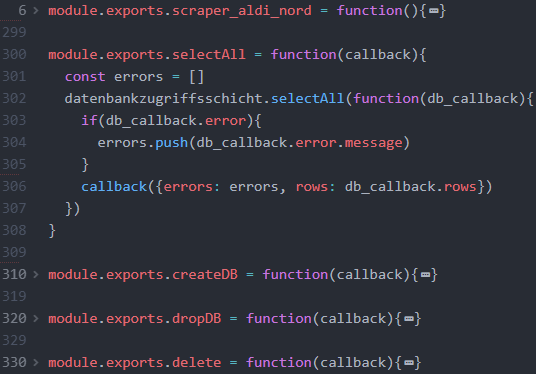
Es ist denkbar, dass die Anwendungsschicht-Middlewares später in der Art verändert werden, dass mehrere Fehlermeldungen aufgefangen und an die Präsentationsschicht weitergegeben werden müssen. Um in diesem Fall die Error-Management-Architektur der Web-Applikation nicht aufwändig warten zu müssen, wird in den Anwendungs-schicht-Middlewares jeweils ein Error-Array erstellt, an das mehrere Fehlermeldungen gepusht werden können, obwohl zu diesem Zeitpunkt nur ein Datenbank-Error existie-ren kann.
Präsentationsschicht
Wie die Module Express, Express-Handlebars und Body-Parser importiert und in die Mi-ddleware-Pipeline eingefügt werden, wurde in Kapitel 4.3.2.3 erläutert. Auf diesen Quellcode wird hier deswegen nicht wiederholt eingegangen. Durch den Code ex-press.static(‘public’) wird der Express-Applikation mitgeteilt, in welchem Ordner stati-sche Dateien des Projekts definiert sind (Expressjs o. J.). Hier wurde als statische Datei ein CSS-Dokument definiert, das einige Style-Regeln für die Navigationsleiste der Webapplikation definiert. CSS wird benötigt, da Navigationsleisten als Standard-HTML-Liste definiert werden, die erst durch Style-Regeln zu einer typischen Navigationsleiste wird (W3Schools g o. J.). Da CSS aber kein zentraler Aspekt dieser Arbeit ist, wird das CSS-Dokument hier nicht explizit erläutert.
Im Folgenden wird das Standardlayout (main_layout.hbs) der Webapplikation erläutert. Wie in den Handlebars-Grundlagen erläutert, kann es als gemeinsames Template aller Views verstanden werden, d. h. alle Views sind in es eingebettet (Brown 2014, S. 74). Der Code des Standardlayouts wird in der folgenden Abbildung dargestellt.
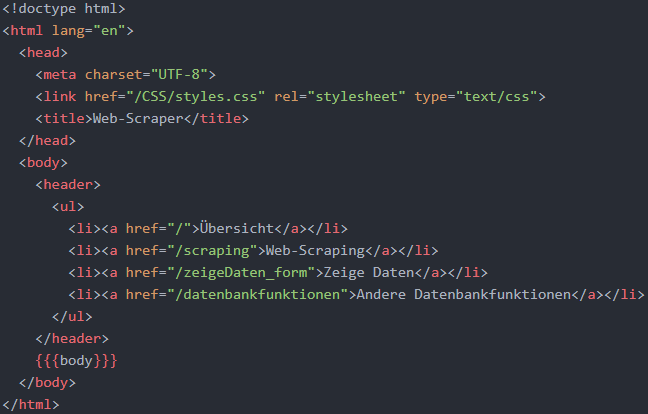
In dem Head des HTML-Dokuments wird definiert, dass das erwähnte statische CSS-Dokument als Style verwendet werden soll und dass der Titel der Webseite im Browser „Web-Scraper“ ist. Im Body des Dokuments wird die Navigationsleiste definiert. Durch das <ul>-Element wird eine HTML-Liste definiert (W3Schools g o. J.), wobei ul für un-sortierte Liste (engl.: unordered List) steht. Die einzelnen Elemente der Liste werden durch <li>-Elemente definiert (W3Schools g o. J.). Da eine Navigationsleiste eine Liste von Links ist (W3Schools g o. J.), wird in den einzelnen Listenelemente jeweils ein <a>-Element definiert. Das <a>-Element definiert, dass das umgebende Listenelement zu einem Link zu einer anderen URL wird, wobei diese URL in dem href-Attribut des <a>-Elements spezifiziert wird (W3Schools h o. J.). Wird beispielsweise auf den Reiter „Web-Scraping“ geklickt, schickt der Browser des Benutzers eine HTTP-Anfrage an localhost:8080/scraping. Der Platzhalter {{{body}}} definiert schließlich, dass an dieser Stelle die Views eingebettet werden (Brown 2014, S. 75).
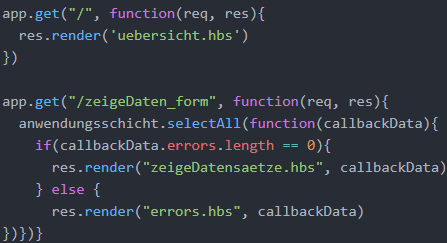
Im Folgenden wird auf die Routing-Middlewares und ihre Views eingegangen. Die fol-gende Abbildung zeigt die Routing-Middlewares der Pfade „/“ und „/zeigeDaten_form“. Der Pfad „/“ fängt die initiale HTTP-Anfrage localhost:8080 an die Webapplikation auf, die keinen Pfad besitzt. Falls eine entsprechende Anfrage vorliegt, wird durch render(‘uebersicht.hbs‘) die View uebersicht.hbs als HTTP-Antwort an den Klienten (Brow-ser) zurückgeschickt. Diese View besteht nur aus Absätzen und einer Überschrift, des-wegen wird die View hier nicht explizit erläutert.
Die zweite Routing-Middleware wird ausgelöst, wenn der Benutzer auf den Reiter „Zeige Daten“ des Standardlayouts klickt, der eine Anfrage an die URL localhost:8080/zeige-Daten_form auslöst. In diesem Fall wird die bereits erläuterte Middleware selectAll der Anwendungsschicht aufgerufen. Als Callback-Objekt callbackData wird der Präsentati-onsschicht ein JavaScript-Objekt zurückgegeben, in dem ein Error-Array errors und die Datensätze der Datenbank als rows gespeichert sind. Es wird anschließend überprüft, ob keine Fehler in das Error-Array gepusht wurden. Falls dies der Fall ist, wird die View zeigeDatensätze.hbs an den Klienten zurückgegeben. In diesem Fall wird auch die Funk-tionalität der Handlebars genutzt, einen Kontext (callbackData) an einen Platzhalter der View weiterzugeben. Die View zur Anzeige der Datensätze kann in Anhang 2 eingesehen werden.
Um die Datensätze darzustellen, wurde die Standard-HTML-Tabelle <table> genutzt. Durch das <th>-Element können die Spaltenüberschriften der Tabelle benannt werden (W3Schools i o. J.). Durch das <td>-Element können die einzelnen Spalten der Tabelle mit Werten befüllt werden (W3Schools i o. J.). Wie bereits erwähnt, wurde der View als Kontext ein JavaScript-Objekt übergeben, das als Eigenschaft rows ein Array von ein-zelnen Datensätzen aufweist, die wiederum JavaScript-Objekte sind. Im Rahmen der Handlebars ist es möglich, dieses Array auszuwerten, indem mit #each eine Schleife über die einzelnen Array-Elemente definiert wird (Brown 2014, S. 72f). Auf die einzel-nen Eigenschaften des aktuellen JavaScript-Objekts der Schleife kann wiederum mit this.eigenschaftsname zugegriffen werden (Brown 2014, S. 72f). Es ist zu beachten, dass die Eigenschaftsnamen case-sensitive sind, deswegen müssen die Eigenschaftsna-men hier, wie die Namen der Datenbankspalten, in großen Buchstaben geschrieben sein.
Falls die if-Abfrage der Routing-Middleware zu dem Ergebnis kommt, dass mindestens ein Fehler in das Error-Array gepusht wurde, wird als HTTP-Antwort die View error.hbs an den Browser geschickt. Diese View umfasst eine each-Schleife über das als Kontext weitergegebene Error-Array.
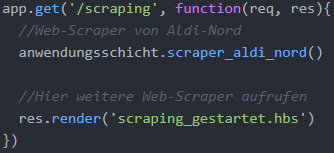
Wenn der Benutzer auf den Reiter „Web-Scraping“ des Standardlayouts klickt, sollen alle definierten Web-Scraper gestartet werden, und somit sämtliche zu diesem Zeitpunkt verfügbare Preisaktionen von den Wettbewerbern extrahiert und in der HANA-Daten-bank gespeichert werden. Dies wird durch den Aufruf der auf der Anwendungsschicht definierten Web-Scraper-Middlewares erreicht. So wird in der folgenden Abbildung die im Rahmen dieser Arbeit implementierte Web-Scraper-Middleware für Aldi-Nord.de auf-gerufen. Falls im Rahmen der erweiterten Webapplikation hier mehrere Web-Scraper gestartet werden, werden sie durch die asynchrone Programmierung der Webapplikation nicht nacheinander ausgeführt, sondern fast gleichzeitig gestartet, da aufwändige Auf-gaben im Rahmen der Web-Scraper an externe Ressource delegiert werden. Da asyn-chrone Prozesse gestartet werden, und nicht bekannt ist, zu welchem Zeitpunkt die Prozesse beendet werden, kann das (Error-)Reporting der Web-Scraper nicht durch eine View geleistet werden. Stattdessen wurde sich dafür entschieden, das Reporting der Web-Scraper mit dem Console-Modul über die Kommandozeile vorzunehmen, was in Kapitel 4.4.2.2 näher erläutert wird. Deshalb wird hier nur eine View zurückgegeben, die erwähnt, dass der Scraping-Prozess gestartet wurde.
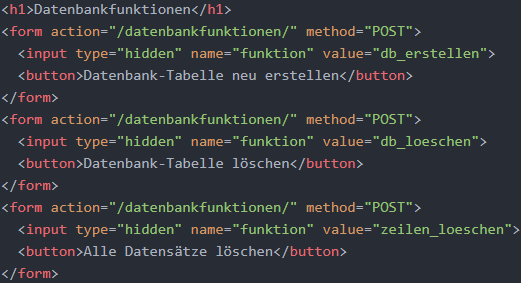
Im Folgenden wird auf die Routing-Middleware eingegangen, die das Management und Testing der Datenbanktabelle ermöglicht. Es wurde die Design-Entscheidung getroffen, diese Datenbankfunktionen nicht jeweils als Reiter in der Navigationsleiste darzustellen, da sie sonst möglicherweise ungewollt ausführt werden könnten, was beispielsweise zum ungewollten Löschen der Datenbanktabelle führen könnte. Stattdessen sollen die Datenbankfunktionen als drei Knöpfe in einer View bzw. Form realisiert werden. Die folgende Abbildung zeigt die Routing-Middleware.

Wenn der Benutzer auf den Reiter „Datenbankfunktionen“ der Navigationsleiste klickt, wird er zur URL „/datenbankfunktionen“ weitergeleitet, und es wird durch die obere Middleware die View datenbankfunktionen.hbs an den Browser zurückgegeben. Diese View umfasst die drei Knöpfe, die die Datenbankfunktionen auslösen sollen. Die View wird in der folgenden Abbildung dargestellt. Um zu unterscheiden, welcher Knopf ge-drückt wurde, wurden sie jeweils in eine eigene Form eingebettet. Das Attribut action der Form legt fest, an welche URL die Form geschickt wird, wenn der Knopf der Form gedrückt wird (Brown 2014, S. 86). Das Attribut method legt hier fest, dass eine POST-HTTP-Anfrage verschickt wird (Brown 2014, S. 86). Um im Rahmen der Routing-Midd-leware, die die POST-Anfrage empfängt, die Logik für die verschiedenen Knöpfe zu dif-ferenzieren, muss in den Forms jeweils ein Parameter definiert werden, der im Body der POST-Anfrage übergeben wird. Mit dem Attribut name kann der Name des Parameters und mit dem Attribut value der Wert des Parameters festgelegt werden (Brown 2014, S. 86). Da dieses Feld der Form nicht im Browser angezeigt werden soll, muss das At-tribut type auf „hidden“ gesetzt werden (Brown 2014, S. 89).
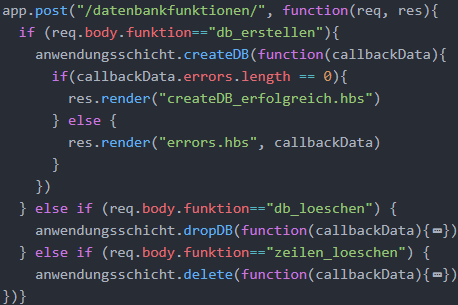
Die folgende Abbildung zeigt die Routing-Middleware, die die POST-Anfragen der Forms empfängt. Da die Body-Parser-Middleware (Kapitel 4.3.2.3) genutzt wird, kann mit req.body.funktion direkt auf den Parameter funktion des Bodys zugegriffen werden. Durch dessen Wert kann die Middleware überprüfen, welcher Knopf gedrückt wurde. Falls beispielsweise der Knopf zur Erstellung der Datenbanktabelle gedrückt wurde, wird die Middleware createDB() der Anwendungsschicht aufgerufen. Falls kein Fehler in das an die Präsentationsschicht zurückgegebene Error-Array gepusht wurde, wird eine View an den Browser zurückgeschickt, die den Benutzer über eine erfolgreiche Ausführung informiert. Andernfalls werden die Fehler in der error.hbs-View angezeigt. Das Error-Handling für die anderen Datenbankfunktionen wurde in der Abbildung ausgeblendet, da es die gleiche Struktur aufweist.
Exemplarischer Web-Scraper
Im Folgenden wird der exemplarische Web-Scraper erläutert. Im ersten Unterkapitel wird diskutiert, welcher Wettbewerber sich für die exemplarische Implementierung eig-net. Im zweiten Unterkapitel wird die Implementierung des Web-Scrapers erläutert.
Selektion eines Wettbewerbers
Um den Lebensmitteleinzelhändler auszuwählen, dessen Preisinformationen gescrapt werden sollen, wurden in einem ersten Schritt die Webseiten der Wettbewerber analy-siert. Im Rahmen dieser Arbeit wird die dynamische Preissetzung für die physischen Filialen diskutiert, weshalb der Onlinehandel von Lebensmitteln nicht betrachtet wird. Es wurde folglich auf den Webseiten der Lebensmitteleinzelhändler nach der Ausschrei-bung der aktuellen und zukünftigen Sonderangebote in den physischen Filialen gesucht, aus denen, wie bereits diskutiert, auch die Normalpreise der Artikel abgeleitet werden können.
Es wurde festgestellt, dass bei Aldi-Nord und Penny dieselben Sonderangebotspreise für alle Filialen zentral ausgeschrieben werden, während bei EDEKA, REWE und Lidl erst eine konkrete Filiale ausgewählt werden muss, um die entsprechenden Sonderangebote einzusehen. Bei EDEKA, REWE und Lidl können die Sonderangebote somit zwischen den individuellen Filialen divergieren. Es wurde sich entschieden, in dieser Arbeit einen Wett-bewerber mit einer zentralen Ausschreibung zu wählen, weil sich auf diese Weise der hohe Analyse- und Vergleichsaufwand gespart werden konnte, die Preisinformationen der einzelnen Filialen zu einem Gesamtbild über einen Wettbewerber zu aggregieren, was einen Mehraufwand dargestellt hätte, der nicht direkt zu der Beantwortung der technischen Fragestellung beigetragen hätte.
Sowohl auf Aldi-Nord.de als auch auf Penny.de werden jeden Sonntag die Preisaktionen des kommenden Montags und Freitags als zwei separate URLs bzw. Ressourcen verfüg-bar gemacht. Diese URLs existieren bis zum kommenden Samstag, und werden am kommenden Sonntag gelöscht, wenn die Preisaktionen für den nächsten Montag und Freitag angekündigt werden. Die Webseiten unterscheiden sich allerdings dadurch, dass auf Penny.de die Preisaktionen für Montag und Freitag immer auf der gleichen URL an-geboten werden, während auf Aldi-Nord.de jede Preisaktion eine individuelle URL hat, da sie das Datum der Preisaktion beinhaltet. So hat die URL für die Preisaktion von Montag, den 19. August, das Format https://www.aldi-nord.de/angebote/aktion-mo-19-08.html.
Das Web-Scraping von Aldi-Nord ist somit aus technischer Sicht komplexer, da zuerst ein Programm geschrieben werden muss, das ermittelt, für welchen Montag und Freitag (Datum) zu einem bestimmten Zeitpunkt Preisaktionen vorliegen, und das anschließend die gültigen URLs zusammenbaut. Da im Rahmen dieser Arbeit das grundsätzliche tech-nische Vorgehen zur Implementierung von Web-Scrapern erarbeitet und getestet wer-den soll, sodass anschließend die Web-Scraper für weitere Wettbewerber implementiert werden können, soll hier der komplexere Web-Scraper für Aldi-Nord implementiert wer-den.
Implementierung des Web-Scrapers
Wie bereits erwähnt, müssen in einem ersten Schritt der Montag und der Freitag iden-tifiziert werden, für die aktuell Preisaktionen vorliegen. Dazu kann das aktuelle Datum abgefragt werden, und anschließend überprüft werden, um was für einen Wochentag es sich bei dem aktuellen Datum handelt. Wenn es sich um einen Sonntag handelt, liegt der aktuell verfügbare Montag einen Tag und der aktuell verfügbare Freitag fünf Tage in der Zukunft. Ist hingegen Samstag, liegt der verfügbare Freitag einen Tag und der verfügbare Montag fünf Tage in der Vergangenheit. Um diese Logik zu implementieren, können das JavaScript-Standardobjekt Date und seine Methoden genutzt werden (W3Schools j o. J.).
Ein neues Datum-Objekt kann mit new Date() erzeugt werden, wobei new Date() das aktuelle Datum zurückgibt (W3Schools j o. J.). Die Methode getDate() gibt den Tag des Monats eines bestehenden Datum-Objekts als Integer (1-31) zurück. Die Methode get-Month() gibt den Monat eines bestehenden Datum-Objekts als Integer (0-11) zurück. Die Methode getFullYear() gibt das Jahr eines bestehenden Datum-Objekts als Integer zurück. Die Methode getDay() gibt den Wochentag eines Datum-Objekts als Integer (0-6) zurück, wobei 0 dem Wochentag Sonntag, 1 dem Wochentag Montag, und 6 dem Wochentag Samstag entspricht. Um ein Datum-Objekt auf ein neues Datum zu setzen, können die Methoden setDate(), setMonth() und setFullYear() verwendet werden.
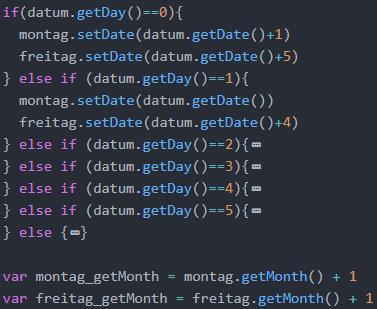
Die folgende Abbildung zeigt den benötigten Code. Zunächst werden drei neue Date-Objekte angelegt. Die Variable datum soll als Referenz für das aktuelle Datum fungieren, während die Variablen montag und freitag auf die Daten gesetzt werden sollen, die aktuell gescrapt werden können. Ist aktuell Sonntag (getDay()==0), liegt der verfüg-bare Montag einen Tag in der Zukunft, deswegen wird die Variable montag mit setDate() auf datum.getDate()+1 gesetzt. Es entstehen dabei keine Probleme, wenn durch die Addition eines Tages in einen neuen Monat oder in ein neues Jahr gesprungen wird (W3Schools j o. J.). Im Falle eines Sonntags muss die Variable freitag auf datum.get-Date()+5 gesetzt werden. Durch die if-Abfrage werden für alle potenziellen Wochentage der verfügbare Montag und Freitag gesetzt.
Ein Problem mit dem Datum-Objekt ist, dass der Integer für die Monate bei 0 beginnt, und somit beispielsweise der Monat Januar dem Integer 0, anstatt 1, entspricht. Sowohl bei der Bildung der URLs als auch bei der Speicherung der Daten in der Datenbank wird hingegen erwartet, dass der String für Januar 1 ist. Um dieses Problem zu umgehen, werden hier für die Monate zwei Variablen montag_getMonth und freitag_getMonth ein-geführt, die anstatt von montag.getMonth() und freitag.getMonth() verwendet werden können. Ihnen beiden wird jeweils getMonth()+1 zugewiesen, sodass sie den korrekten Integer bzw. String enthalten.
Im Rahmen des automatisierten Prozesses soll überprüft werden, ob die Preisaktionen des verfügbaren Montags und Freitags bereits in der Datenbank gespeichert wurden. Die bereits erläuterte Middleware selectStartdatenWhereWettbewerber() gibt die in der Datenbank vorhandenen Startdaten für einen bestimmten Wettbewerber zurück, der als Eingabeparameter der Middleware übergeben wird. Falls der Callback einen Datenbank-Error enthält, wird diese Fehlermeldung auf der Kommandozeile ausgegeben und der Scraping-Prozess abgebrochen. Die Datensätze der Datenbank werden als Array von JavaScript-Objekten zurückgegeben, wobei jedes JavaScript-Objekt einem Datensatz entspricht. Das Array wird als Objekt-Eigenschaft rows im Callback-Objekt db_callback gespeichert. Um zu überprüfen, ob ein Startdatum in der Datenbank vorhanden ist, wurde eine for-Schleife über die Elemente des Arrays von Startdaten definiert. Der Code wird in der folgenden Abbildung dargestellt.
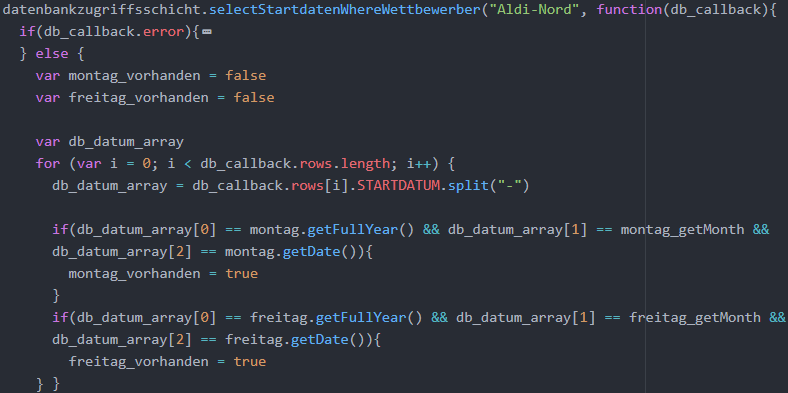
In der HANA-Datenbank sind Datumsangaben (DATES) als String der Form ‘JJJJ-MM-TT‘ gespeichert. Um den Tag, den Monat und das Jahr aus diesem String auszulesen, kann die JavaScript-Standardmethode String.split(“-“) verwendet werden. Sie zerlegt einen String in ein Array von Substrings, wobei der Parameter-String “-“ das Zeichen angibt, das für die Trennung genutzt werden soll. Das Array db_datum_array umfasst folglich drei Elemente, beginnend mit dem Jahres-String ‘JJJJ‘. Anschließend kann für jedes Startdatum der for-Schleife das Jahr db_datum_array[0], der Monat db_datum_ar-ray[1] und der Tag db_datum_array[2] mit dem Jahr, Monat und Tag des Montags und Freitags verglichen werden. Falls der Montag bzw. Freitag in der Datenbank vorhanden ist, wird montag_vorhanden bzw. freitag_vorhanden auf true gesetzt.
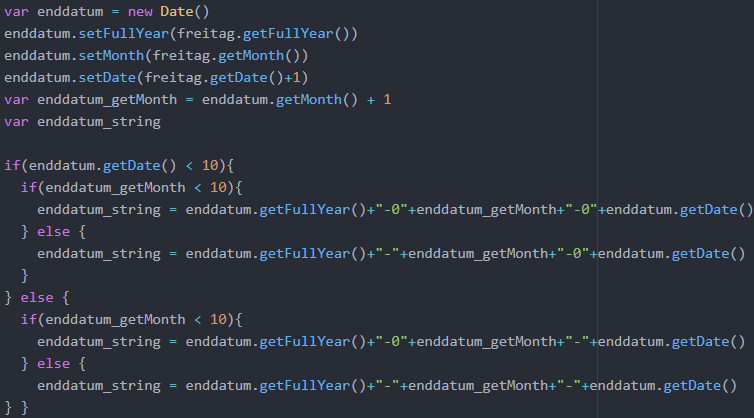
Bei den Freitags-Preisaktionen von Aldi-Nord wird das Ende der Preisaktion nicht explizit in dem HTML-Dokument genannt, d. h. es kann nicht gescrapt werden. Allerdings gelten die Freitags-Preisaktionen und Montags-Preisaktionen immer bis zum kommenden Samstag. Da die Enddaten der Preisaktionen in der Datenbank gespeichert werden sol-len, muss der Datum-String des Samstags folglich unabhängig vom Scraping generiert werden. Die folgende Abbildung zeigt den benötigten Code. Es wird eine neue Datums-variable enddatum angelegt, die auf das Datum des Freitags, plus einen Tag, gesetzt wird. Anschließend soll ein Datum-String für den Samstag erzeugt werden, der in der Datenbank gespeichert werden kann. Der String muss die Form ‘JJJJ-MM-TT‘ haben, d. h. vor einem einstelligen Tag bzw. Monat muss eine 0 eingefügt werden. Wenn bei-spielsweise sowohl der Tag als auch der Monat kleiner als 10 sind, muss vor den Inte-gern enddatum.getDate() und enddatum_getMonth eine „0“ eingefügt werden. Es er-geben sich vier Möglichkeiten, die durch die if-Abfrage unterschieden werden. Die Er-stellung des Enddatums wird außerhalb der Web-Scraper-Programmteile vorgenommen, weil es sich bei den Web-Scrapern um zwei asynchrone, unabhängige Programm-teile handelt, und das Enddatum einmal definiert und dann in beiden Web-Scrapern genutzt werden soll.
Anschließend werden die beiden asynchronen Web-Scraper-Prozesse gestartet. Obwohl sie im Code hintereinander stehen, werden sie aufgrund der asynchronen Architektur von Node.js fast gleichzeitig gestartet, da das Senden der HTTP-Anfrage im Rahmen des ersten Web-Scrapers an eine externe Ressource delegiert wird, und direkt mit dem Code des zweiten Web-Scrapers fortgefahren wird.
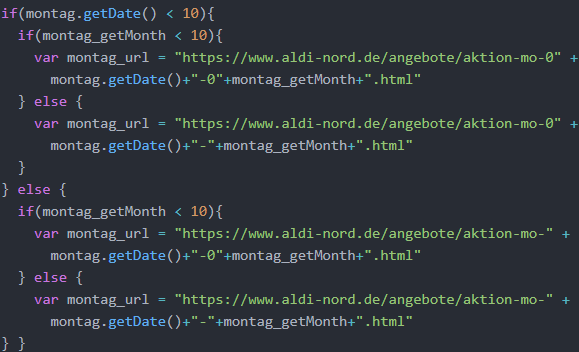
Im Folgenden wird der Montag-Web-Scraper im Detail nachvollzogen. Der Web-Scraper soll nur ausgeführt werden, wenn diese Preisaktion nicht bereits in der Datenbank vor-handen ist. Falls montag_vorhanden wahr ist, wird deswegen eine entsprechende Mel-dung auf der Kommandozeile ausgegeben und der Web-Scraper nicht ausgeführt. Ist dies nicht der Fall, muss in einem ersten Schritt die URL gebaut werden, mit der die Montags-Preisaktion aufgerufen werden kann. Bezüglich der URL mit der Form https://www.aldi-nord.de/angebote/aktion-mo-19-08.html ist zu beachten, dass vor ei-nem einstelligen Tag bzw. Monat in der URL eine 0 steht. Wenn beispielsweise sowohl der Tag als auch der Monat kleiner als 10 sind, muss in dem URL-String vor den Integern montag.getDate() und montag_getMonth eine „0“ eingefügt werden. Es ergeben sich vier Möglichkeiten, die durch die if-Abfrage unterschieden werden. Der Quellcode wird in der folgenden Abbildung dargestellt.
Anschließend muss die HTTP-Anfrage zu den Montags-Preisaktionen ausgeführt werden. Dazu wird das bereits erwähnte externe Modul ‘request‘ verwendet, das an die Kon-stante request gebunden wurde. Das Modul exportiert eine Funktion, die als Eingabe-parameter die Webseite erwartet, die aufgerufen werden soll (Rogers o. J.). Die Call-back-Funktion ist derart definiert, dass der erste Parameter das Error-Objekt, der zweite Parameter das Response-Objekt (Start-Line) und der dritte Parameter den Body der HTTP-Antwort referenziert (Rogers o. J.). Die folgende Abbildung zeigt den Quellcode. Da es sich in diesem Fall bei dem Body der HTTP-Antwort um ein HTML-Dokument han-delt, wurde der dritte Parameter html benannt.

Falls ein Fehler bei dem Aufruf der Webseite aufgetreten ist, wird eine entsprechende Fehlermeldung in der Kommandozeile anzeigt. Andernfalls wird mit dem Web-Scraping fortgefahren. Als nächster Schritt muss das HTML-Dokuments geparst werden. Für das Parsing wird das bereits erwähnte Modul cheerio genutzt. Das Parsing wird von der Funktion cheerio.load() durchgeführt, die als Eingabeparameter das HTML-Dokument erwartet (Böhm und Mueller o. J.). Das Ergebnis dieser Funktion umfasst ein API, das auf dem aus dem HTML-Dokument erstellten Document Object Model (DOM) agiert (Böhm und Mueller o. J.). Mit API sind hier Funktionen, wie beispielsweise Selektoren auf dem DOM, gemeint (Böhm und Mueller o. J.). Das API wird hier der Konstante $ zugewiesen. Die folgende Abbildung zeigt den Code.

Um die relevanten Informationen des HTML-Dokuments zu extrahieren, musste zu-nächst das HTML-Dokument analysiert werden. Das Dokument ist durch mehrere <div>-Elemente strukturiert. Die <div>-Elemente werden genutzt, um ein HTML-Doku-ment in Abschnitte zu unterteilen. Eine Übersicht über das HTML-Dokument kann in Anhang 3 eingesehen werden. Die relevanten Preisinformationen stehen in dem Doku-ment in den <div>-Elementen, denen als Klassen-Attribut „col-xs-6 col-sm-4 col-lg-3“ zugewiesen wurde. Jedes dieser <div>-Elemente umfasst eine einzelne Preisaktion, was durch die Markierung in der Abbildung zu sehen ist. Es ist anzumerken, dass alle Preis-aktionen über mehrere <div>-Elemente mit dem Klassen-Attribut „tiles parbase“ ver-teilt sind.

Abbildung 58 zeigt die Struktur innerhalb eines einzelnen Preisaktion-Elements. Das Startdatum der Preisaktion, der Artikelname, die Zusatzinformation des Artikels, die Preisreduktion des Sonderangebots, der Normalpreis des Artikels, der Preis des Sonder-angebots sowie der Preis pro Einheit und die jeweilige Einheit wurden als relevante In-formationen identifiziert und sollen gescrapt werden. Diese Informationen wurden in der Abbildung rot markiert.
Wie bereits erwähnt, repräsentieren die <div>-Elementen, denen als Klassen-Attribut „col-xs-6 col-sm-4 col-lg-3“ zugewiesen sind, die einzelnen Preisaktionen. Bei „col-xs-6 col-sm-4 col-lg-3“ handelt es sich nicht um eine Klasse, sondern um drei verschiedene Klassenzuweisungen, die durch Leerzeichen getrennt sind. Diese Klassenzuweisung kann genutzt werden, um die Preisaktionen zu finden. Dazu kann das Cheerio-API auf dem DOM von dem HTML-Dokument genutzt werden, das in der Variablen $ gespeichert wurde. Das API bietet eine Selektor-Funktion an, der ein String-Eingabeparameter über-geben werden kann, um nach bestimmten Elementen im DOM zu suchen (Böhm und Mueller o. J.). Klassenattribute werden in dem Eingabestring mit einem vorangestellten Punkt gesucht, beispielsweise sucht $(‘.apple‘) nach allen Elementen mit class=“apple“ (Böhm und Mueller o. J.). Hier muss der Eingabestring $(‘.col-xs-6.col-sm-4.col-lg-3‘) lauten, da die Elemente gesucht werden sollen, die die drei Klassen col-xs-6 col-sm-4 col-lg-3 aufweisen.
Auf dem Selektor, der alle Preisaktionselemente umfasst, kann anschließend die Funk-tion each(function(i, elem)) ausgeführt werden, die eine Callback-Funktion für jedes selektierte Element durchführt (Böhm und Mueller o. J.). Der Parameter elem referen-ziert dabei das jeweilige DOM-Element, während i den Index des Elements darstellt (Böhm und Mueller o. J.). Abbildung 59 zeigt den diskutierten Code.
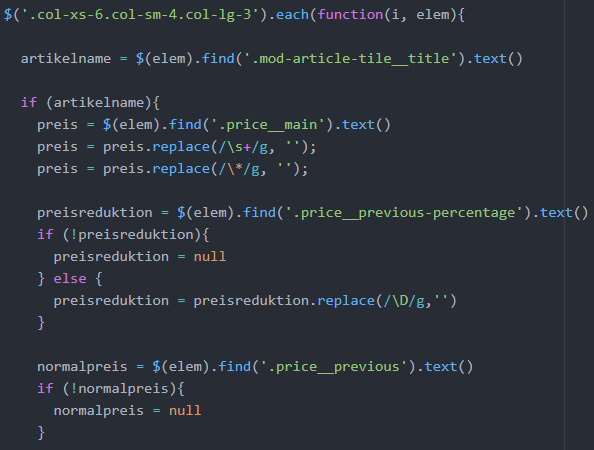
Zuerst soll der Artikelname ausgelesen werden. Der Artikelname steht als Text in dem <h4>-Element mit dem Klassenattribut class=„mod-article-tile__title“. Um die Nach-fahren eines bereits vorselektierten Elementes (hier elem) weiter zu filtern, kann die Funktion find() genutzt werden (Böhm und Mueller o. J.). Da wieder eine bestimmte Klasse selektiert werden soll, wird ‘.mod-article-tile__title‘ als String-Selektor genutzt. Der Text eines Elements kann mit der Funktion text() erreicht werden (Böhm und Muel-ler o. J.). Im Rahmen der Analyse des HTML-Dokuments wurde bemerkt, dass einige <div class= “col-xs-6 col-sm-4 col-lg-3“>-Elemente leer sind und keine Informationen beinhalten. Um die leeren Elemente nicht zu scrapen, wurde eine if-Abfrage eingeführt, die überprüft, ob ein Artikelname extrahiert werden konnte und der Scraping-Prozess fortgesetzt werden soll, oder ob der Artikelname undefined ist.
Der Sonderangebotspreis, der in einem Element mit dem Klassenattribut “price__main“ steht, kann ebenfalls mit find() gefunden und mit text() extrahiert werden. Der resul-tierende String umfasst allerdings nicht nur die relevante Dezimalzahl, sondern umfasst, wie in Abbildung 58 gesehen werden kann, einige Zeilenumbrüche. Um den String be-züglich dieser Zeilenbrüche zu bereinigen, kann die JavaScript-Standardfunktion re-place() verwendet werden, die als ersten Parameter einen zu entfernenden Substring und als zweiten Parameter einen String erwartet, mit dem der Substring ersetzt werden soll. Als zu entfernender String kann ein regulärer Ausdruck angegeben werden. Regu-läre Ausdrücke gehören in JavaScript zur Standardfunktionalität und haben als String die Form “/muster/modifikatoren“ (W3Schools k o. J.). Als Muster wird hier \s benötigt, wobei das Meta-Zeichen \s Leerzeichen, Zeilenumbrüche und ähnliche Zeichen reprä-sentiert (W3Schools l o. J.). Als Modifikator muss g (global match) verwendet werden, der bewirkt, dass alle Übereinstimmungen im gesamten String bearbeitet werden, und nicht nur die erste Übereinstimmung (W3Schools k o. J.). Als zweiter Parameter der replace-Funktion wird ein leerer String verwendet, d. h. die Zeilenumbrüche werden entfernt und nicht ersetzt.
Der Sonderangebotspreis wird aus einem <span>-Element extrahiert, wobei <span>-Elemente keine semantische Bedeutung für die HTML-Struktur aufweisen, sondern ins-besondere dafür genutzt werden, bestimmten Text durch CSS-Regeln zu formatieren (W3Schools m o. J.). Das <span>-Element, in dem der Sonderangebotspreis steht, hat ein weiteres untergeordnetes <span>-Element, in dessen untergeordnetem <sup>-Ele-ment als Text zwei Sterne (**) stehen, die hinter dem Sonderangebotspreis als hoch-gestellter Text angezeigt werden sollen (Abbildung 58). Es besteht die Besonderheit, dass wenn der Text des übergeordneten <span>-Elements mit text() extrahiert wird, die zwei Sterne des untergeordnetem <span>-Elements ebenfalls als Teil des Textes interpretiert werden. Aus diesem Grund musste der String des Sonderangebotspreises um die zwei Sterne bereinigt werden. Dies wurde wieder mit der replace-Funktion und einem regulären Ausdruck erreicht, wobei als Muster \* verwendet wird. Da der Stern eine besondere Bedeutung bei regulären Ausdrücken hat, muss \ vor dem Stern stehen, um ihn als normales String-Zeichen zu kennzeichnen.
Um die Preisreduktion und den Normalpreis des Artikels zu extrahieren kann wieder die find()-Funktion in Kombination mit dem Klassenattribut verwendet werden. Diese bei-den Informationen sind allerdings nicht bei jeder Preisaktion vorhanden. Deswegen wird für die Preisreduktion und den Normalpreis mit einer if-Abfrage geprüft, ob die Werte undefined sind. Falls sie undefined sind, werden die Variablen auf null gesetzt, weil bei der späteren Datenbanktransaktion der Wert null von der Datenbank als nicht gesetzter Wert akzeptiert wird, während undefined zu einer Fehlermeldung führen würde. Da der Text-String der Preisreduktionen die Form “– 20%“ hat, aber nur der Integer 20 in der Variablen gespeichert werden soll, wird die replace-Funktion mit einem regulären Aus-druck angewendet, der alle Zeichen, die keine Zahlen sind, entfernt. Das Muster dafür lautet \D (W3Schools k o. J.).

Abbildung 60 zeigt den Code zur Extraktion von Startdatum, Zusatzinfo, Einheit, Preis pro Basiseinheit und Basiseinheit. Um das Startdatum zu extrahieren, kann wieder die find()-Funktion in Kombination mit dem Klassenattribut verwendet werden, um zum entsprechenden <div>-Element zu navigieren. Bei dem gesuchten String handelt es sich allerdings nicht um den Text des Elements, sondern um den Wert des Attributs “data-promotion-date-formatted“. Um den Wert eines Attributes zu extrahieren, kann die Me-thode attr() des Cheerio-APIs verwendet werden (Böhm und Mueller o. J.). Der extra-hierte Datumsstring hat die Form “TT.MM.JJJJ“, allerdings wird von der HANA-Daten-bank für den DATE-Datenbanktyp ein String der Form “JJJJ-MM-TT“ erwartet. Deshalb wird auf dem String die bereits erläuterte Funktion split() angewendet, wobei sich aus der Trennung des “TT.MM.JJJJ“-Strings mit dem Separator “.“ ein Array mit den drei Elementen “TT“, “MM“ und “JJJJ“ ergibt. Mit reverse() wird die Reihenfolge der Array-Elemente umgedreht. Mit join(“-“) werden die Array-Elemente mit dem Konnektor “-“ zu einem String verknüpft. Es ergibt sich die benötigte String-Form “JJJJ-MM-TT“.
Die Zusatzinformation steht in einem <p>-Element, das über kein Klassenattribut ver-fügt. Es handelt sich bei dem Element um das dritte Kind eines <div>-Elements, das als Klassenattribut den Wert “mod-article-tile__info“ hat. Um die Zusatzinformation zu ex-trahieren, kann mit find() zu dem <div>-Element, und anschließend mit der Methode children() zu dessen Kindern navigiert werden. Zu dem dritten Kind kann navigiert wer-den, indem zwei Mal die Methode next() aufgerufen wird.
Um die Einheit zu extrahieren, kann wieder die find()-Funktion in Kombination mit dem Klassenattribut verwendet werden, um zum entsprechenden <div>-Element zu navigie-ren. Um den mit text() erhaltenen String zu bereinigen, können wieder reguläre Aus-drücke verwendet werden.
Zuletzt sollen der Sonderangebotspreis pro Basiseinheit und die jeweilige Basiseinheit extrahiert werden. Diese beiden Informationen stehen im gleichen String. Das Format des Strings ist dabei “Basiseinheit = PreisProBasiseinheit“. Allerdings kam es im Rahmen einer Preisaktion einmal zu der Abweichung, dass das Format “Einheit=PreisProEinheit“ war, ohne Leerzeichen neben dem Gleichzeichen. Um dieser potenziellen Abweichung Rechnung zu tragen, wurde eine if-Abfrage eingeführt, die prüft, ob der String “ = “ in dem extrahierten String vorliegt. Die die Methode search() gibt im positiven Fall den Index zurück, bei dem “ = “ gefunden wurde. Wurde “ = “ nicht gefunden, gibt sie -1 zurück. Anschließend kann die Funktion split() mit dem gefundenen Separator ange-wendet werden und die Informationen aus dem resultierenden Array ausgelesen wer-den. Es ist anzumerken, dass im Untersuchungszeitraum bei manchen Preisaktionen kein Preis pro Basiseinheit und keine Basiseinheit angegeben wurde. Um dies zu be-rücksichtigen wird in der äußeren if-Abfrage geprüft, ob preisbasis_string nicht undefi-ned ist. Falls preisbasis_string undefined ist, werden leere Strings in die Variablen ba-sis_einheit und basis_einheit_sonderangebotspreis geschrieben.
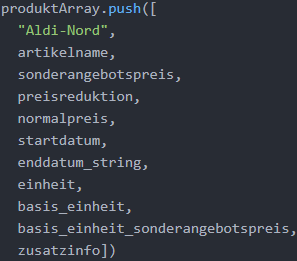
Als letzte Aufgabe in Rahmen der Iteration über ein Preisaktionselement müssen die extrahierten Informationen in das Array gespeichert werden, das später an die Daten-bank übergeben wird. Es wurde bereits erläutert, dass der HANA-Insert ein Array von Arrays erwartet, wobei ein inneres Array jeweils einen Datensatz darstellt. Die Elemente des inneren Arrays befüllen die 11 ?-Platzhalter der Insert-Datenbanktransaktion. In das äußere Array produktArray, muss folglich ein Array mit den 11 extrahierten Infor-mationen gepusht werden. Die folgende Abbildung zeigt den Code.
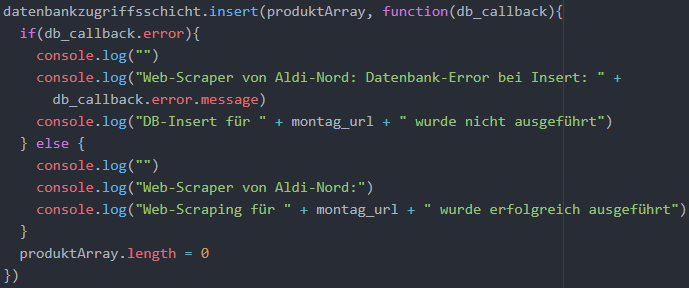
Nach dem Verlassen der each-Funktion über alle Preisaktionen und der Speicherung aller Daten in dem äußeren Array produktArray muss die insert-Middleware der Daten-bankzugriffsschicht aufgerufen werden, die als Eingabeparameter das äußere Array er-wartet. Falls im Rahmen des Callback-Objekts ein Error-Objekt übergeben wird, wird eine entsprechende Fehlermeldung auf der Kommandozeile ausgegeben. Tritt kein Feh-ler auf, wird auf der Kommandozeile ausgegeben, dass der Scraping-Prozess für den Montag erfolgreich abgeschlossen wurde. Anschließend werden sämtliche Elemente des äußeren Arrays entfernt, indem dessen Länge auf 0 gesetzt wird. Der Code wird in der folgenden Abbildung dargestellt. Der Web-Scraper für den Freitag wird nicht explizit erläutert, da seine Struktur mit dem Web-Scraper für Montag übereinstimmt.
Recent Comments