Wie bereits in 2.1 unter Datenvielfalt festgestellt, besteht Big-Data aus unterschiedlichen Datenformaten, die aus immer mehr Quellen aggregiert werden (Gluchowski und Chamoni 2016, S. 57). Der klassische Ansatz, Daten zu analysieren, basiert auf ruhenden Daten. Das bedeutet, die Daten werden auf einer Datenbank abgespeichert und bei Bedarf analysiert. Diese Vorgehensweise wird als Batch-Processing (deutsch: Stapelverarbeitung) bezeichnet. Dem steht das Feld von Streaming, das bei Echtzeitanalysen zum Einsatz kommt, gegenüber. (Bitkom 2014, S. 48)
Bei der Batch-Verarbeitung werden angefallene Daten aus operativen Systemen, beispielsweise Enterprise-Resource-Planning (ERP) Systemen oder Customer-Relationship- Management (CRM) Systemen extrahiert. Durch Batch-Skripte werden die neu angefallenen Daten aus den operativen Systemen abgezogen und für analytische Systeme aufbereitet. Dieser Vorgang wird häufig nachts durchgeführt, da das Ergebnis erst nach zeitlicher Verspätung verfügbar ist. Um diese Verzögerungen zu minimieren, müssen die Batch-Läufe parallelisiert und optimiert werden. Im Kontext von Big-Data stößt die Batch-Verarbeitung jedoch an vier Barrieren (Bitkom 2014, S. 48):
1. Limitierte Sichtbarkeit – Aus (Alt-) Applikationen im Unternehmen können häufig keine Daten über geeignete Schnittstellen gesammelt werden
2. Limitierte Skalierbarkeit – Die Quellapplikationen der Daten sind möglicherweise nicht auf wiederkehrende Anfragen ausgelegt
3. Limitierte Agilität – Während die Ursprungsformate oft in relationalen Schemata gespeichert sind, werden für die Batch-Prozesse teilweise nur Ausschnitte der Originaldaten verwendet
4. Eingeschränkte Historisierung – Das operative System enthält möglicherweise nur einen Ausschnitt der Transaktionsdaten (z.B. Daten eines Jahres) und ältere Daten befinden sich möglicherweise nur in einem Archiv
Die Limitationen hängen somit einerseits mit der Hard- und Software Infrastruktur zusammen und ob diese veraltet und damit nicht flexibel genug ist und andererseits mit der Integration der Informationssysteme im Unternehmen zusammen.
Neben den vier beschriebenen Barrieren spielen auch die Arten von Daten eine Rolle bei der Wahl des Datenzugriffs. Bei der Überwachung und Steuerung dynamischer Prozesse bedarf es eines anderen Ansatzes als der klassischen Batch-Verarbeitung. Da die Daten in diesem Fall nicht ruhen, sondern in Bewegung und variabel sind, spricht man hier vom Begriff Streaming (zu Deutsch: fließend). (Bitkom 2014, S. 52)
Eine Art von Daten, die durch Streaming analysiert werden, sind Sensordaten. Immer mehr Geräte sind mit Sensoren ausgestattet. Dadurch werden durchgehend Informationen ausgesendet und somit eine große Menge an Daten (Volume) mit einer hohen Geschwindigkeit (Velocity) und je nach Gerät unterschiedlichen Datentypen (Variety) erzeugt. Aufgrund dieser Eigenschaften muss auch die Richtigkeit der Daten (Veracity) bei der Auswertung gewährleistet werden. Da bei Sensordaten das 4V-Modell abgedeckt wird, kann deshalb davon gesprochen werden, dass Sensordaten das Gebiet von Big- Data erreichen. Dieses Phänomen der Vernetzung von Geräten durch Sensoren bezeichnet man als „Internet of Things“ (IoT), wird im Folgenden allerdings nicht weiter vertieft. (Kaur und Sood 2017, S. 1; Floerkemeier 2008)
Neben Sensoren erreichen auch Daten aus sozialen Medien, auch Social-Data genannt, ein solches Ausmaß, sodass von Big-Social-Data gesprochen werden kann (Reichert 2014, S. 66). Dazu zählt beispielsweise Twitter, das durch seine Twitter-API die Möglichkeit bietet, große Bestände öffentlicher Tweets zu bestimmten Themen, Interessensbereichen oder Veranstaltungen zu erzeugen (Reichert 2014, S. 192). Burgess und Bruns richten ihren Fokus dabei auf das Potenzial, durch diese Analysen die „Social Media Kommunikation“ zu verstehen. Die Daten könnten jedoch auch von Unternehmen dafür verwendet werden, um Informationen über ihre Marktpräsenz zu erhalten, oder beispielsweise ihre Beliebtheit und Reichweite zu messen. (Reichert 2014, S. 192)
Genau wie die Sensordaten zeichnet sich auch Big-Social-Data dadurch aus, dass die 4Vs Volume, Velocity, Variety und Veracity erfüllt sind. Daher dienen diese als Beispiel für neuartige Datenquellen, die aufgrund ihrer Struktur auf die Analysemethoden von Big-Data angewiesen sind, um Informationen zu extrahieren. Da in diesen Systemen konstant neue Daten erzeugt werden, spricht man in diesem Fall von Big-Data-Streams (Kaur und Sood 2017, S. 1).
Wenn Datenströme in Echtzeit, also im niedrigen Sekundenbereich, analysiert werden können, bieten sich verschiedene Möglichkeiten. Eine davon ist die Entdeckung von Betrugsfällen, beispielsweise bei monetären Transaktionen, wenn der Data Stream der Transaktionen Big-Data-Analysen unterzogen wird. Um diese Echtzeitanalyse, Realtime Streaming genannt, auszuführen, müssen die Daten analysiert werden, bevor sie überhaupt auf der Festplatte persistent gespeichert werden. Es wird dabei von der sogenannten In-Memory-Technik Gebrauch gemacht, die unter 2.2.2.2 erläutert wird. Dadurch kann zu jeder Zeit auf Veränderungen im System reagiert werden. Mit der Verwendung der In-Memory Technologie sind allerdings auch dessen Nachteile verbunden. So kann bei einem reinen Streaming-System nur eingeschränkt auf historische Daten zugegriffen werden, da diese lediglich auf dem Hauptspeicher abgelegt werden. Streaming Technologien eignen sich zwar für die Echtzeitanalyse von Daten, es sind jedoch auch Grenzen damit verbunden, vor allem was die Analyse zurückliegender Daten und den Verlust der Daten bei Systemausfällen betrifft. (Fasel und Meier 2016, S. 134)
Datenhaltung
SQL- und NoSQL-Datenbanken
Um Daten oder Informationen darzustellen sind Tabellen eine simple und anschauliche Form (Meier und Kaufmann 2016, S. 3). Klassische relationale Datenbanken machen sich dieses Prinzip zunutze und speichern Daten in Tabellen ab. Beim Betrieb von Informationssystemen in Unternehmen werden Datenbanken eingesetzt, um Daten zentral, strukturiert und persistent zu speichern. (Meier und Kaufmann 2016, S. 9)
Während relationale SQL-Datenbanken über einen langen Zeitraum die dominierende Grundlage betrieblicher Informationssysteme bildeten, bekommen diese unter dem Begriff NoSQL-Datenbanken inzwischen Konkurrenz (Gluchowski und Chamoni 2016, S. 205). NoSQL bedeutet „Not only SQL“ (zu Deutsch: nicht nur SQL) und zeigt, dass SQLbasierte Datenbanken bei diesem Konzept nicht ausgeschlossen werden, sondern vielmehr eine Ausprägung von mehreren sind. Im Gegensatz zu relationalen Datenbanken entsprechen NoSQL-Datenbanken nicht den ACID-Eigenschaften (Fasel und Meier 2016, S. 111). ACID steht dabei für Atomicity (atomar), Consistency (konsistent), Isolation (isoliert), Durabilty (dauerhaft) und ist besonders für sicherheitskritische Daten wie Kontenbewegungen relevant, da die Konsistenz der Daten gewährleistet werden muss, um Fehler in Datensätzen zu vermeiden (Schön 2016, S. 306). Diese Veränderung des Marktes, weg von den seit über 30 Jahren dominierenden relationalen Datenbanken, hängt mit den technologischen Grenzen von diesen zusammen. Die Entwicklung von relationalen Datenbanken begann zu einer Zeit, in der Programme auf einer einzigen physischen und isolierten Maschine liefen. Aufgrund des großen Volumens von Big-Data ist dieses Konzept nicht mehr umsetzbar. Vielmehr ist es notwendig, durch einen Clusterverbund die Daten auf mehreren physischen Maschinen zu verteilen, wie in Abbildung 1 dargestellt. Trotz vorhandener relationaler Datenbanken, wie RACS von Oracle, die im Clusterverbund agieren, führt der hohe Aufwand, die ACID-Kriterien einzuhalten dazu, dass erhöhte Latenzzeiten bei Transaktionen entstehen und somit die Performanz gesenkt wird. Neben dem Volumen von Big-Data spielt laut Meier und Kaufmann auch die Datenvielfalt eine Rolle. Dazu zählen auch unstrukturierte Daten wie beispielsweise die aus sozialen Medien, was zu Nachteilen hinsichtlich der Effizient, Performanz und Flexibilität der Datenverarbeitung führen kann (Meier und Kaufmann 2016, S. 222).
NoSQL-Datenbanken können diese Nachteile ausgleichen. Da unter diesen Voraussetzungen eine strenge Konsistenz, wie bei den ACID-Kriterien beschrieben, nur schwer umzusetzen ist, basieren die meisten NoSQL-Datenbanken auf dem BASE-Prinzip (Basically, Available, Soft State, Eventually Consistent). Während die Verfügbarkeit bei akzeptablen Reaktionszeiten dabei im Vordergrund steht und die Ausfalltoleranz gewährleistet werden muss, ist die Konsistenz, also die Korrektheit der Daten zweitrangig, da davon ausgegangen wird, dass sie mit der Zeit erreicht wird (Eventual Consistent). Dies wird durch die sogenannte Multiversion-Concurrency-Controll (MVCC) erreicht. Dadurch können, anders als bei klassischen relationalen Datenbanken, mehrere Nutzer gleichzeitig die Datenbestände manipulieren. Dies geschieht durch die Erstellung neuer Versionen, wenn Einfüge-, Lösch-, oder Änderungsaktionen ausgeführt werden. Werden verschiedene Attribute eines Datensatzes gleichzeitig verändert, werden diese synchronisiert. Bei Konflikten der Daten wird den Nutzern eine Konfliktmeldung angezeigt, die es zu beheben gilt. (Schön 2016, S. 306–308)
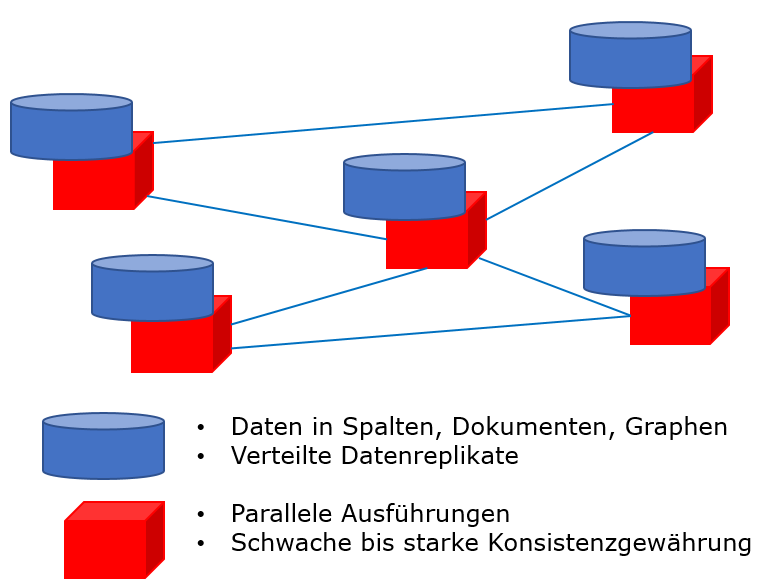
NoSQL-Datenbanken liefern also hauptsächlich Vorteile bei der Speicherung multistruktureller Daten, da diese nicht zwangsläufig in ein relationales Schema überführt werden müssen. Das liegt an den verwendeten flexiblen Schemas. (Fasel und Meier 2016, S. 113) Die Hauptgruppen von NoSQL-Systemen, auch Core-NoSQL-Modelle genannt, sind laut Fasel und Meier (Fasel und Meier 2016, S. 222):
• Schlüssel-Wert-Datenbanken
• Spaltenfamilien-Datenbanken
• Dokument-Datenbanken
• Graph-Datenbanken
Diese NoSQL-Datenbanken weisen alle gemeinsame Eigenschaften auf. Sie verfügen über ein nichtrelationales Datenbankmodell. Außerdem sind sie auf verteilte und horizontale Skalierbarkeit ausgerichtet und verwenden ein anderes Konsistenzmodell als ACID, wie beispielsweise das vorgestellte BASE. Horizontale Skalierung bedeutet, dass zur Vergrößerung der Kapazität neue Datenbank-Server hinzugefügt werden, anstatt die Performanz der bestehenden Server durch bessere Hardware zu erhöhen (vertikale Skalierung) (Fasel und Meier 2016, S. 222)
Um die Besonderheiten von NoSQL-Datenbanken aufzuzeigen, wird im Folgenden beispielhaft die Schlüssel-Wert-Datenbank (engl. key/value store) detaillierter erläutert. Bei der Schlüssel-Wert-Datenbank werden die zu speichernden Werte einem Schlüssel zugeordnet. Daraufhin können die Werte dann durch eine Abfrage unter der Verwendung des Schlüssels abgerufen werden. Da diese Form der Datenbank schemafrei ist, können Datenobjekte in jeder beliebigen Form gespeichert werden, ohne vorher beispielsweise Tabellen oder Spalten definieren zu müssen. Neben dem Schlüssel gibt es auch keine weiteren Formen von Referenzen zwischen den Daten, sodass sich Schlüssel- Wert-Speicher durch ihre Performanz bei Anfragen, die sich in einfach partitionierbaren Daten und der flexiblen Art der zu speichernden Daten zeigt, auszeichnet. (Meier und Kaufmann 2016, S. 223) Diese Form der Datenspeicherung ist im Rahmen von NoSQL der einfachste Vertreter (Fasel und Meier 2016, S. 113). Dies ist auch gleichzeitig der Vorteil der Schlüssel-Wert-Datenbank, denn selbst bei großen Datenmengen können die Werte effizient geschrieben und gelesen werden. Im Kontext von NoSQL kommt der Schlüssel-Wert-Datenbank daher eine wachsende Bedeutung zu. Werden die Schlüssel- Wert Paare im Hauptspeicher (RAM) der Datenbank zwischengespeichert, kann die Verarbeitungsgeschwindigkeit weiter erhöht werden. In diesem Fall spricht man von einer In-Memory-Datenbank. Diese Technologie wird im weiteren Verlauf genauer erläutert. (Meier und Kaufmann 2016, S. 223–224)
Bei der Wahl der Datenbank Technologie gibt es keine Universallösung, da jede Problemstellung seine optimale Technologie fordert (Fasel und Meier 2016, S. 113). So können Schlüssel-Wert Datenbanken bei großen Mengen unstrukturierter Daten beispielsweise eine sinnvolle Technologie sein, wenn es jedoch um sicherheitskritische Daten geht, bei denen Konsistenz gewährleistet sein muss, sind andere Datenbanktypen, wie eine relationale Datenbank eine geeignetere Wahl, da die Konsistenzsicherung der Daten ein zentrales Merkmal ist.
Aus diesem Grund werden häufig diverse Datenbankfamilien in einer Anwendung verwendet, um so einen Mehrwert zu schaffen und ihre Nachteile auszugleichen. Das bedeutet auch, dass sowohl SQL- als auch NoSQL-Technologien beteiligt sein können. Dieses Konzept wird Polyglot Persistence (mehrsprachige Persistenz) genannt. (Meier und Kaufmann 2016, S. 222)
In-Memory Technik
Die bereits erwähnte In-Memory Technik ermöglicht es, Daten nicht auf Festplatten zu speichern, wie es üblich ist, sondern auf dem Hauptspeicher (RAM). Das führt dazu, dass diese schneller aufgerufen und Analysen zügiger durchgeführt werden können. Während die Anfragen von relationalen Datenbankmanagementsystemen (RDBMS) im Millisekunden Bereich liegen, benötigen die von In-Memory-Datenbankabfragen nur Nanosekunden, wie Tabelle 1 verdeutlicht. Des Weiteren verfügen moderne Server mitt lerweile über mehrere Terabytes Hauptspeicher, sodass auch auf einem einzelnen Server große Datenmengen gespeichert werden können. (Breckmann und Pöhling 2012) Für Big-Data Anwendungen reicht dieses Speichervermögen eines einzelnen Severs jedoch nicht zwangsläufig aus. Daher besteht die Möglichkeit, von verteilten In-Memory- Systemen Gebrauch zu machen, wobei die Verteilung der Daten und der Zugriff auf unterschiedliche Server über In-Memory Data Grids (IMDG) durchgeführt wird. Dadurch können Daten bis in den dreistelligen Terabyte-Bereich im In-Memory-System verarbeitet werden. (Bitkom 2014, S. 46) Beispiele für In-Memory Plattformen sind SAP HANA und MemSQL im Bereich von relationalen Daten und Storm oder Spark für Streaming (Zhang et al. 2015, S. 1921).

Tabelle 1: Zugriffs- und Lesezeiten von Festplatten und Hauptspeicher (Plattner und Zeier 2012, S. 9)
Dem Pozential von In-Memory Datenbanken, zeitnahe Informationsversorgungen zu gewährleisten, kommt außerdem die Preisentwicklung von Speicher in den letzten Jahrzehnten zugute. Während die Leistungsfähigkeit von Speicher exponentiell ansteigt, sinkt der Preis stark ab. (Gluchowski und Chamoni 2016, S. 189) Die Entwicklung ist dabei der von Festplattenspeicher ähnlich. Dessen Preis sank von 250$ pro 1 MB im Jahr 1970 auf 0.01$ pro 1 MB in 2001. (Plattner und Zeier 2012, S. 10–11)
Bei der In-Memory-Technik wird zwischen reinen In-Memory-Systemen und Hybrid-In- Memory-Systemen unterschieden. Bei reinen In-Memory-Systemen werden alle Daten auf dem Hauptspeicher hinterlegt und Festplatten lediglich als Sicherheitsspeicher verwendet. Hybride In-Memory-Systemen hinterlegen lediglich einen Teil der Daten auf dem Hauptspeicher und die übrigen Daten auf der Festplatte. Dabei wird zwischen den relevanten Daten (Hot Data), die im Hauptspeicher verarbeitet werden und den weniger relevanten Daten (Cold Data), die auf der Festplatte gespeichert werden, unterschieden. Daher wird diese Struktur auch als Temperatur-Modell bezeichnet. (Bitkom 2014, S. 128)
Hadoop
Bei Hadoop handelt es sich um ein Open Source basierendes Java-Framework, welches die Organisation, das Speichern, Suchen und Analysieren von unterschiedlich struktu rierten Daten ermöglicht. Dazu werden die Daten auf einem Cluster von Standardrechnern verteilt. (Fasel und Meier 2016, S. 145) Diese Rechner werden auch Commodity- Hardware genannt und bieten den Vorteil, dass es sich um günstige Hardware handelt, die je nach Bedarf dem System hinzugefügt oder entfernt werden können (Schön 2016, S. 308). Aufgrund dieser Architektur kann Hadoop extrem skalieren und auch große Datenmengen performant bearbeiten (Bitkom 2014, S. 35). Außerdem ermöglicht die Verwendung von Standardrechnern niedrige Kosten für Hardware (Fasel und Meier 2016, S. 145). Hadoop zeichnet sich durch einige technische Komponenten aus, die dessen Grundlage bilden. Dazu zählen das verteilte Dateisystem HDFS, das Map-Reduce- Framework und das Programmiermodell YARN zur Verarbeitung der Daten. (Bitkom 2014, S. 35–40; Schön 2016, S. 308).
HDFS (Hadoop Distributed File System) ist ein hochverteiltes Dateisystem, das die Speicherung großer Datenmengen auf einem Cluster von Rechnern verteilt (Schön 2016, S. 308) und auch eine parallele Datenverarbeitung ermöglicht (Bitkom 2014, S. 38). Dazu werden die Daten in Blöcke aufgeteilt und dann auf den Knoten des Clusters redundant gespeichert, um Ausfällen und Fehlern vorzubeugen (Fasel und Meier 2016, S. 146).
Diese Parallelisierung wird mit Hilfe des Programmierframework Hadoop Map-Reduce umgesetzt. Das Framework macht sich dabei die verteilte Speicherung der Daten auf einem Cluster von Rechnern zunutze und wird parallel auf diesen Rechnern ausgeführt. Um die Verarbeitung großer Datenmengen schneller auszuführen, werden Berechnungen zunächst auf mehrere Rechner aufgeteilt (Map-Funktion) und nach den Berechnungen durch das Framework werden die Teilergebnisse mit Hilfe der Reduce-Funktion wieder zusammengeführt. Für die Ausfallsicherheit sorgt die redundante Speicherung der Daten im Cluster, sodass beim Ausfall eines Rechners ein anderer, der über eine Kopie verfügt, die Aufgabe übernehmen kann. So wird der Prozess durch den Ausfall weder abgebrochen, noch kommt es zu einer Verzögerung. (Schön 2016, S. 308)
Bei Map-Reduce handelt es sich um eine Batch-Verarbeitung, weshalb einige Potenziale im Kontext von Big-Data, wie Streaming- und Graphenverarbeitung nicht unterstützt werden. Deshalb wurde bei der Einführung von Hadoop 2 das Ressourcenmanagement- Tool YARN (Yet Another Resource Negotiator) ergänzt, das verschiedenen Anwendungen voneinander trennt. (Bitkom 2014, S. 40–41) YARN verwaltet dabei die im Cluster verfügbaren Ressourcen wie CPU, RAM und Festplattenspeicher und ermöglicht beispielsweise die Anbindung von In-Memory Verarbeitungssystemen wie Spark und Real Time Streaming Frameworks wie STORM direkt an HDFS (Schön 2016, S. 309). Dadurch ist Map-Reduce nur noch eine von mehreren Ausprägungen der Parallelisierung und je nach Situation können unterschiedliche Strategien in demselben Rechnercluster verfolgt wer den. (Bitkom 2014, S. 40–41) Durch diese Erweiterung von Hadoop wird auch die Datenvielfalt des 4-V-Modells in Betracht gezogen und somit beeinflusst die Technologie das Datenvolumen, die Datengeschwindigkeit, die Datenvielfalt und die Datenrichtigkeit (Schön 2016, S. 309).
Da Hadoop mit seinem Framework eine Antwort auf die Herausforderungen von Big- Data (4V) bietet, hat sich Hadoop laut (Bitkom 2014, S. 100) als Ergänzung herkömmlicher Lösungen in modernen Datenarchitekturen etabliert.
Recent Comments