Das EHI Retail Institute (EHI) hat 2004 eine Befragung zur Nutzung von Data Wa-rehouse und Business Intelligence im deutschsprachigen Handel durchgeführt. Festge-stellt wurde, dass die gängige IT-Architektur, die im Handel zur Entscheidungsunter-stützung bei der kurz- und mittelfristigen Sortimentsgestaltung, bei der Erfolgsmes-sung aller Maßnahmen im Marketingmix (Werbung, Preis, Platzierung) sowie bei der Sortiments-, Aktions- und Lieferantenanalyse eingesetzt wird, neben der einfachen Datenanalyse aus der deskriptiven Statistik, mit der Mittelwerte, Häufigkeiten und Streuungsmaßnahmen errechnet werden, vor allem die Data-Warehouse-Anwendung ist. In den Ergebnissen von EHI hat sich zu der Befragung der Marketingabteilung der Universität Essen von 2002 kaum etwas geändert. Als vorherrschendes Werkzeug stellte sich die OLAP-Software heraus (EHI-News 2004, S. 1 f.).
Werden die Warenkorb- und Bondatenanalyse in den Zentralen der Handelsformate durchgeführt, werden spezielle Datenverarbeitungssysteme von entsprechenden Mit-arbeitern genutzt. Gängig ist, dass die Datenverarbeitung über das Data Warehouse geschieht. In den einzelnen Filialen werden Bondatenanalysen von den eigenen Mitar-beitern über Data Marts auf den leistungsfähigen PC betrieben (Städler und Fischer (2001, S. 207–210).
Data Warehouse
Data Warehouse bedeutet wörtlich übersetzt: „Datenspeicher“. Es wird zwar oft falsch mit „Datenwarenhaus“ übersetzt, aber das Bild eines Selbstbedienungsladens für In-formationen ist zutreffend. Den Datenfluss im Unternehmen kann mit dem Warenfluss im Handel verglichen werden (Behme und Muksch 2001, S. 18). Data Warehouse kann als Konzept, aber auch als Technologie betrachtet werden. Es ist zum einen ein Kon-zept, das operative und verdichtete Daten voneinander getrennt speichert und zum anderen eine Technologie, in der eine weitere Datenbank aufgebaut wird (Schütte 2001, S. 3). Aus technischer Sicht ist das Data Warehouse eine Datenbank, die ver-schiedenen Datenquellen integriert. Aus betriebswirtschaftlicher Perspektive bietet das Data Warehouse die aufgesammelten Daten den Anwendern an, um mit diesen Analy-sen durchzuführen (Bauer 2013, S. 5).
Grundsätzlich beschäftigt sich das Data Warehouse mit der Entwicklung im Bereich Integrationsstrategien für Managementinformationen und ist für die Qualität, die In-tegrität und Konsistenz der Datenmaterialien zuständig. Es sorgt dafür, dass die richtigen Informationen zur richtigen Zeit am richtigen Ort vorhanden sind. Data Wa-rehouse ist kein Produkt, das erworben werden kann, sondern ein Konzept einer logi-schen einheitlichen und konsistenten Datensammlung. Dabei müssen die Daten in-haltsorientiert und integriert gesammelt werden, um bei der Entscheidungsunterstüt-zung zu helfen (Behme und Muksch 2001, S. 17 f.). Die Technik, die solch eine In-tegration ermöglicht, ist vorhanden, unterliegt jedoch einem ständigen Wandel (Behme und Muksch 2001, S. 17). Die Architektur von Data-Warehouse-Systemen dient primär der Beschreibung der Komponenten, stellt deren Eigenschaften und Funk-tionen dar und bildet die Beziehungen der Komponenten zueinander (Keller und Nedelmann 2012, S. 30). Abbildung 4 zeigt eine idealtypische Data-Warehouse-Architektur.
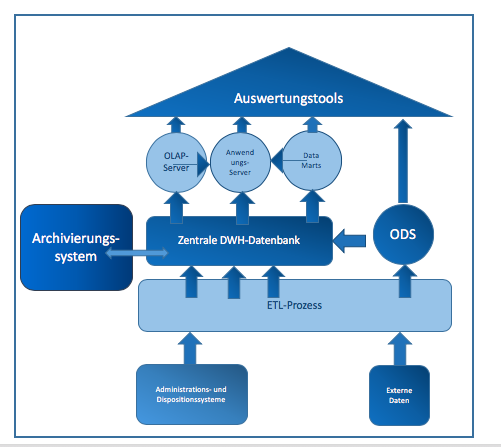
Quelle: In Anlehnung an (Muksch 2006, S. 131)
Die architektonische Umsetzung des Data-Warehouse-Konzeptes ist von dem Aufbau und der Organisation des Anwenderunternehmens abhängig. Die Informationsversor-gung muss auf allen Ebenen funktionieren. Ziel des Data-Warehouse-Konzeptes ist, große Mengen an Daten bereitzustellen und zu verarbeiten, um die Durchführung von Auswertungen und Analysen in entscheidungsrelevanten Prozessen zu realisieren (Behme und Muksch 2001, S. 19). Im Laufe der Zeit wird eine immer größer werden-de Datenbasis erreicht, wodurch der positive Effekt in Bezug auf die verstärkte Nut-zung von Daten erzielt wird (Behme und Muksch 2001, S. 20; Schütte 2001, S. 6). Im Data Warehouse werden die erfassten Daten nicht überschrieben und mit einem Zeit-kennzeichen gespeichert, dadurch sind die Daten langfristig abrufbar. Durch den Zeit-bezug ist es auch möglich, langfristige Betrachtungen abzurufen, beispielsweise „Um-sätze bestimmter Produkte in einem bestimmten Jahr“ (Schütte 2001, S. 6). Da die Daten nicht überschrieben werden, bleiben sie unveränderlich (Humm und Wietek 2005, S. 3).
Inmon, einer der Mitbegründer des Data-Warehouse-Gedankens, definiert Data Ware-house wie folgt: „A Data Warehouse is a subject oriented, integrated, non volatile and time variant collection of data support of management’s decisions“ (Inmon 1996, S. 33). Es sollen ausschließlich Daten gespeichert werden, die den Informationsbedarf des Managements abdecken. Damit eine einheitliche Datensammlung gelingt, werden die internen Daten aus dem Vorsystem vereinheitlicht und mit externen Daten ergänzt (Inmon 1996, S. 33–35).
Das Data Warehouse verfügt, wie Abbildung 4 zeigt, über mehrere Komponenten. Mit-hilfe der Importkomponente ist es möglich, die gespeicherten Dateninhalte durch ein Transformationsprogramm, das wiederum ermöglicht, interne operative Datenquellen und externe Datenquellen zu lesen, zu vereinheitlichen und anschließend in die zentra-le Datenbasis zu übertragen (Gabriel et al. 2009, S. 8). Die Basis für das Data Wa-rehouse wird durch die Integration, Bereinigung und Konsolidierung der Daten aus unterschiedlichen internen, externen und heterogenen Quellsystemen gebildet (Farkisch 2011, S. 59). Dieser Vorgang des Imports der Daten wird in der Literatur als ETL-Prozess bezeichnet. Ein ETL-Prozess sorgt für die Verbindung zu den vorgelager-ten operativen Datenquellen, der Prozess setzt sich aus den Prozessen der Filterung, Harmonisierung, Aggregation und der Anreicherung zusammen. Zuerst findet die Filte-rung statt, bei der die Daten aus den Datenquellen in „Persistent Staging Area“ extra-hiert und bereinigt werden (Kemper und Finger 2006, S. 131). Die Bereinigung der extrahierten Daten findet durch das Befreien von syntaktischen und semantischen Mängeln statt. Im zweiten Schritt kommt es zur Harmonisierung, es liefert dispositiv verwertbare Daten. An dieser Stelle finden ein Zusammenführen der gefilterten Daten und ein Abgleich der Daten auf Syntax und Betriebswirtschaftlichkeit statt. Im folgenden Schritt der Aggregation werden die Daten in die gewünschte Granularität3 über-führt (Bauer 2013, S. 60; Kemper und Finger 2006, S. 132).
Eine weitere Komponente ist die Verwaltungskomponente. Diese sorgt anhand ver-schiedener Speicherbereiche und -technologien für die Organisation der Datenbestän-de (Gabriel et al. 2009, S. 8). Auch Data Marts gehören zur Verwaltungskomponente. Die Auswertung der Daten ist aufgrund der großen Datenbanken, die zum Teil mehre-re Terabyte groß sind, etwas mühsam und nimmt viel Zeit in Anspruch. Dementspre-chend werden oftmals die Daten in Data Marts zerlegt, um eine bessere Überschau-barkeit zu erreichen (Behme und Muksch 2001, S. 20).
Data Marts
Die zentrale Haltung der Daten bringt auf Dauer Probleme mit sich, zum einen – wie im obigen Absatz erwähnt – durch die Größe der Daten, zum anderen ist es schwieri-ger, die Daten zu skalieren, wie beim Anwachsen der Nutzeranzahl oder der Datenbe-stände. Aus diesem Grund ist die Zerlegung der Daten in Data Marts aus organisatori-schen sowie aus technischen Gründen von Vorteil (Bauer 2013, S. 59). Golfarelli und Rizzi (2009) definieren Data Mart wie folgt: „A data Mart is a subset or an aggregation of the data stored to a primary data warehouse. It includes a set of information pieces relevant to a specific business area corporate department, or category of users” (S. 9). Data Marts verfolgen demnach das Ziel, bestimmte Bereiche eines Unterneh-mens als Teilsicht eines Data Warehouse abzubilden. Data Marts sind somit Ausschnit-te redundanter Daten, die aus dem Data Warehouse entnommen werden. Genauer sind es Daten aus einer bestimmten Region oder Daten einer bestimmten Produkt-gruppe (Köppen et al. 2012, S. 27–30). Der Vorteil ist, dass die Auswertung der Daten viel schneller abläuft, und da es sich nur um eine Teilmenge des Data Warehouse bei gleicher Technologie handelt, ist sie pflegeleichter. Aufgrund der Teilsicht auf die Da-ten ergeben sich Vorteile in Datenschutzaspekten (die Abteilungen haben nicht immer die Berechtigung, auf die Daten zuzugreifen). Durch die Unabhängigkeit der Abteilun-gen ergeben sich auch Vorteile für die organisatorischen Aspekte. Zudem wird mit Da-ta Marts das Datenvolumen verringert und somit auch die Last verteilt. Zusammenge-fasst wird mit der Grundidee, dass durch Data Marts die Abteilungen eines Unterneh-mens als Teilsicht einer Data-Warehouse-Architektur abgebildet werden, die Komplexi-tät des Datenmodells verringert (Bauer 2013, S. 59 f.).
Data Marts entwickeln sich nach und nach im Data Warehouse, zu Beginn sind nur einfache Daten gespeichert, in den nächsten Stufen kommen weitere Informationen hinzu, es werden schrittweise Informationen integriert, sodass am Ende ein neues Da-ta Warehouse entstehen kann (Behme und Muksch 2001, S. 21). Demgemäß ent-spricht das semantische Datenmodell eines Data Marts im Normalfall dem des Data Warehouse (Behme und Muksch 2001, S. 20). In der Entwicklung ist zwischen dem Data Warehouse und den Data Marts kaum Unterschiede zu finden, die Komplexität bei Data Marts ist geringer als bei dem Data-Warehouse-Datenmodell. Data Marts ha-ben ein spezialisiertes Datenmodell, das leichter zu verstehen und zugriffseffizienter ist (Lusti 2002, S. 136).
Das Ziel von Data Warehouse ist, wie bereits erwähnt, die Integration der Datenbe-stände in einem Unternehmen, das bedeutet aber nicht, dass die Datenhaltung inte-griert werden muss (Bauer 2013, S. 59).
In der Literatur wurde häufig darüber diskutiert, wie ein Data Warehouse am besten aufgebaut wird, dabei wird meist nicht geklärt, ob die Unterschiede bei der Implemen-tierung in der Architektur oder in der Methodik liegen (Wells 2003). Die Unterschiede zwischen den verschiedenen Data-Warehousing-Implementierungsmethoden wurden in den letzten Jahren immer weniger (Eckerson 2002).
Der Ausgangspunkt einer Data-Warehouse-Architektur war die konzeptionelle Archi-tektur, die erst später mit der logischen physikalischen Architektur erweitert wurde (Humphires 1999). Die konzeptionelle Ebene eines Data-Warehouse besteht aus drei Komponenten: den Datenquellen, dem Datenspeicher und dem Endbenutzerzugriff. Es gibt verschiedene Data-Warehouse-Architekturen, die zentrale Data-Warehouse-Architektur wurde bereits vorgestellt. Folgend werden weitere vier Architekturformen betrachtet und miteinander verglichen, um herauszufinden, welche Architektur am erfolgreichsten ist und sich am besten für die Bondatenanalyse eignet.
Unabhängige Data-Mart-Architektur
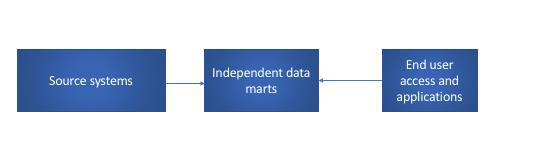
Quelle: In Anlehnung an (Ariyachandra 2004, S. 30)
Die unabhängige Data-Mart-Architektur beinhaltet mehrere Data Marts, bei deren Entwicklung mehrdimensionale oder relationale Datenstrukturen verwendet werden. Zudem werden die Data Marts unabhängig voneinander entwickelt und verwendet. So werden, wie in Abbildung 5 zu sehen ist, Daten direkt aus dem Quellsystem extrahiert und in die Data Marts geschrieben, auf die der Endnutzer zugreift. Um bei Entschei-dungen eines Unternehmens helfen zu können, beinhalten unabhängige Data Marts detaillierte und zusammengefasste Daten. Der Umfang an Daten in dieser Architektur begrenzt sich auf die Geschäftsanforderung einer funktionalen Einheit, es werden kei-ne Informationsanforderungen der gesamten Organisation beachtet. Demzufolge ist der Aufbau dieser Architektur im Vergleich zu dem eines zentralen Data Warehouse kostengünstiger und die Investitions- und Betriebskosten sind niedriger. Überdies hat sie eine kürzere Implementierungszeit und bietet eine höhere Flexibilität. Das macht die Data-Mart-Architektur für einige Unternehmen attraktiver (Ariyachandra 2004, S. 29 f.)
Jedes einzelne unabhängige Data Mart wird mit eigenen Datendefinitionen und Dimen-sionen erstellt, ohne diese untereinander zu koordinieren. Diese Data Marts werden mit Daten aus einer organisatorischen Umgebung, die aus mehreren operativen Sys-temen besteht, versorgt, dabei kommt es innerhalb der nicht integrierten Data Marts zu Dateninhaltsüberschneidungen. Zudem kann es bei unabhängigen Data Marts dazu führen, dass die voneinander unabhängig entstandenen Data Marts später durch In-tegration und Transformation wieder zusammengeführt werden (Köppen et al. 2012, S. 35). In Abbildung 6 wird dies verdeutlicht.
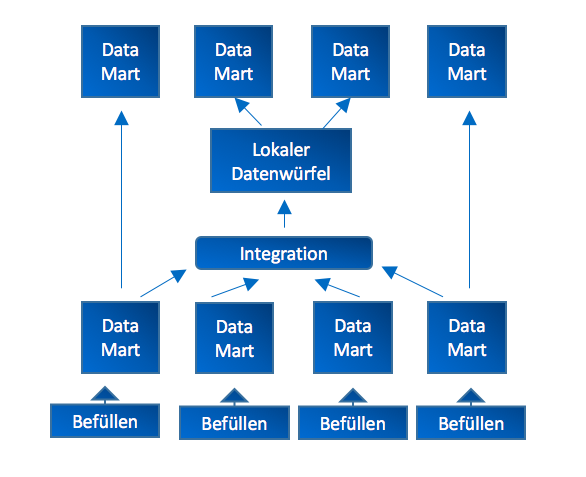
Quelle: Iin Anlehnung an (Köppen et al. 2012, S. 36)
Die Data Marts werden integriert und ein globaler Datenwürfel entsteht. Während der Analyse kann es schnell zu widersprüchlichen Ergebnissen kommen, da es bei den Ergebnissen der Analyse von lokalen Data Marts und der Analyse von globalen Daten-würfeln aufgrund der unterschiedlichen Daten zu keinen Übereinstimmungen kommen kann. Zudem ist die Integration der Data Marts mit viel Aufwand verbunden (Köppen et al. 2012, S. 36). In der Bondatenanalyse im Lebensmitteleinzelhandel werden auch Data Marts aufgebaut, jede Filiale hat ihr eigenes Data Mart, die unabhängig von an-deren Filialen aufgebaut werden (Städler und Fischer 2001, S. 206 f.).
Data-Mart-Bus-Architektur
Die Data-Mart-Bus-Architektur wird auch als Data-Warehouse-Bus-Architektur be-zeichnet. Die Data-Mart-Bus-Architektur wird in einen Staging-Bereich und in ein ar-chitekturdefiniertes Data Mart unterteilt. Die Daten werden als Erstes aus den Quell-systemen extrahiert, im Staging-Bereich transformiert und anschließend einer Data-Mart-Architektur zugeführt (Ariyachandra 2004, S. 30 f.). Abbildung 7 verdeutlicht diesen Prozess.
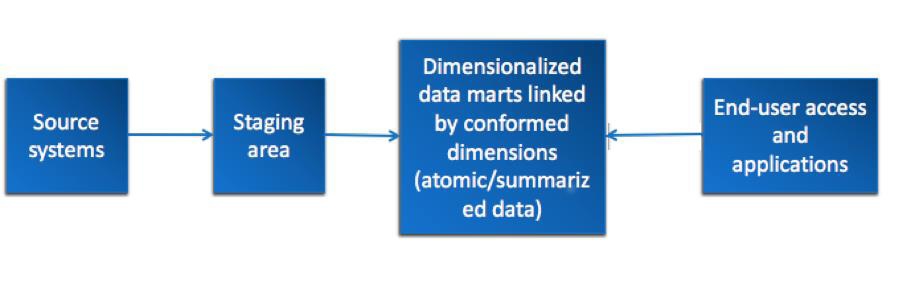
Quelle: In Anlehnung an (Ariyachandra und Watson 2006, S. 5)
Sie werden in der Data-Mart-Bus-Architektur schrittweise in bestimmen Themenberei-chen entwickelt und anschließend an die unternehmensweite Architektur angepasst. Als Erstes entsteht das Proof of Concept, mit einer Beschränkung auf Themenbereiche, damit werden Geschäftsprozesse wie Bestellungen, Lieferungen, Kundenanrufe oder Rechnungsausstellungen unterstützt (Ariyachandra 2004, S. 30–33). Die Master Suite entsteht im nächsten Schritt, diese besteht aus angepassten Dimensionen und stan-dardisierten Faktendefinitionen, die im gesamten Unternehmen einheitlich interpretiert werden (Kimball und Ross 2002, S. 78 f.). Für die Erstellung einer Master Suite wird in der gesamten Organisation eine Analyse durchgeführt, in der Informationsanforderun-gen auf Unternehmensebene festgestellt werden. Unter Berücksichtigung, dass eine abteilungsübergreifende Beteiligung stattfindet, werden währenddessen konsistente Datendefinitionen und -dimensionen erstellt. Die einzelnen Data Marts bestehen aus Dimensionen und Faktentabellen. Dabei kommt es vor, dass die Tabellen von mehreren Data-Marts-Geschäftsprozessen benötigt werden. Tabellen, die von mehreren be-nutzt werden, werden neu angepasst. Diese angepassten Dimensionen werden als Bus gesehen, in denen sich die Geschäftsprozesse-Data-Marts einklinken, um eine gemein-same Dimension zu erhalten (Kimball und Ross 2002, S. 30-33; Firestone 2002, S. 1).
Die dominanten Datenstrukturen, die in architekturdefinierten Marts verwendet wer-den, sind dimensionale Strukturen, diese verwenden entweder ein relationales Stern-schema oder einen multidimensionalen Datenwürfel. Mit Sternschemata wird ermög-licht, große Datenmengen zu analysieren, wohingegen mit mehrdimensionalen Daten-würfeln komplexe Daten miteinander verglichen und Berechnungen auf kleinen Da-tenmengen durchgeführt werden können (Kimball und Ross 2002, S. 30–33). Gerade in Lebensmittelgeschäften werden Sternschemata angewendet. Dabei speichern Fak-tentabellen die Messungen wie die Dollarverkäufe oder Stückverkäufe ab. Kundenin-formationen oder Produktinformationen werden in den Dimensionstabellen gespei-chert. Sobald die Dimensionen nicht über die Datenbereiche der Objektbereiche hin-weg genau in Bezug auf die Werte der Schlüssel und Attribute definiert werden, kommt es zu nicht einheitlichen Dimensionen. Falls dies der Fall ist, ist es nicht mög-lich, Daten aus verschiedenen Data Marts in Abfragen zu kombinieren (Ariyachandra 2004, S. 33).
Enterprise-Data-Warehouse-Architektur
Quelle: In Anlehnung an (Ariyachandra und Watson 2006, S. 5)
Bei der Enterprise-Data-Warehouse-Architektur (EDW), die unter anderem von Inmon (1996) eingeführt wurde, handelt es sich um einen integrierten zentralen Datenspei-cher (siehe Abbildung 8). In dieser Form der Architektur, die aus zwei Komponenten besteht – dem Datenbereitstellungsbereich und/oder einem ODS (Operational Data Store) und aus der Komponente „zentraler Datenspeicher“ wird bei Entscheidungssituationen ein direkter Zugriff auf das Data Warehouse ermöglicht oder es findet eine Verteilung der Daten an abhängige Data Marts statt (Ariyachandra 2004, S. 33–36). In dem zentralen Datenspeicher befinden sich detaillierte Daten und zusammengefass-te Daten, die mehrere thematische Geschäftsbereiche beinhalten. Die Daten, die aus den Legacy-Quellen extrahiert wurden und in den Datenbereitstellungsbereich gelan-gen, und die Daten, die aus dem ODS transformiert wurden, werden in den zentrali-sierten Datenrepository geschrieben (Ariyachandra 2004, S. 33–36). Diese Vorgänge werden in Abbildung 8 dargestellt. Damit nicht zu große Mengen an Daten in diesem zentralen Datenspeicher gespeichert und so die Zugriffszeiten verschlechtert werden, wird der zentrale Datenspeicher mit verschiedenen geschäftsbereichspezifischen Data Marts verknüpft, die mit Daten aus dem zentralen Datenspeicher und weiteren Daten gefüllt werden. Sie werden auch als eine Sammlung von Daten definiert, die primär auf funktionale Geschäftseinheiten zugeschnitten sind. Sie sind ein Teil des zentralen Datenspeichers, da sie eine kleine Menge an Detaildaten und eine große Menge an verdichteten Daten besitzen und zudem eine begrenzte Menge an historischen Daten. Überdies werden sie als gemeinsame Ressource zwischen Geschäftseinheiten betrach-tet, wenn die Geschäftseinheiten dieselben Data Marts für die analytischen Anforde-rungen brauchen. Diese abhängigen Data Marts werden als die einzige Version der Wahrheit betrachtet und sind generell dazu da, die Abfrageverarbeitung auf schnells-ter Weise zu ermöglichen und den Benutzern eine dimensionale Ansicht der Daten zu verschaffen (Ariyachandra 2004, S. 33–36).
Mithilfe einer umfassenden Planungs- und Unternehmensebenen-Anforderungsanalyse wird eine unternehmensorientierte Sicht auf die Daten geschaffen. In dieser werden alle betroffenen Geschäftsbereiche innerhalb der Organisation berücksichtigt. Diese Analyse ist für die Entwicklung einer Enterprise-Data-Warehouse-Architektur notwen-dig. Um die Datenredundanz zu vermeiden und ein stabiles Datenbankdesign zu erhal-ten, das schnell auf Änderungen im Geschäftsbereich reagieren kann, müssen die Da-ten in einer dritten normalen Form gespeichert werden. Im Gegensatz zu dem zentra-len Datenspeicher wird bei den abhängigen Data Marts das Sternschema angewendet. Diese Kombination aus einem zentralen Datenspeicher mit gemeinsamen Datenstan-dards und integrierten Datenelementen aus der ganzen Organisation hat zur Folge, dass ein EDW iterativ nach Geschäftsbereichen aufgeteilt ist (Ariyachandra 2004, S. 33–36).
Föderierte Datenbanksysteme
Föderierte Datenbanksysteme sind Gesamtsystemarchitekturen, die mehrere Data Warehouses, Data Marts und Altsysteme zu integrieren und miteinander zu verknüp-fen versuchen. Hackney, der zu den Hauptvertretern der föderierten Data-Warehouse Architekturen gehört, bezeichnet diese als eine „Architektur von Architekturen“ (Ariyachandra 2004, S. 36).

Quelle: In Anlehnung an (Ariyachandra 2004, S. 37)
Diese Art der Datenbank wird von Ariyachandra (2004) als einzig praktikable Lösung empfohlen, um mit bereits vorhandenen Datenbanksystemen zu arbeiten und diese zu unterstützen. Zudem ist sie die einzige Möglichkeit, vorhandene und neu entstehende Datensilos zu integrieren (S. 36). Der Hauptunterschied zu anderen Systemen liegt darin, dass dabei die Komponentensysteme eine gewisse Selbstständigkeit behalten und das Gesamtsystem nicht vollständig auf einer übergeordneten Ebene verwaltet wird (Conrad 1997, S. 31). Dadurch entsteht eine föderierte Informationsansicht mit allen für den Benutzer relevanten Informationen. Die Autonomie der lokalen Organisa-tionen bedeutet jedoch, dass der Benutzer nicht aktiv in diese eingreifen kann, son-dern nur Leserechte besitzt. Andernfalls hätten durch gleichzeitiges Lesen und Bear-beiten die lokalen Anwendungen verschiedene Versionen von Datensätzen, die mit hohem Aufwand angepasst werden müssten (Conrad 1997, S. 80).
Föderierte Datenbanksysteme lassen sich in zwei Kategorien unterteilen. Sobald der Nutzer die Föderation übernimmt und diese selbst verwaltet, ist von einer losen Kopp-lung des Systems die Rede. In diesem Fall liegt die Verantwortung beim Benutzer, da er seinen eigenen Bedürfnissen entsprechend Datenbanksysteme auswählt, die an seiner Föderation teilnehmen sollen. Durch diese Form wird dem Benutzer ein hoher Grad an Flexibilität ermöglicht (Conrad 1997, S. 42).
Im Fall einer engen Kopplung von Datenbanksystemen wird die Föderation durch ei-nen entsprechenden Administrator erstellt und überwacht. Dazu findet eine Absprache mit Administratoren anderer lokaler Organisationen statt. Der Administrator des föde-ralen Datenbanksystems bestimmt somit, welche Daten für welchen Benutzer global zugreifbar gemacht werden. Dadurch wird dem Benutzer viel Arbeit abgenommen, aber auch seine Flexibilität eingeschränkt, was zu einer Ansicht führen kann, die nicht seinen Wünschen entsprechen (Conrad 1997, S. 42).
Die Hauptarchitektur eines föderalen Datenbanksystems zeichnet sich durch das Be-reitstellen von Daten, Metriken und Zahlen über mehrere Data Warehouses und Data Marts aus, wie in Abbildung 9 zu erkennen ist. Dabei wird keine neue kombinierte Da-tenbank erstellt. In der Praxis ist der Erfolg einer solchen Architektur von der Qualität der Daten in den lokalen Organisationen abhängig. Überdies können Schwierigkeiten bei der Kombination von verschiedenen Quellen mit verschiedenen Datenstrukturen und Software- und Hardwareinfrastrukturen entstehen (Ariyachandra 2004, S. 37).
Bewertung von unterschiedlichen Data-Warehouse-Architekturen
Um auszumachen, welche Data-Warehouse-Architektur am erfolgreichsten ist, wurde von Ariyachandra und Watson (2006) eine Studie durchgeführt. Die dabei befragten Unternehmen weisen Umsatzzahlen von weniger als 10 Millionen USD bis hin zu 10 Millarden USD pro Jahr vor. Dabei wurden folgende fünf Architekturen, die bereits in diesem Kapitel beschrieben wurden, untersucht: die unabhängigen Data Marts, die Data-Mart-Bus-Architektur mit verknüpften dimensionalen Data Marts, die zentralisier-te Data-Warehouse-Architektur, die föderierte Architektur und die Hub-and-Spoke-Architektur (EDW-Architektur). Bei der zentralisierten Data-Warehouse-Architektur handelt es sich um eine zentrale Datenbank, in die alles ohne die Nutzung von einzel-nen Data Marts gespeichert wird. Die Untersuchung beruht auf der Befragung von Da-ta-Warehouse-Managern, Data-Warehouse-Mitarbeitern, Information Systems Mana-gern und unabhängigen Beratern/Systemintegratoren; Personen also, die im Unter-nehmen eine Data-Warehouse-Architektur nutzen. Als Ergebnis der Untersuchung wurde veröffentlicht, dass die am häufigsten verwendete Architektur mit 39 % die EDW-Architektur ist. Die zweithäufigste Architektur mit 26 % ist die Bus-Architektur, gefolgt von der zentralisierten Datenbank mit 17 %, den unabhängigen Data Marts mit 12 % und der föderierten Data-Warehouse-Architektur mit 4 %. Zudem wurde festge-stellt, dass die häufigste Plattform für den Betrieb von Data Warehouses Oracle mit 41 % war, gefolgt von Microsoft mit 19 % und IBM mit 18 % (Ariyachandra und Watson 2006, S. 4–6).
Für die Bewertung des Erfolgs der jeweiligen Data-Warehouse-Architektur wurden vier Kriterien gewählt: die Informationsqualität, die Systemqualität, individuelle und orga-nisatorische Auswirkungen und die Bewertung durch die Umfrageteilnehmer. Das Er-gebnis der Befragung war, dass die unabhängigen Data Marts generell als eine schlechte Architektur und die föderierten Data Warehouses als die schlechteste Archi-tektur gelten. Innerhalb der Auswertungen wurde dies damit erklärt, dass die föderier-te Data-Warehouse-Architektur nicht für langfristige Lösungen optimal dient. Zwischen der Bus-Architektur, der EDW-Architektur und der zentralisierten Architektur sind die Ergebnisse relativ ähnlich, sodass nicht zu entscheiden war, welche der Architekturen am erfolgreichsten ist (Ariyachandra und Watson 2006, S. 4–6).
Zudem wurde in der Studie untersucht, ob ein Zusammenhang zwischen der Größe der Unternehmen, den gespeicherten Daten und der Architektur besteht. Das Resultat war, dass die EDW-Architektur in der Regel für unternehmensweite Implementierun-gen und größere Warehouses verwendet wird. Dies hat sich vor allem durch die Kos-ten und die Zeit für die Implementierung der unterschiedlichen Architekturen bemerk-bar gemacht. Es wurde festgehalten, dass die EDW-Architektur als teuerste und zeit-aufwendigste gilt, was aber aufgrund der größeren Domäne nicht verwunderlich ist (Ariyachandra und Watson 2006, S. 4–6).
Zusammenfassend zeigt die Studie, dass trotz der unterschiedlichen Funktionsweisen Bus-, EDW- und zentralisierte Architekturen ähnlich erfolgreich sind. Dies ist auch der Grund, warum alle drei Architekturen in der heutigen Zeit noch gängig sind. Eine ob-jektive Einschätzung, welche der Architekturen in Bezug auf Informationen, System-qualität und individuelle und organisatorische Auswirkungen als die beste gilt, ist nicht möglich. Es ist eine ausführliche Untersuchung unter Einbeziehung aller Unterneh-mensorganisationen, deren Anforderungen und der Menge an gespeicherten Daten erforderlich (Ariyachandra und Watson 2006, S. 4–6).
Vor- und Nachteile der jeweiligen Architekturen in Bezug auf die Bon-datenanalyse
Die Datenbestände eines Handelsunternehmens werden in einem Data Warehouse zur Warenkorb- und Bondatenanalyse gesammelt. Dies geschieht in einer integrierten (semantischen) Datenstruktur, die durch mehrere Datenbanksysteme realisiert wird. Diese Art der Datenbanknutzung bringt verschiedene Vorteile mit sich. Aufgrund der unterschiedlichen Konzentrationsprozesse und Investitionszyklen werden in Handels-unternehmen in den einzelnen Filialen, der Zentrale und den Logistikeinheiten ver-schiedene Hard- und Softwaresysteme genutzt. Innerhalb eines Handelsunternehmens können in den Filialen unterschiedliche Kassensysteme laufen und auch Tastaturbele-gungen können variieren. An dieser Stelle dient ein Data Warehouse als ein semanti-scher Ort für alle Schnittstellen sowie Bewegungs- und Bestandsdaten. Das Data Wa-rehouse ermöglicht dem Handelsunternehmen, die einzelnen Schnittstellen miteinan-der zu integrieren und die Datenverarbeitung zu modernisieren. Im Laufe der Zeit ha-ben sich die meisten Handelsunternehmen so entwickelt, dass die administrativen und dispositiven Tätigkeiten eines gesamten Unternehmens über die Zentrale mit einheit-lich qualifiziertem Personal geleitet werden. Durch diese Umstellung ergeben sich mehr Aktivitäten im Bereich Controlling und Revision, wodurch wiederum die Kosten steigen. Währenddessen entstehen Umsatzeinbußen im Frischebereich, weil die Um-sätze stark von lokalen Gegebenheiten abhängen. Mithilfe von Data Warehouses wird ermöglicht, diese zentralisierten Dispositions- und Controllingprozesse zu vereinheitli-chen und automatisierte Analysen zu ermöglichen. Für das Rechnungswesen werden in der Regel traditionelle Informationssysteme genutzt, die periodisch verdichtete Aus-wertungen erstellen können. Im Data Warehouse werden hingegen aktuelle und histo-rische Daten in unverdichteter Form gespeichert, was den Vorteil mit sich bringt, dass Analysen mit Daten aus längeren Zeiträumen durchgeführt werden können. Dadurch können beispielsweise Zusammenhänge im Bereich Logistik oder Marketing erkannt werden. Mithilfe verschiedener Datenspeicherungs-, Datenverarbeitungs- und Daten-präsentationstechniken, die sich im stetigen Wandel befinden, können Handelsunter-nehmen ihren Erfolg ausbauen (Städler und Fischer 2001, S. 207-210).
Die zentrale Data-Warehouse-Architektur wird durch eine redundante zentral betrie-bene physische Datenbasis geleitet, somit ist ein Zugriff auf eine einheitliche physi-sche Datenbasis möglich. Dabei entstehen multidimensionale Datenmodelle. Die mul-tidimensionalen Anfragen haben eine geringe Netzbelastung, was sich als Vorteil für die zentrale Data-Warehouse-Architektur herausstellt, demzufolge eignet sich diese Form der Architektur besonders für Unternehmen, die eine zentrale Geschäftsabwick-lung betreiben. Der Nachteil dieser Architekturform ist, dass der Zugriff auf bestimmte Teile im System erheblich komplexer ist und einzelne komplexere Abfragen mehr Zeit benötigen. Die Einführung und Implementierung eines Data Warehouse gilt als ein sehr aufwendiges und teures Projekt, weshalb es zu organisatorischen und finanziellen Problemen kommen kann. Aus diesem Grund werden meist die Projekte auf mehrere Teilprojekte verteilt, wodurch aus einem Data Warehouse mehrere kleine Data Wa-rehouses entstehen (Markus 2018).
Die unabhängigen Data Marts haben den Vorteil, dass sie schnell, einfach und kosten-günstig entwickelt werden können. Aufgrund der unabhängigen Entwicklung der Data Marts herrschen wenig bis gar keine Zusammenhänge zwischen den verschiedenen Abteilungen (Ariyachandra 2004, S. 29 f.). Zudem wächst der Aufwand proportional zur Anzahl der Data Marts und es ist keine unternehmensweite Analyse möglich (Rahm 2018, S. 13). Auf lange Sicht betrachtet kann es dazu führen, dass unabhängi-ge Data Marts aufgrund von höheren Entwicklungs- und Wartungsaufwandskosten sowie doppelten Software- und Hardwareinfrastrukturen teurer werden. Die unabhän-gigen Data Marts bringen zwar Vorteile in der leichten Entwicklung, schnelle Ergebnis-se und niedrige Kosten in der Entwicklungsphase, bieten jedoch nur eine zerfallene Umgebung bei der Entscheidungshilfe (Ariyachandra 2004, S. 29 f.).
Bei der Entwicklung einer Data-Bus-Architektur werden bestimmte Data Marts anei-nander angepasst und als gemeinsame Dimension dargestellt. Um herauszufinden, welche Data Marts miteinander verknüpft werden sollen, wird eine unternehmensweite Analyse durchgeführt, die im Vergleich zu der EDW-Architektur weniger Zeit in An-spruch nimmt. Die daraus resultierenden Data-Busses ergeben zusammen die Master Suite und somit die Datenbank. Der Vorteil dieser Form der Architektur ist, dass die wichtigsten Verknüpfungen in kurzer Zeit entstehen können (Hackney 2000, S. 2). Zudem ist sie die kostengünstigere Alternative zur EDW-Architektur, da die unterneh-mensweite Analyse weniger aufwendig ist, die Implementierung schneller stattfindet und die Einführung in mehrere Subprojekte unterteilt werden kann, die nur bedingt voneinander abhängig entwickelt werden müssen (Ariyachandra 2004, S. 1).
Allerdings handelt es sich bei der Data-Mart-Bus-Architektur mehr um eine Informati-onssammlung, die nicht in der Lage ist, Informationen richtig zu analysieren und so höhere Mehrwerte zu generieren (Hackney 2000). Sie beschäftigt sich ebenfalls nicht mit der Prozesssteuerung und trägt nicht viel zur Konnektivität bei. Überdies besteht die Möglichkeit, dass nicht unbedingt alle Daten geliefert werden, die für Managemen-tentscheidungen notwendig sind (Firestone 2002, S. 5).
Bei der Enterprise-Data-Warehouse-Architektur wird zunächst eine sehr aufwendige Unternehmensanalyse durchgeführt, daraufhin eine zentrale Datenbank für das ganze Unternehmen erstellt und dazu mehrere Data Marts, die von dieser Datenbank abhän-gig sind. Diese Marts können nach Abteilungen sortiert sein. In die Data Marts werden immer zunächst die Daten aus der zentralen Datenbank geladen. Im nächsten Schritt werden weitere detaillierte Informationen in die Data Marts gepflegt, um die zentrale Datenbank auszulasten. Diese Kombination macht die EDW-Architektur zu einer sehr praktikablen Lösung, die jedoch mit hohen Kosten und einem großen Zeitaufwand verbunden ist (Ariyachandra 2004, S. 33–35).
Die föderierte Data-Warehouse-Architektur hat den Vorteil, dass unterschiedliche be-stehende Entscheidungsunterstützungsarchitekturen, die in der Organisation vorhan-den sind, miteinander kombiniert und Datensilos vermieden werden. Es werden keine neuen Datenbanken erstellt, sondern Metriken und Kennzahlen, die verschiedene In-formationen miteinander verknüpfen. Der Nachteil dieser Architekturform ist, dass in der Praxis die Datenintegration von der Qualität der Daten abhängt und die Kombina-tion der Daten aufgrund von verschiedenen Datenstrukturen und Hardware- und Soft-ware-Infrastrukturen unterschiedlich ist (Ariyachandra 2004, S. 36–38).
Im Laufe der Zeit haben sich die einzelnen Architekturen weiterentwickelt und ähneln sich, beispielsweise haben sich in der EDW-Architektur dimensionale Data Marts entwi-ckelt, die in der Busarchitektur eine zentrale Rolle einnehmen. Aus den Daten der oben genannten Studie lässt sich entnehmen, dass die EDW-Architektur und die zent-rale Data-Warehouse-Architektur der Busarchitektur in den Erfolgsmetriken ähneln und es schwierig ist, eine der Architekturen als die überzeugendste Architektur zu wählen (Ariyachandra und Watson 2006, S. 6). Jedes Unternehmen muss dazu indivi-duell Kosten und Nutzen abwägen.
Hackney schreibt, dass eine föderierte Datenbank für ein Unternehmen nur dann Sinn macht, wenn im Unternehmen schon mehrere Systeme wie EDW, architektonische und nicht-architektonische Datenbanken existieren und man diese miteinander mithilfe von Metriken verknüpfen möchte (2000, S. 2).
Die Bus-Architektur wäre eine schnelle, kostengünstige Möglichkeit, in der innerhalb der Master Suite Dimensionen in Form von Data Bus erstellt und verschiedene Data Marts individuell aneinander angepasst werden. Der Vorteil dabei ist, dass nicht alle Daten in der dritten Normalform gespeichert und miteinander verknüpft werden, so-dass Zeit und Geld gespart werden. Als Alternative stehen eine effiziente und teure EDW-Architektur und eine Data-Mart-Architektur (Ariyachandra 2004, S. 32).
In Bezug auf die Bondatenanalyse im Lebensmitteleinzelhandel sind unabhängige Data Marts weniger geeignet, da sie auf Dauer teurer als die Alternativen sein werden. Grund dafür ist die mehrfache Entwicklung sowie die Infrastruktur und Hardware, die unabhängige Data Marts erfordern (Ariyachandra 2004, S. 30). Da Lebensmitteleinzel-händler oft sehr viele Filialen besitzen, würden die Kosten enorm wachsen.
Eine EDW-Architektur könnte nach einer umfangreichen Nutzenanalyse für große und mittelständische Unternehmen und Lebensmitteleinzelhandelsketten durchaus sinnvoll sein, um so eine vernetzte, effektive und flexible Lösung zu erhalten, bei der kaum unabhängige Data Marts entstehen können (Hackney 2000, S. 2). Zudem werden bei einer EDW-Architektur, im Gegensatz zur Data-Mart-Bus-Architektur, auch verschie-dene Analysemöglichkeiten unterstützt (Eckerson 2002).
Falls jedoch der Kosten- und Zeitfaktor relevant sind und es keiner kompletten Ver-netzung der Daten und Abteilungen bedarf, könnte sich die Data-Mart-Bus-Architektur als mittel- bis langfristige Lösung eignen, um so die wichtigsten Anfragen abzuwickeln (Hackney 2000, S. 2).
OLAP- und OLTP-Technologie
Das Konzept des Data Warehouse enthält sehr viele Daten, die es effektiv und effizient zu nutzen gilt. Unterstützt wird dieses Ziel mit der Online-Analytical-Processing-Softwaretechnologie. OLAP bietet Managern und qualifizierten Mitarbeitern aus den Fachabteilungen eine Navigationsmöglichkeit innerhalb der Datenmengen (Gabriel et al. 2009, S. 52 f.). Zudem wird mithilfe dieser Zugriffskomponente der Zugriff auf die relevanten Informationen innerhalb des Datenmaterials gewährt. Es ist ein wichtiges Werkzeug bei der Analyse entscheidungsrelevanter Informationen (Gabriel et al. 2000, S. 75). Ferner lassen sich Werkzeuge aus den Produktionsdatenbanken für die Verwal-tung und für die Abfrage von zentralen Data Warehouses verwenden. OLAP bietet den Endbenutzern eine Abfragemethode, mit der ein schneller Zugriff und eine benutzer-freundliche Analyse von Data Marts ermöglicht wird. Überdies zeichnet sich OLAP durch verschiedene Eigenschaften aus, die dem Endbenutzer zugutekommen. Durch die sekundenschnelle Beantwortung von komplexen Abfragen und einer übersichtlich zusammengefassten und visualisierten Ansicht der Ergebnisse ist sie besonders benut-zerfreundlich. Durch die OLAP-Tools ist es möglich, Analysen in größeren Datenmen-gen im Bereich von Giga und Terabytes durchzuführen (Farkisch 2011, S. 23; Lusti 2002, S. 153). Dem Anwender wird die Möglichkeit gegeben, Dimensionen hinzuzufü-gen oder wegzulassen, ohne zuvor das Datenmodell zu durchsuchen. Aus diesem Grund wird OLAP auch als „analysierend und synthetisierend“ bezeichnet (Lusti 2002, S. 153). Da Daten in intuitiver und realitätsnaher Form zur Verfügung gestellt werden, wird OLAP auch als multidimensionale Datenanalyse betrachtet. Die benötigten Daten werden aus dem Data Warehouse herausgefiltert und in den OLAP-Server übernom-men (Gabriel et al. 2000, S. 88). Ein konkretes Beispiel für eine multidimensionale Analyse schaut wie folgt aus:
Eine typische Anwendung findet im Marketing statt, wenn herausgefunden werden soll, wie viel Bruttoumsatz ein bestimmtes Produkt zu einer bestimmten Zeit an einem bestimmten Ort erreicht hat. Bei dieser Informationsnachfrage werden drei Dimensio-nen benötigt: Artikel, Zeit, Vertriebsweg und die Kennzahl Bruttoumsatz. Verbildlicht wird dies mit einem Hyper-Würfel, die zu analysierenden Kennzahlen werden im Wür-fel nach Dimensionen aufgespannt (Totok 2000, S. 56). Der Anwender kann sich in mehreren Dimensionen des Würfels bewegen und einen Schnitt machen, um Informa-tionen zu analysieren und selbstständig Berichte zu erstellen (Gabriel et al. 2000, S. 77 f.). Der Zugriff mit der OLAP-Technologe wird mit Data-Mining-Systemen unter-stützt. Mithilfe der OLAP-Tools werden die Daten in aggregierter oder summierter Form erfasst, zudem ist es möglich, unterschiedliche Aggregationen miteinander zu vergleichen (Farkisch 2011, S. 21).
Das Online Transactional Processing (OLTP) bildet traditionell betrachtet die Basis von Transaktion in Datenbankmanagementsystemen. Transaktionen sind in diesem Zu-sammenhang eine Folge von Datenverarbeitungsbefehlen (Read, Insert, Delete, Up-date). Transaktionen finden innerhalb einer Anwendung statt, welche die Aufgabe hat, eine Basisdatenbank von einem konsistenten Zustand in einen anderen oder densel-ben konsistenten Zustand zu überführen. Im Vergleich zwischen analyseorientierten Data-Warehouse-Systemen (OLAP) und transaktionsorientierten Systemen (OLTP) sind die Anfragen bei OLTP einfach und bei OLAP komplex, dementsprechend sind in analyseorientierten Systemen sehr viele Datensätze und in transaktionsorientierten weniger Datensätze vorhanden (Farkisch 2011, S. 51 f.).
Data Mining
Data Mining bedeutet übersetzt Schürfen oder Graben in Daten. Es lässt sich gut mit dem Graben nach Gold vergleichen, weil die Informationen, die durch das Data Mining oder die Datenmustererkennung erhalten werden, für das Unternehmen sehr wertvoll sind (Alpar 2000, S. 3).
Aufgrund der enormen Speicherung von Daten in jeglichen Vorgängen des Lebens ent-stehen große Datenmengen. Innerhalb dieser großen Datenmengen werden die Bezie-hungen zwischen Daten mit Algorithmen und Computerprogrammen analysiert. Mithil-fe dieser Analysen können bestimmte verborgene wertvolle Muster und Strukturen erkannt werden, die sich als entscheidungsrelevante Informationen darstellen (Gabriel et al. 2009, S. 13). Definiert wird Data Mining wie folgt: „Data Mining ist die Anwen-dung spezifischer Algorithmen zur Extraktion von Mustern aus Daten“ (Fayyad et al. 1996, S. 9).
Bei Data Mining ist es nicht wie in der induktiven Statistik, dass der Ausgangspunkt anhand von vorformulierten und zu überprüfenden Hypothesen dargestellt wird. Es werden nicht als Erstes Hypothesen über die Datenzusammenhänge aufgestellt, son-dern genau umgekehrt. Der Ausgangspunkt liegt in der Erkennung von bestimmten Mustern in den Daten (Gabriel et al. 2009, S. 13).
Mit der herkömmlichen Datenanalyse ist es nicht möglich, diese wertvollen und ver-borgenen Muster und Strukturen in unternehmungsinternen und -externen Datenmen-gen zu identifizieren. Es gibt vier Einsatzbereiche für Data-Mining: Segmentierung, Klassifizierung, Assoziation und Vorhersage.
Segmentierung
Die Hauptaufgabe der Segmentierung ist, die Gemeinsamkeiten und Ähnlichkeiten sowie Unterschiede von Daten aus verschiedenen Datenobjekten zu finden und diese in Klassen und Gruppen zusammenzufassen (Alpar 2000, S. 9 f.). Die Clusteranalyse wird beispielsweise bei der Kundensegmentierung eingesetzt, um den Zielgruppen Dienstleistungen und Produkte zuzuordnen (Gabriel et al. 2009, S. 15). In der Praxis werden z. B. in der Bondatenanalyse die Abhängigkeiten innerhalb bestimmter Kate-gorien analysiert wie Warenkörbe mit Windeln oder innerhalb von hochwertigen Wa-renkörben (Nakhaeizadeh 2013, S. 8).
Klassifizierung
Es gibt eine Menge von Objekten, die zu Klassen gehören, die Aufgabe der Klassifizie-rung ist, die Objekte den richtigen Klassen zuzuordnen. Grundsätzlich werden bei der Klassifizierung zuerst die Klassen bestimmt und danach die Objekte anhand von Ob-jektmerkmalen und Klasseneigenschaften den Klassen zugeordnet. Die Zuordnung erfolgt über ein Modell, in dem Fall der Klassifikator, das mit Regeln gesteuert wird. Beispielsweise wird das Analyseverfahren von der Diskriminanzanalyse, mit künstli-chen neuronalen Netzen oder mit Entscheidungsbäumen unterstützt (Gabriel et al. 2009, S. 15; Alpar 2000, S. 9). Ein Beispiel für die Klassifizierung ist die Beurteilung über die Kreditwürdigkeit eines Kunden in einer Bank. In dem Fall könnte mithilfe zweier Klassen – guter Kunde und schlechter Kunde – der Klassifikator den Kunden zu einer Klasse zuordnen, anhand der Zuordnung kann dann der Kredit genehmigt wer-den oder nicht (Nakhaeizadeh 2013, S. 8).
Assoziation
Unter Assoziation ist in diesem Zusammenhang die Erkennung von Mustern und Ab-hängigkeiten zwischen einzelnen Objekten des Datenbestandes zu verstehen. Es wer-den Beziehungen zwischen verschiedenen Objekten gesucht, indem das gemeinsame Vorkommen von Merkmalswerten in den Datensätzen untersucht wird. Anhand der Häufigkeit und Abhängigkeit der Merkmalswerte werden Assoziationsregeln abgeleitet. Am Ende der Analyse können Aussagen über die Wahrscheinlichkeit eines Eintritts ei-nes Ereignisses getroffen werden (Gabriel et al. 2009, S. 15 ; Alpar 2000, S. 10). Ein Beispiel für ein Ergebnis einer Assoziationsregel ist, wenn beispielsweise ein Kunde Chips und Bier kauft, er mit einer Wahrscheinlichkeit von 85 % auch Salzstangen in seinen Warenkorb legt (Gabriel et al. 2009, S. 15). Ein weiteres Beispiel ist, wenn ein Kunde Diätjoghurt kauft, auch Diätmarmelade einkauft. Auch Aussagen über einen längeren Zeitraum können getroffen werden, z. B., dass nach einem Kauf einer Spiel-konsole verschiedene Spiele gekauft werden (Alpar 2000, S. 9).
Vorhersage
Die Prognose ähnelt stark der Klassifikation, nur werden bei der Prognose nummeri-sche Werte vorhergesagt und bei der Klassifikation symbolische Werte (Nakhaeizadeh 2013, S. 9).
Mithilfe von Analyseverfahren und Regressionsanalysen sollen Ausschlüsse über kom-mende unbekannte Merkmalswerte gegeben werden (Gabriel et al. 2009, S. 16). Ein Beispiel für die Vorhersage ist, dass im Einzelhandel anhand von Werten zu Merkma-len, sprich den Umsätzen aus den vorherigen Monaten, eine Prognose zu dem Umsatz für den folgenden Monat gegeben werden kann (Nakhaeizadeh 2013, S. 9).
Datenintegration
Das Grundziel der Datenbanksysteme, das von Anfang an verfolgt wird und einer der Gründe für die Entwicklung ist, ist die Integration von Datenbeständen, um einen ein-heitlichen Zugriff zu schaffen (Conrad 1997, S. 2 f.).
Die Daten sind nicht mehr an einem physikalischen Ort, sie sind weltweit verteilt, sie fallen weltweit an und werden lokal gespeichert. In der Praxis ist es oft der Fall, dass für den genauen Überblick der Daten mehrere Datenquellen gebraucht werden. Die Informationen aus mehreren Datenquellen werden zusammengeführt, um diese ein-heitlich darzustellen. Wenn ein Unternehmen beispielsweise den kompletten Umsatz von Bananen in allen Filialen weltweit herausstellen möchte, müssen die Quellen zu-sammengeführt werden und die lokalen Daten werden integriert. Es kommt während der Datenintegration zu verschiedenen Problemen, zum einen, dass die Quellen ver-teilt auf verschiedenen Rechnern an verschiedenen Standorten sind, dieses Problem ist durch die immer besser werdende Vernetzung gering (Bleiholder und Schmid 2008, S. 121–126). Ein weiteres Problem sind die Autonomie und die Heterogenität der Da-ten. Die Autonomie der Quellen bezieht sich darauf, dass Quellen von unterschiedli-chen Personen und unabhängig voneinander erstellt und gepflegt werden. Bei der He-terogenität werden verschiedenen Faktoren voneinander unterschieden. Die techni-sche Heterogenität nimmt Bezug darauf, dass verschieden Quellen auf verschiedenen Hardwaresystemen laufen und mit unterschiedlicher Software betrieben werden. Das Problem der strukturellen Heterogenität bezieht sich auf die Modellierung desselben Sachverhaltes in unterschiedlichen Konzepten eines Datenmodells. Die semantische Heterogenität steht im Zusammenhang mit dem Überlappen von modellierten Sach-verhalten. Es muss auch die Heterogenität auf Datenebene gelöst werden, da es in den gespeicherten Daten zu Überlappungen kommen kann. Das Schema-Matching-Verfahren dient zur Ermittlung von Übereinstimmungen zwischen Elementen verschie-dener Schemata (Bleiholder und Schmid 2008, S. 121 f.). Die Datenintegration ge-schieht über den Prozess ETL, Daten aus verschieden Quellsystemen werden mitei-nander verbunden (Humm und Wietek 2005, S. 9).
Um die Aspekte der Datenintegration nachzuvollziehen, müssen die horizontale und die vertikale Integration voneinander unterschieden werden. Abbildung 10 beschreibt ihre Differenzierung.
Horizontale Integration
Die horizontale Integration fasst die Daten, die bei einer Wertschöpfungskette ver-wendet werden, zusammen. Jegliche Abteilungen und Funktionen einer Wertschöp-fungskette sollen dieselben Daten verwenden. Von der Beschaffung, Lagerhaltung, Produktion, dem Kundendienst, Vertrieb bis hin zum Versand sollen dieselben Daten genutzt werden. Ein Beispiel aus der Praxis ist, dass im Controlling Daten aus der Pro-duktion für Analysen und Planungen verwendet werden. Zu der horizontalen Integrati-on gehört auch die Einbindung von unterschiedlichen IT-Systemen und die Einbindung von Kunden und Lieferanten (Gubler 2014, S. 1).
In der Praxis ist die horizontale Datenintegration weit verbreitet. Der Grund dafür liegt in der Entwicklung, die meisten Anwendungen werden isoliert voneinander entwickelt (Behme und Muksch 2001, S. 13). Aufgrund der mangelnden stattfindenden horizon-talen Datenintegration sind in der Praxis meist manuell aufbereitete Daten aus den operationalen. Datenverarbeitungssystemen anzutreffen (Behme und Muksch 2001, S. 13).
Vertikale Integration
Die vertikale Integration aggregiert Datensätze auf einer höheren Stufe, sodass Auf-gaben mit verschiedenen Betrachtungszeiträumen und -umfängen zusammengefasst werden, um eine einheitliche Datenbasis zu schaffen. Die vertikale Datenintegration bietet eine Sicherung der Datenversorgung von Administrations- und Dispositionssys-temen und für die Unternehmensführungssysteme. Die Umsetzung der vertikalen Da-tenintegration findet fast gar nicht statt, auch hier liegt der Grund darin, dass Anwen-dungen isoliert voneinander entwickelt werden (Behme und Muksch 2001, S. 13).
Handhabung von Datenmassen
Bei der Handhabung von größeren Mengen an Daten spielt die Datenqualität eine wichtige Rolle. In der Praxis kann es schnell zu Datenfehlern kommen, wodurch die Datenqualität beeinträchtigt wird. Eine falsche Eingabe von Produktcodes oder eine falsche Angabe von Einheiten bei Messreihen sorgen für Datenfehler. Auch bei der Ein-gabe von Kundendaten passieren in der Praxis schnell Inkorrektheiten, die zu Daten-fehlern führen und somit für wirtschaftliche Konsequenzen verantwortlich sind. Grund-legende Datenfehler entstehen bei der Eingabe der Daten; durch eine manuelle Da-teneingabe bzw. durch eine automatische Datenerhebung können diese behoben wer-den. Bei der Erhebung von Daten können programmierte Funktionen wie das „Erzwin-gen“ einer Eingabe einer E-Mail-Adresse zur Behebung von Datenfehlern führen. Auch die Einhaltung von Formaten in der Eingabe von Geburtstagen oder die Reihenfolge von erst Nachname, dann Vorname, oder erst Vorname, dann Nachname führen zu einer besseren Datenqualität, da eine Konsistenz der Datensätze sichergestellt wird. Eine weitere Möglichkeit, mit der die Datenfehler erkannt und behoben werden kön-nen, ist die Erkennung von doppelten Datensätzen. Diese können durch Algorithmen, die die Namensähnlichkeit, Adressähnlichkeit und die Gesamtähnlichkeit prüfen, er-kannt und entsprechen gelöscht oder zusammengeführt werden (Naumann 2006, S. 28 f.). Das Auffinden von widersprüchlichen und unvollständigen Daten oder Dupli-katen im Datenbestand sowie veraltete Daten sind Gründe für Qualitätsmängel in den Quelldaten (Bauer 2013, S. 40). Die Ansprüche an die Datenqualität können nach Analyseverfahren variieren, im Bereich Kundenverhalten ist beispielsweise die Zeitnä-he und die Genauigkeit der Datenqualität nicht so wichtig wie im Bankenbereich (Bauer 2013, S. 45).
Recent Comments