In-Memory-Datenbanken
Daten durchlaufen ein komplexes Datenmodell und Data Warehouses bis die ge-wünschten Berichte zur Verfügung stehen, doch dies reicht den Unternehmen nicht mehr aus. Es wird nach einer größeren Transparenz über die Handlungen verlangt und das am besten in Echtzeit (Berg und Silvia 2013, S. 24). Entscheidungsträger möchten mit der Transparenz in Echtzeit auf aktuelle Geschehnisse und Marktveränderungen reagieren können und nicht erst, wenn sie im Datenspeicher sind, was bei Data-Warehouse-Systemen bis zu zwei Wochen dauern kann (Silvia et al. 2017, S. 22).
In-Memory-Datenbanken hingegen arbeiten durch ihre Technologie deutlich schneller und können Datenanalysen erheblich vereinfachen. Es handelt sich bei In-Memory-Datenbanken um ein Datenbanken, die Datenanalysen in Echtzeit ermöglichen. Im Gegensatz zu herkömmlichen Datenspeichern, wie in einem Data Warehouse, in denen die Daten auf Festplatten gespeichert werden, speichern In-Memory-Datenbanken die Daten permanent im Hauptspeicher. Das hat den Vorteil, dass der Datenzugriff schnel-ler erfolgen kann, da keine Input/Output-Zugriffe auf die Festplatte erfolgen (Plattner und Zeier 2012, S. 10–13). Mit In-Memory-Datenbanken ist es möglich, per Knopf-druck innerhalb einer Sekunde Daten abzufragen. Bei traditionellen Datenbanken ist dies aufgrund der Lese- und Schreibgeschwindigkeiten nicht möglich. Die Daten liegen nicht an verschiedenen Orten wie bei traditionellen Datenbanken, sodass es nicht zu Aktualitätsunterschieden kommen kann (Funk et al. 2012, S. 112). Mit In-Memory-Datenbanken können Vorgänge bis in Produkt- und Kundenebene genauer analysiert werden, ebenso wird ermöglicht, tagesaktuelle Analysen von einzelnen Kunden oder Produkten durchzuführen. Es ist nicht mehr nötig, Daten in operative Datenbanken und Data-Warehouse-Systeme zu trennen, die transaktionale und die analytische An-wendung können auf demselben Datenbestand erfolgen (Loos et al. 2011, S. 383). Das gibt den betrieblichen Anwendungssystemen ein spezialisiertes Datenmanage-ment, so können diese klassische Einzelsatzverarbeitungen und zeitgleich Massenver-arbeitungen mit analytischen Funktionen von Daten durchführen (Loos et al. 2011, S. 385). Die Preissenkung für Speicher, insbesondere für Hauptspeicher (Arbeitsspei-cher, Random Access Memory, RAM), und die Verfügbarkeit von 64-bit-Prozessoren und verteilt arbeitenden Multi-Core-Servern macht die In-Memory-Datenbank attrakti-ver und die Massenspeicherung von Unternehmensdaten realistischer (Plattner und Zeier 2012, S. 9 f.). Da auf dem Multicore Chip mehrere Hauptprozessoren vorhanden sind, können mehrere Prozesse parallel laufen (Gluchowski und Chamoni 2016, S. 189; Litzel 2017).
ETL-Prozesse sind bei In-Memory-Datenbanken nicht mehr nötig, sodass es nicht mehr zur Transformation und zu Übertragungsfehlern kommen kann, demnach ist die Datenqualität bei In-Memory besser.
Probleme von In-Memory-Datenbanken
Die dauerhafte Speicherung und Persistenz von Daten führt zu Problemen, da In-Memory-Datenbanken mit flüchtigem RAM arbeiten. Dementsprechend kann es im Fall eines Stromausfalls zum Verlust von Daten kommen. Um dies zu vermeiden, müssen entsprechende Absicherungsmaßnahmen vorgenommen werden. Eine der Methoden zur Absicherung sind Schnappschussdateien oder Schnappschusssicherungen der Da-tenbank, zu verschiedenen Zeitpunkten wird der Zustand der In-Memory-Datenbank gespeichert. Des weiteren besteht die Möglichkeit, die Änderungen in der Datenbank bzw. in den Daten über entsprechende Log-Dateien im nichtflüchtigen Speicher zu speichern. In dieser Datei sind alle Veränderungen in der Datenbank aufgezeichnet und dokumentiert werden. Falls es zum Verlust der Daten aufgrund eines Stromaus-falls oder technischer Probleme kommt, kann mithilfe der Schnappschussdatei und der Protokolldatei der Zustand der Datenbank wiederherstellt werden (Kramer und Esch 2018, S. 33; Litzel 2017).
Das In-Memory-Datenmanagement bietet ein großes Potenzial für die betriebswirt-schaftliche Software, ist aber mit großem Aufwand und hohen Kosten verbunden. Bei dem Einsatz von In-Memory-Datenbanken ergeben sich Anforderungen im technischen und betriebswirtschaftlichen Bereich. Betriebswirtschaftliche Anforderungen beziehen sich auf einmalige oder laufende Kosten (Kramer und Esch 2018, S. 37). Für die tech-nischen Anforderungen werden vier Kriterien aufgeführt: Das erste Kriterium ist die Echtzeitanalyse, da innerhalb von wenigen Sekunden das System Daten aus verschie-den Datenbanken und unsortierten Strukturen analysieren muss. Die Echtzeitanalyse ermöglicht, neue Daten zu erfassen, sie schnellstmöglich auszuwerten, aber auch Be-rechnungen und Reportings durchzuführen. Weitere Anforderungen, die sich für die IMDB ergibt, ist die Reaktionszeit. Durch die Speicherung der Daten im Hauptspeicher ist es möglich, innerhalb von Sekunden auf Datenanfragen zu reagieren. Eine andere Anforderung ist die Verfügbarkeit der Daten. Selbst bei einem Stromausfall, einem Systemausfall, einem Fehler oder einem Schaden müssen die Daten zur Verfügung stehen. Es ergibt sich ebenfalls die Anforderung an die Skalierbarkeit. Sie beschreibt, inwieweit sich die Leistungen eines Systems durch das Hinzufügen von Systemres-sourcen anpassen lässt (Kramer und Esch 2018, S. 37 f.).
Neben den echten In-Memory-Datenbanken gibt es In-Memory-Computing. Bei Daten-banken mit Caching-Mechanismus befindet sich der Hauptspeicher der Daten auf der Festplatte. Die Änderungen und Aktualisierungen der Daten finden beim Caching auf der Festplattenebene statt. Bei Datenbanken mit Caching wird mit Schnappschussda-teien gearbeitet, diese beschleunigen die Verarbeitungszeit. Dennoch weisen echte In-Memory-Datenbanken eine höhere Geschwindigkeit auf. Die zu persistierende Daten-menge in Unternehmen steigen von Tag zu Tag an und die Preise für Arbeitsspeicher sinken stetig, was wiederum den Gebrauch von In-Memory-Verarbeitungen attraktiver macht (Berg und Silvia 2013, S. 21).
Um das Ziel, in Echtzeit oder nahezu in Echtzeit Informationen zu verarbeiten, zu er-reichen, verfolgt In-Memory-Computing den Grundsatz „Der Datenzugriff wird be-schleunigt und Datenbewegungen werden minimiert“ (Silvia et al. 2017, S. 23). Ein schnellerer Zugriff auf die Daten wird durch den Hauptspeicher RAM ermöglicht, der Zugriff auf einen RAM-Speicher kann 100.000 Mal schneller als auf einer Festplatte sein (Silvia et al. 2017, S. 21–23).
Heutzutage sind Unternehmen von Echtzeitinformationen abhängig, weil sie immer wieder gefordert werden, Echtzeitentscheidungen zu treffen (Berg und Silvia 2013, S. 24).
Szenario im Einzelhandel
Mithilfe von In-Memory-Computing und der damit verbundenen Möglichkeit, in Echt-zeit auf die großen Datenmengen zuzugreifen und diese zu prüfen, wird ein Szenario wie unten dargestellt realistischer. Dies liegt daran, dass durch das Verschieben der Daten von der Festplatte auf den Hauptspeicher Zugriffszeiten erheblich verkürzt wer-den.
Ein vorstellbares Szenario ist, dass das Echtzeitverhalten eines Kunden im Laden oder auf einer Webseite vom Einzelhändler beobachtet wird und eine direkte Reaktion da-rauffolgt. Dabei werden die Daten aus dem Echtzeitverhalten mit den Daten aus dem historischen Kundenverhalten kombiniert, hinzukommen Daten aus den sozialen Netzwerken, beispielsweise Gefällt-mir-Angaben auf Facebook. Mithilfe der Echtzeit-analyse kann darauf schnellstmöglich reagiert werden, indem der Kunde passende Gutscheine oder Coupons für die Produkte, die er sich gerade anschaut, auf sein Mo-biltelefon geschickt bekommt (Silvia et al. 2017, S. 22 f.)
Mit der Technik In-Memory-Computing werden integrierte Engines zur Berechnung verwendet. Somit ist es nicht mehr notwendig, ein mehrstufiges Datenmodell auf sechs Ebenen mit vorbelegten oder Roll-up-Daten zu erstellen. Anhand dieser Aspekte ist es mit In-Memory-Computing möglich, die benötigte Zeit für die Beschaffung, Be-rechnung bis hin zur Präsentation zu minimieren. Früher hat die Erstellung eines Be-richtes eine Stunde gedauert, nun ist ein Bericht in wenigen Sekunden erstellt. Die Daten werden deutlich stärker komprimiert, damit eine Datenredundanz vermieden wird (Silvia et al. 2017, S. 23–25).
Die Art und Weise, wie Menschen mit Informationen umgehen, hat sich verändert. Aus diesem Grund ist es immer wichtiger geworden, dass auf Daten so schnell wie mög-lich, am besten sofort, zugegriffen werden kann (Silvia et al. 2017, S. 27).
In-Memory-Datenbanken im Lebensmittelhandel
Um einen Einblick in das große Volumen an Daten, die im Lebensmitteleinzelhandel tatsächlich genutzt und gespeichert werden, zu bekommen, wird ein Beispiel anhand der EDEKA-Gruppe zur Veranschaulichung vorgestellt. Das Lunar-Programm ist ein Programm, das von EDEKA gefördert wird, um eine Softwarelösung für den Lebens-mittelhandel zu entwickeln. Im Fokus stehen der Einzelhandel, der Großhandel und die EDEKA-Zentrale, die miteinander verzahnt werden sollen. Das EDEKA-Daten-Management (EDM) ist die Basis der Systemlandschaft und gleichzeitig die Sammel- und Pflegestelle für jegliche Daten, die in den deutschlandweit verteilten Märkten auf-zufinden sind (Schütte 2011, S. 1–10).
Handelsunternehmen müssen den Bedarf an Informationen in Einzelhandelsketten, in den Schnittstellen zum Großhandel sowie die Anforderung der Zentralbereiche abde-cken. Im EDM sind alle relevanten Informationen über die Artikel wie die Mengenein-heit und Initialinformationen enthalten. Das EDM beinhaltet lediglich die Daten für EDEKA, sprich, von nur einer Lebensmitteleinzelhandelskette. Es werden 1,5 Millionen Stammdaten aufgewiesen, zudem kommen Mengeneinheiten je Artikel und mehrere Hundert Attribute je Artikel hinzu. In der Zentralregulierung werden 23 Millionen Bele-ge pro Jahr mit ca. 400 Mio. Belegpositionen gebucht (Schütte 2011, S. 3). Im Bereich Großhandel der EDEKA entstehen ebenfalls große Mengen an Daten, zum einen durch die Beschaffung und zum anderen durch die Belieferung der einzelnen selbstständigen Einzelhändler und der regiebetriebenen Märkte. Aufgrund der mehr als 50 Lagerstand-orte und verschiedener Belieferungsformen entsteht bei der Kommissionierung der Ware und im Warenausgang eine große Menge an Daten. Anzumerken ist, dass in den Hauptarbeitszeiten eine enorme Verarbeitungsgeschwindigkeit erwartet wird (Schütte 2011, S. 1–10).
Allein im Bereich Bondaten ergeben sich für den Einzelhandel täglich einhundert Millio-nen Datensätze, In-Memory-Datenbanken eignen sich aus diesem Grund sehr gut für den Einzelhandel. Sie bieten dem Einzelhandel neue Funktionen und Möglichkeiten an. Optimierungsläufe verlaufen mit traditioneller IT innerhalb einer Forecast- und Replenishment Engine, diese erfolgen mit traditionellen Datenbankmanagementsyste-men über Nacht, nachdem der Bestand über die Wareneingänge und Abverkäufe ein-getragen wurde. Diese Berechnungen können je nach Betrieb und Sortiment Stunden dauern. Es findet im Nachhinein eine Nachbearbeitung des Bestands statt, um Abver-kaufsausreißer zu prüfen. Mit der herkömmlichen IT ist es nicht möglich, mit der neu erfassten Datensituation einen erneuten Optimierungslauf durchzuführen, da diese zu zeitintensiv ist und die Zeit dafür nicht zur Verfügung steht. Das bedeutet, dass die Bestellmenge nicht optimiert werden kann, sondern nur um die neuen Werte korrigiert wird. Mit In-Memory-Datenbanken würde sich dies aufgrund der schnellen Verarbeitung der Daten anders gestalten, da es nach der Korrektur der Daten möglich wäre, mit Restriktionsnetzen einen erneuten Optimierungslauf durchzuführen (Schütte 2011,S. 6 f.). Schütte leitet aus diesem Beispiel eine allgemeine Regel zur Identifikati-on von Einsatzpotenzial von In-Memory-Technologie ab: „Betriebswirtschaftliche Op-timierungskalküle werden auch für datenintensivere Anwendungen einsetzbar, was im Handel in vielen Situationen ein erhebliches Optimierungspotenzial ergibt“ (2011, S. 7). Ein weiteres Beispiel beschreibt Schütte aus dem Bereich Aktionen. Entscheidun-gen für Aktionen im Handelsunternehmen werden auf der Basis von Wochenumsätzen und mit der taktischen Planungsebene nach Thema und Warenbereich geplant. Aus systemtechnischer Sicht werden einige Wochen vor dem Aktionsbeginn die Artikel an-gelegt. In der herkömmlichen IT werden die Abverkaufsdaten im DW oder BI hinter-legt, die Festlegung der Artikel findet in einem transaktionalen System statt. Dies bringt den Nachteil mit sich, dass eine künstliche Trennung der betriebswirtschaftli-chen Realität entsteht. Diese Trennung entsteht aus technischen Gründen; durch die In-Memory-Technologie könnten sich diese Trennung auflösen und transaktionale Auf-gaben und analytische Aufgaben simultan ablaufen (Schütte 2011, S. 7). Ein weiteres Beispiel für eine praktische Umsetzung, das aufgrund der hohen Datenmenge nur durch eine In-Memory-Technologie umsetzbar wäre, ist die Simulation des gesamten Wettbewerbs im eigenen System. In den USA wird dies bereits von einigen Handelsun-ternehmen umgesetzt, es findet eine Absatz- und Umsatzanalyse unter „Business Ana-lytics“ statt. Die entsprechenden Handelsunternehmen rufen auf ihren eigenen Syste-men alle Artikelpreise der Wettbewerber auf. Daraus resultiert ein exponentielles Da-tenwachstum und dass die Umsetzung ausschließlich nur mit der In-Memory-Technologie möglich ist (Schütte 2011, S. 7 f.).
In-Memory-Datenbanken ermöglichen diesen Ablauf in Echtzeit. Sobald große Mengen an Daten vorliegen, ist es wichtig, schnelle Datenanalysen durchführen zu können. Mit In-Memory-Datenbanken wird die Datenanalyse beschleunigt und Abfragezeiten sind präzise berechenbar. Wenn Anforderungen ohne die Geschwindigkeit der Datenverar-beitung nicht erfüllbar sind oder wenn Anforderungen von Anwendern erst bei einer höheren Verarbeitungsgeschwindigkeit akzeptiert werden, liegt die Geschwindigkeit im Fokus und es entstehen neue Herausforderungen für die Datenverarbeitung. Mit der aktuellen SAP BI-Architektur ist es nicht möglich, die Umsatz- und Absatzauswertung sämtlicher Regionen abzubilden (Schütte 2011, S. 6).
Von der In-Memory-Technologie wird erwartet, dass nicht nur die Applikationsschicht unterstützt wird, sondern auch die technologische Schicht. Beispielsweise wäre eine Unterstützung beim Releasewechsel von Vorteil. Einzelhändler wie EDEKA, Nestlè oder Metro wechseln in regelmäßigen Abständen die Releases, dieser Vorgang wird auf-grund des hohen Datenvolumens immer anspruchsvoller (Schütte 2011, S. 9).
Customer-Experience-Reference-Architecture
Die Kundenerfahrung zählt zu den wichtigsten Unterscheidungsmerkmalen und Trei-bern eines Unternehmenswertes. Abbildung 11 zeigt das Referenzmodell von Oracle zu Kundenerfahrungen und beschreibt die verschiedenen Kanäle, die in einem Unterneh-men angewandt werden, um die Kundenerfahrung in einem Unternehmen zu unter-stützen. In diesem Modell stehen neben weiteren Punkten vor allem die konsistente und genaue Echtzeitansicht aller relevanten Informationen, die in einem Unternehmen entstehen, im Fokus (Bob 2014, S. 5).
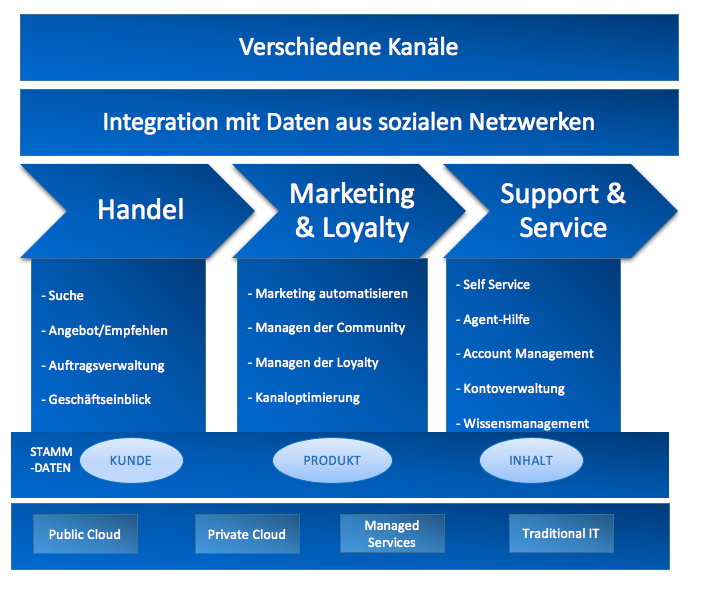
Abbildung 11: Customer-Experience-Reference-Architecture
Quelle: In Anlehnung an (Bob 2014, S. 6)
Abbildung 11 stellt gleichzeitig die konzeptionelle Ansicht auf das Customer-Experience-Reference-Architecture-Modell dar. Das Modell zeigt die verschiedenen Kanäle, die ein Unternehmen beim Einkaufen der Kunden einsetzt. Moderne Refe-renzmodelle für die Kundenerfahrung beinhalten die Integration von Daten aus den sozialen Netzwerken. Diese spielen in diesem Modell eine wichtige Rolle und sind sehr wichtig für Customer-Experience-Lösungen. In der Abbildung werden die Hauptge-schäftsfunktionen Handel, Marketing, Service und Unterstützung dargestellt. Diese Funktionsbereiche müssen im Customer-Experience-Lifecycle immer bereitstehen.
Im Funktionsbereich Handel ist die Hauptaufgabe der Verkauf eines Produktes oder einer Dienstleistung an einen Kunden. Um diesen Prozess optimal zu gestalten, muss dem Kunden die Funktion Suchen/Durchsuchen angeboten werden, sodass er die Mög-lichkeit hat, in einem Produktkatalog nach seinem Produkt zu suchen. Dabei ist wich-tig, dass dem Kunden eine Navigation durch den Katalog geboten wird, damit er seine Produkte schnellstmöglich findet. Zu einem erfolgreichen und überzeugenden Ein-kaufserlebnis gehören auch die Gestaltung von Angeboten und die Empfehlung. Durch den Gebrauch von Echtzeit und personalisierten Daten ist es möglich, in Echtzeit rele-vante und personalisierte Angebote zu machen. Zu der Funktion Angebote und Emp-fehlung gehört, dem Kunden Einblicke in die Geschäfte zu geben, ihm soll der Zugang zu Informationen über seine vergangenen Verhaltensweisen und Käufe von anderen Kunden mit ähnlichen Interessen gewährt werden. Durch den Geschäftseinblick kann bestimmt werden, dass bestimmte Produkte für ein bestimmtes Kundenprofil wahr-scheinlich von hohem Interesse ist. Auf solche Informationen kann mit entsprechen-den Werbekampagnen wie Coupons oder Benachrichtigungen durch Apps direkt rea-giert werden. Im Funktionsbereich Handel wird auch die Auftragsverwaltung aufgegrif-fen, die Bestellungen müssen effizient und genau sein. Zudem ist relevant, dass alle Informationen aus den Interaktionen mit dem Kunden gesammelt werden und für die Echtzeitanalyse zur Verfügung gestellt werden (Bob 2014,S. 6 f.).
Ein weiterer Teil der Hauptgeschäftsfunktionen, die in Abbildung 11 dargestellt wer-den, sind Marketing und Loyalität. Im Bereich Marketing ist das Ziel, Kunden zu gewinnen, sodass die Nachfrage nach den Produkten und Dienstleistungen eines Un-ternehmens steigt. Diese Funktion wird in vier Punkte unterteilt. Dazu gehört zum ei-nen die Automatisierung des Marketings, sodass zielgerichtete Marketingkampagnen über alle Kanäle hinweg stattfinden können. Community Management gehört ebenfalls dazu, dabei soll eine Community entstehen, in der dem Kunden die Möglichkeit gege-ben wird, ein Feedback über die Produkte zu geben und Bewertungen von anderen Kunden zu lesen. Ziel dabei ist, dass der Kunde das Unternehmen und seine Produkte anderen empfiehlt. Mithilfe von Business-Intelligence-Tools ist es dem Unternehmen möglich, anhand einer Analyse der Daten auf Kundentrends und den Wettbewerb zu reagieren. Der nächste Punkt in Abbildung 11 ist das Loyalty Management, das bedeu-tet, dass das integrierte Loyalitätsmanagement erreichen soll, dass Kunden zu einem erneuten Einkauf motiviert und belohnt werden. Klassisch gibt es Kundenprogramm-karten, mit denen Punkte gesammelt werden können. Als letzter Punkt wird in der Abbildung die Kanaloptimierung dargestellt. Die einzelnen Kanäle müssen optimiert werden, dabei sollen die Stärken von einzelnen Kanälen dazu genutzt werden, die Schwächen der anderen Kanäle auszugleichen (Bob 2014, S. 7).
Der letzte Punkt der drei Hauptgeschäftsfunktionen beinhaltet den Support und Service. In diesem Aufgabenfeld soll dem Kunden ein Service geboten werden, in dem ihm Produktinformationen zugänglich gemacht und Fehler behoben werden oder ihm bei Reklamationen geholfen wird. Genauer unterteilt entstehen fünf Kategorien zum Service. Self Service als eine der Kategorien ist eine Kundenbetreuung mit weniger Kosten, die für ein gutes Kundenerlebnis sorgt. Unternehmen müssen einen großen Self Service bereitstellen. Sobald die im Self Service bereitgestellten Hilfen nicht aus-reichen, muss dem Kunden eine reale Person, der Agent, helfen. Agent Assists sollen für die Kunden über einen Chat, Telefone und über E-Mail zur Verfügung stehen. Da-mit dem Kunden ein zufriedenstellender Service angeboten werden kann, ist ein Ac-count Management, also die Kontoverwaltung, notwendig. Das Wissensmanagement gehört ebenfalls zum Support und Service. Um den Kundenservice aufrechtzuerhalten und zu verbessern, müssen Produktunterstützungsinformationen gesammelt, korreliert und organisiert werden. Die dadurch entstehende Wissensdatenbank sollte für den Agent und den Kunden frei zugänglich sein (Bob 2014,S. 7–9).
In der Abbildung werden die Stammdaten, also die Informationen, in drei Arten unter-teilt: Kundeninformationen, die alle Informationen über die Kunden beinhalten, Pro-duktinformationen mit jeglichen aktuellen Informationen über das Produkt sowie der Inhalt. Zu dem Inhalt gehören alle Informationen und Materialen in Form von Doku-menten, Bildern, Videos, Vorlagen etc., die alle Geschäftsfunktionen unterstützen. Wichtig ist bei allen Informationen, dass diese aktuell, genau, autoritativ und in Echt-zeit sein müssen. Mehrere Datenspeicher stellen sich in diesem Zusammenhang als Hindernis dar, weil sich die Informationen überlagern und widersprüchliche Informati-onen enthalten sein können (Bob 2014, S. 8).
Für die Bereitstellung der Customer-Experience-Lösung stehen vier Optionen zur Ver-fügung: die Public Cloud, die Private Cloud, Managed Services und die traditionelle IT. In der Public Cloud, also der öffentlichen Cloud, nimmt ein Unternehmen Ressourcen von Dritten in Anspruch. Die Geschäftsfunktionalitäten oder die Infrastrukturen wer-den vom Cloud-Anbieter bereitgestellt und können vom Unternehmen in Anspruch genommen werden. Die private Cloud ist ähnlich wie die öffentliche Cloud, mit dem Unterschied, dass sie dem Unternehmen gehört und kein Service von Dritten benötigt wird. Im Fall von Managed Services gehören alle Komponenten des Systems einem Unternehmen, jedoch wird der laufende Betrieb von extern gesteuert. Als letzte Möglichkeit gibt es die traditionelle IT, bei der das Unternehmen im Besitz des Systems ist und es selbst leitet (Bob 2014, S. 8–9).
Die Bereitstellungsoptionen können parallel genutzt werden, sodass die Daten auf ver-schiedenen Arten bereitgestellt werden. Jedes Unternehmen muss für sich Architek-turgrundsätze festlegen, um eine erfolgreiche Customer-Experience-Lösung zu schaf-fen (Bob 2014, S. 9).
SAP HANA
SAP HANA ist eine moderne, innovative und vielseitige Plattform, die aus einer voll-ständigen In-Memory-Lösung besteht und der Hauptbaustein für zukünftige Entwick-lungsarbeit von SAP ist. Die Plattform ist eine Bereicherung für die IT, da sie dazu bei-trägt, dass Erkenntnisse viel schneller erkannt und bereitgestellt werden. SAP HANA ist zudem ein flexibles Werkzeug, das von den Datenquellen unabhängig ist. Demnach ist es nicht relevant, woher die Daten kommen. Ohne komplizierte aggregierte physi-sche Datenmodelle zu erstellen, ermöglicht SAP HANA, große Mengen an Daten in nicht aggregierter Form in Echtzeit mit einer sehr hohen Geschwindigkeit zu analysie-ren und zu speichern. SAP HANA wird aktuell als On-Premise-Variante, bei der die Un-ternehmen ihre eigene Infrastruktur und Hardware nutzen, und als Enterprise-Cloud-Variante angeboten. Bei der cloudbasierten Alternative können Unternehmen ohne hohe Anfangsinvestitionen die Infrastruktur und die Hardware von SAP nutzen (SAP 2018).
Bei SAP HANA handelt sich jedoch um eine Datenbank, die aus der Kombination von Hardware und Software besteht, die zeilen-, spalten- und objektbasierte Datenbank-technologie ist miteinander kombiniert (Berg und Silvia 2013, S. 34). SAP HANA er-möglicht eine neue Art, mit Daten umzugehen, es werden nicht mehr nur Datenmen-gen verarbeitet, neue Prozesse und Anwendungen können aufgebaut oder bestehende optimiert werden. Unterschiedliche Geschäftsanforderungen können erfüllt werden, in der Praxis umfasst dies mehrere Branchen und Anwendungsfälle. Dazu gehören z. B. der Handel, die Kundenbindung und die Fertigung. Das Potenzial wächst immer weiter, die Anwendungsfelder sind von Daten in Echtzeit abhängig (Silvia et al. 2017, S. 45–47). Momentan wird SAP HANA beispielsweise zur Verkaufsort-, Kundenanforderungs-analyse und zur Preisoptimierung genutzt. Bei den Anwendungsfällen werden unter anderem Bondaten verwendet. Anhand von Daten in Echtzeit mit einer 360-Grad-Ansicht der Kunden kann das Kaufverhalten und die Motivation der Kunden analysiert und entsprechende Werbemaßnahmen durchgeführt werden (Silvia et al. 2017, S. 47).
In herkömmlichen SAP-Systemen war das Erstellen dieser Ansicht nicht möglich, was sich mit SAP HANA geändert hat. SAP HANA kann den Datenumfang und die Daten-menge steuern, durch das Speichern der Daten auf dem Arbeitsspeicher und auf Festplatten wird ermöglicht, riesige Datenmengen zu speichern. Dennoch ist es wichtig, die Daten zu filtern, sodass nur relevante Daten für die Anwendungen bereitgestellt werden. Theoretisch können alle Daten bereitgestellt werden, da die technische Mög-lichkeiten dafür gegeben sind. Es sollte jedoch nicht vergessen werden, dass dies mit enormen Kosten verbunden ist (Silvia et al. 2017, S. 47–49). Nichtsdestotrotz wird die Nutzung von In-Memory-Datenbanken durch die fallenden Preise für Arbeitsspeicher mit der Zeit interessanter für Unternehmen (Funk et al. 2012, S. 111–114).
Mit SAP HANA wird es für den Lebensmittelhändler möglich, seinen Lagerbestand ak-tuell zu halten und seinen Verkaufserfolg in Echtzeit zu bewerten. Dabei werden unter anderem Präsentationen im Geschäft und Werbeflyer zu verschiedenen Verkaufsaktio-nen bewertet und dementsprechend die Lager gefüllt. Um diese Analyse durchzufüh-ren, werden zum einen die Bondaten aus dem Supermarkt und zum anderen histori-sche Verkaufsinformationen genutzt, um durch den Vergleich zwischen den verschie-denen Verkaufszeiträumen festzustellen, ob der gewünschte Effekte mit den Werbe-maßnahmen erreicht wurde. Zusätzlich werden Bestell- und Lieferinformationen sowie Logistikinformationen hinzugefügt, um abzuleiten, wie schnell das Lager wieder gefüllt werden kann. Überdies können Wetterinformationen für die Analyse genutzt werden, um den Einfluss des Wetters zu beachten. Für diese Analyseanforderung werden große Mengen an Daten gebraucht. SAP HANA kann unter der Verwendung von Massive Pa-rallel Processing (MPP) und der In-Memory-Funktion Daten aus mehreren Systemen analysieren (Berg und Silvia 2013, S. 37 f.).
Vergleich der herkömmlichen und modernen IT-Architekturen bei der Bondatenanalyse anhand von Praxisbeispielen
Für den Vergleich der jeweiligen Architekturen ist an dieser Stelle zu erwähnen, dass die gewünschten Mehrwerte, wie bereits in dem Beispiel mit SAP HANA beschrieben, nicht allein durch die Bondaten erreicht wird, sondern auch Daten aus anderen Berei-chen wie Bestell- und Lieferinformationen werden benötigt, um das gewünschte Ziel zu erreichen (Berg und Silvia 2013, S. 37). Bondaten spielen eine besondere Rolle, insbe-sondere bei einer kundenorientierten Aktionssteuerung und automatischen Bestellab-wicklungen.
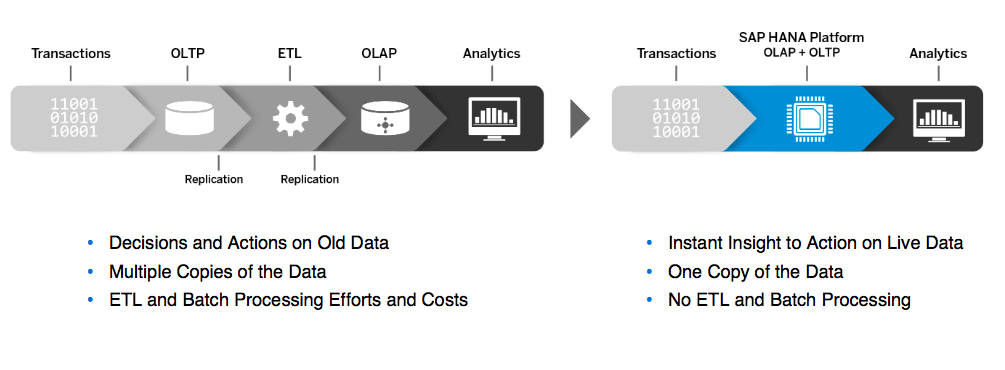
Quelle: (Arne 2015, S. 10)
In Abbildung 12 ist der Vergleich zwischen der herkömmlichen IT und der Transaktion und Analyse auf Basis der In-Memory-Plattform zu sehen. Bei der Datenverarbeitung auf Grundlage von In-Memory ist zu erkennen, dass sowohl der ETL-Prozess als auch die Batch-Verarbeitung entfällt, da die In-Memory-Technologie auf jegliche Daten zu-greifen kann, ohne diese vorher zu transformieren. Die Erkenntnisse, die durch die IN-Memory-Technologie bereitgestellt werden, entstehen auf Grundlage von Echtzeitda-ten, wohingegen bei der herkömmlichen IT die Daten zuerst durch den ETL-Prozess transformiert werden und jegliche Entscheidungen und Maßnahmen auf Grundlage von veralteten Daten geschehen. Es finden hier mehrere Datenkopien statt, was zu einer Redundanz der Daten führt; bei der In-Memory-Technologie hingegen findet nur eine Datenkopie statt, was mit einem gewissen Risiko verbunden ist (Arne 2015, S. 10). Ein weiterer Vorteil gängiger Data-Warehouse-Systeme ist der hohe Erfahrungswert aus den letzten Jahren, dem die Erfahrung mit der relativ neuen In-Memory-Datenbank entgegensteht (Funk et al. 2012, S. 111–114). Die Data-Warehouse-Systeme besitzen sehr große Datenvolumina mit der Folge, dass der Aufbau und der Betrieb hohe Anforderungen an die Datenbereitstellung hinsichtlich Performance, Da-tengranularität, -flexibilität und -aktualität hat. Um den Datenzugriff auf Data-Warehouse-Systeme zu beschleunigen, werden zudem Verdichtungsebenen verwen-det. Die daraus folgende Datenredundanz führt zu einem hohen Aufwand an Zeit und Ressourcen, um die gewünschte Datenpflege und Datenverfügbarkeit zu schaffen (Winsemann und Köppen 2011, S. 97). Das Grundziel ist bei Data-Warehouse-Systemen die Datenintegration, die durch die vertikale und horizontale Integration und mit ETL-Prozessen geschieht (Gubler 2014). Bei In-Memory-Datenbanken fallen die Verdichtungsebene und die damit verbundene Datenredundanz weg und stellt sich in der Theorie in Hinblick auf die Datenredundanz als die bessere Technologie dar (Winsemann und Köppen 2011, S. 97).
Für die Lebensmittelhändler ergibt sich durch die Bondatenanalyse eine Möglichkeit, Umsätze zu maximieren. Die Einzelhandelsunternehmen sind das Bindeglied zwischen den Produzenten und Verbrauchern. Deshalb ist wichtig, durch interne Analysen von Einzelhandelsdaten, insbesondere der Bondaten, die Kundenwünsche festzustellen, um dementsprechend das Sortiment zu gestalten und das Kaufverhalten der Kunden zu erkennen. Die Sortimentspolitik und die Produktpolitik sind, wie bereits in Kapitel 2 beschrieben, ein entscheidender Faktor für den Umsatz und die Rentabilität eines Un-ternehmens. Die dänische Supermarktkette Dansk Supermarked, die über 1.300 Filia-len in Dänemark, Schweden, Deutschland und Polen betreibt, hat festgestellt, dass das Kaufverhalten der Kunden stark variiert (HPE 2017). Die Kunden lassen sich von Fak-toren wie Nachhaltigkeit, Bio-Siegel, Herkunftsland, Rechte von Tieren und Menschen und gesellschaftliches Engagement von Unternehmen beeinflussen. Deshalb ist wich-tig, für jedes Segment ein zielgruppenorientiertes Nutzenpotenzial zu haben. Das hat zur Folge, dass der Lagerbestand immer größer und die Verwaltung immer komplizier-ter wird. Mithilfe von Analysen mittels In-Memory-Datenbanken kann das Unterneh-men ihre Preis- und Produktpolitik unterstützen. Bei der richtigen Durchführung kann sich der Gewinn maximieren und die Verschwendung von Lebensmitteln reduzieren. Ziel der IT-Abteilung ist, an dieser Stelle die IT-Systeme so zu optimieren, dass an-hand aus der Verkaufspunkte kommende Datenmengen erfasst und Vorhersageanaly-sen durchgeführt werden können. Wichtig dabei ist die zeitgerechte Berichterstellung, um rechtzeitig auf Kundenanforderungen reagieren zu können. Wenn beispielsweise die Berichte erst am nächsten Morgen zur Verfügung stehen, wie es bei Analysen mit-tels Data-Warehouse-Architekturen der Fall ist, können manche Ziele nicht mehr er-füllt werden (HPE 2017).
Das entsprechende Geschäftsmodell und die entsprechenden Geschäftskanäle, sprich der Aufbau von Werbung und Aktionen, sowie die richtige Warenplatzierung können mit der Nutzung von aktuellen Daten verbessert werden. Dazu gehören auch die ex-ternen und Organisationsprozesse wie das Verknüpfen der Daten zwischen den einzel-nen Großhändlern und den einzelnen Filialen (Städler und Fischer 2001, S. 208–211). Laut Dansk Supermarked Group ist es aufgrund von niedrigen Margen, sich verän-dernden Kundenwünschen und neuen Verkaufskanälen zwingend erforderlich, Daten effektiver zu nutzen und zu analysieren. Die Supermarktkette bedient täglich 1,4 Milli-onen Kunden. Ziel ist dabei, jeden einzelnen Kunden zufriedenzustellen, indem jeder Artikel, den der Kunde erwerben möchte, frisch auf Lager zur Verfügung steht. Da im Lebensmittelhandel viele Produkte schnell verderben, ist es wichtig, Überbestände zu vermeiden. Dazu müssen die Analysen beispielsweise Auskunft darüber geben, welche Sorten an Milch und welche Anzahl in einem Markt zur Verfügung stehen müssen. Durch den Wegfall des ETL-Prozesses und der damit verbundenen Übertragungsfehler steigt zudem die Datenqualität bei den In-Memory-Architekturen, was sehr wichtig für die Nutzbarkeit der Analysen ist (HPE 2017).
Die Dansk Supermarked Group hat die IBM Power und DB2-Plattformen mit dem vor-handenen SAP-Business-Warehouse genutzt, mit der Problematik, dass die Daten nicht schnell genug zur Verfügung standen, sodass Berichte erst am nächsten Morgen genutzt werden konnten. Dementsprechend transformierte die Firma seine IT-Umgebung durch die Migration in die In-Memory-Computing-Plattform SAP HANA, so-dass eine Echtzeitanalyse möglich ist. Bei der Implementierung der neuen Technologie wurde die Firma von HPE unterstützt (HPE 2017). Wichtig für die Dansk Supermarked Group war, dass der SAP-Partner die Kosten nutzungsabhängig gestaltet, da im Le-bensmittelhandel eine saisonbedingte Dynamik herrscht und generell die Kosten für die IT-Abteilung gesenkt werden. In Zusammenarbeit mit HPE wurde eine End-to-End Transformationslösung geschaffen, sodass schlussendlich eine Analyse von großen Mengen an Daten möglich ist. Heutzutage ist es für die Dansk Supermarked Group erreichbar, Daten aus den europaweit verteilten Kassensystemen aufzunehmen, sie zu analysieren und den Entscheidungsträgern in Echtzeit Berichte bereitzustellen (HPE 2017).
Jeden Morgen stehen den Marktleitern detaillierte Informationen über das Käuferver-halten zur Verfügung, ohne dazu mehrere Stunden auf die Auswertung von Berichten zu warten. Anhand dieser personalisierten Daten können die Lagerbestände entspre-chend verwaltet werden. Dies sind die besten Voraussetzungen, um die Kunden zu-friedenzustellen, den Umsatz zu maximieren und Abfälle durch verdorbene Lebensmit-tel zu vermeiden. Laut HPE hat die Dansk Supermarked Group in Dänemark die besten Ergebnisse im Bereich Kundenzufriedenheit, finanzieller Performance und Mitarbeiter-zufriedenheit (HPE 2017).
Mit In-Memory-Datenbanken wird die Kommunikationspolitik und damit der Bekannt-heitsgrad und die Imageleistungen der einzelnen Produkte verbessert. Die Zielgruppen können mittels besserer Kommunikationsinstrumente und -maßnahmen erreicht wer-den. Die Supermarktkette ALDI Nord ist ebenfalls auf den SAP-Betrieb in der HANA Cloud umgestiegen. ALDI Nord teilte mit: „Die neue Software ermöglicht es, die Transparenz im Warenfluss vom Lieferanten bis zum Kunden zu verbessern. Größt-mögliche Flexibilität hinsichtlich der Auswertbarkeit von Daten ermöglicht die so ge-nannte (sic!) HANA-Datenbank, die für SAP Retail genutzt wird“ (ALDI Nord 2015).
Lidl hat ebenfalls auf SAP HANA gewechselt, das Projekt Elektronische Lidl-Warenwirtschaft (Elwis) wurde jedoch nach sieben Jahren Entwicklung im Juli 2018 abgebrochen. In Zeitungsberichten wird angegeben, dass Lidl weltweit mehr als 10.000 Filialen und 140 Logistikzentren hat und einige von ihnen mit einer Memory-residenten Datenhaltung steuerte und aufgrund von Problemen, die nicht von Lidl ge-nauer erläutert werden, das Projekt nun beendet ist (Schüler 2018). Dies geschah trotz der laut Lidl entstandenen Mehrwerte wie 20 % weniger Prozessschritte in der Bestellabwicklung und Echtzeit-Bestandsabfragen in Umsatzzahlen in jeder Filiale (Lidl 2016). Für Lidl war die Umstellung auf SAP HANA einer der größten Transformations-prozesse in ihrer Unternehmensgeschichte, da SAP HANA ein selbst entwickeltes Wa-renwirtschaftssystem von Lidl mit 90 Modulen für Einkauf, Filialsteuerung, Logistik und Angebotsabwicklung und 150 spezialisierten Schnittstellen mit anderen Anwendungen des Discounters umgestellt hat (Schüler 2018).
In den Jahren der Umstellung und Entwicklung wurden mehr als 500 Millionen Euro in das Projekt investiert. Mit als Grund für das Abbrechen wird genannt, dass die Soft-ware in umsatzstarken Filialen, die im Ausland sind, nicht leistungsfähig genug sei. Die Vorstände schreiben, dass der Abbruch „keine Entscheidung gegen SAP, sondern für ein eigenes System“ gewesen sei (Schüler 2018). Zudem wurde geschrieben, dass mit Elwis „die ursprünglich definierten strategischen Ziele nicht mit vertretbaren Aufwand“ zu erreichen seien (Schüler 2018). Es lässt sich interpretieren, dass der Discounter grundsätzlich zufrieden war mit der verwendeten SAP-Software und es auch nicht an den Lizenzkosten gescheitert ist. Dennoch ist Elwis ein Beispiel für einen Misserfolg eines großen Projektes (Schüler 2018). Dies lässt vermuten, dass die Umstellung aus Projektmanagementgründen gescheitert ist und ein direkter Wechsel der eigenen Software im Unternehmen auf SAP HANA problematisch wurde. Das bedeutet, dass im Hintergrund festgehalten werden muss, dass ein Wechsel der Datenbanken von Data Warehouse auf In-Memory-Technologie mit Problemen und Herausforderungen ver-bunden ist. Eine Möglichkeit In-Memory-Datenbanken aufgrund der hohen Kosten und der geringeren Backup-Möglichkeiten zu umgehen, wäre der Einsatz von Solid State Drive. Dies sind Festplatten, die eine persistente Speicherung mit einer verbesserten Performance herkömmlichen Festplatten gegenüber kombiniert, da sie keine mechani-schen Bauteile besitzen. Der Nachteil ist jedoch die endliche Anzahl an Schreibvorgän-gen pro Block, die bei Solid State Drives möglich sind. Deswegen wären sie nur für Datensätze geeignet mit einer geringen Anzahl an Datenänderungen (Funk et al. 2012, S. 113).
Recent Comments