Chatbots wie ELIZA, PARRY oder Alice sind zwar teilweise in der Lage einen Menschen zu simulieren und so den Nutzer zu täuschen, basieren jedoch auf handkodierten Regelwerken und können nicht auf vorher undefinierte Situationen richtig reagieren (Shawar und Atwell 2005, S. 491). Um auch auf neue Situationen reagieren zu können, muss der Software-Agent nicht nur ein gewisses Expertenwissen besitzen, sondern auch in der Lage sein, die Anfrage des Nutzers richtig zu interpretieren und in einer realistischen Art und Weise zu beantworten. Diese Eigenschaft impliziert eine gewisse Intelligenz des Software-Agenten, die auch als KI bezeichnet wird (Brenner et al. 1998, S. 36-37). Künstliche Intelligenz beschäftigt sich vor allem mit dem Verständnis von Wissen, Problemlösungsparadigmen, Beweisen, Sprach- und Bildanalysen oder der Entwicklung von Lernalgorithmen (Maes 1993, S. 136-137). Die klassische KI befasst sich dabei in der Regel mit geschlossenen Systemen, die nur bedingt mit der Umwelt agieren. Sie besitzen zwar Wissen über ihre Umgebung, sind aber nicht darauf ausgelegt, mit dieser zu kommunizieren. Sie simulieren beispielsweise bestimmte Situationen in einer vorgegebenen Umgebung, um so ein Verhalten zu prognostizieren. Die Ergebnisse können in der Regel nicht von Laien interpretiert werden und müssen von Experten aufgearbeitet werden. Software-Agenten hingegen müssen in der Lage sein, direkt mit Ihrer Umge bung zu kommunizieren und zu interagieren. Um dabei vom Nutzer akzeptiert zu werden, müssen sie versuchen, ihr Wissen wie ein menschlicher Nutzer zu vermitteln und im Idealfall die Kommunikation so natürlich zu gestalten, dass der Nutzer denkt mit einer realen Person zu schreiben. Ein weiterer Unterschied zu der klassischen KI stellt der Aufbau dar. Eine klassische KI verfügt in der Regel über ein hochkomplexes und umfangreiches Wissen in einem sehr begrenzten Bereich. Der Software-Agent hingegen besitzt eher eine Gesamtintelligenz, die sich aus einfachem Wissen vieler verschiedener Bereiche zusammensetzt. Die klassische KI setzt außerdem meist voraus, dass das Problem bekannt ist und arbeitet größtenteils mit statischen Komponenten, während ein Software-Agent dynamisch ausgelegt sein müsste, um neue Probleme zu erkennen und Ziele zu formulieren. Diese müssen dabei nicht vom Nutzer vorgegeben sein, sondern können auch vom Software-Agenten proaktiv erkannt und gesetzt werden. Um nun solche Defizite zu kompensieren, bietet sich laut Brenner, neben der Nutzung von beispielsweise Neuronalen Netzen für Software-Agenten auch die Nutzung Verteilter Künstlicher Intelligenz (VKI) an. Dabei liegt der Fokus nicht darauf, ein einziges rechenstarkes System zu entwickeln, sondern vielmehr mehrere Systeme zu entwickeln, die parallel arbeiten und miteinander kommunizieren, um eine höhere Leistung zu gewährleisten. Ermöglicht wird diese Leistung vor allem durch die Nutzung von Organisationsstrukturen, Problemlösungsstrategien sowie Kooperations- und Koordinationsmechanismen (1998, S. 36-37). Es ist jedoch zu beachten, dass nicht alle Algorithmen parallelisierbar sind und dadurch die Anwendungsmöglichkeiten auf große Datenmengen und auf verteilten Geräten stark eingeschränkt werden können (Döbel et al. 2018, S. 59). Aus diesem Grund wird der Fokus dieser Arbeit nicht auf der Nutzung der VKI liegen.
Machine Learning
Die KI hat in den letzten Jahren durch die Entwicklung des ML eine Art Renaissance durchlebt. ML beschreibt die Generierung von Wissen aus Erfahrungswerten mittels verschiedener Lernalgorithmen. Mit diesem Wissen wird ein komplexes Modell entwickelt, welches auf potenziell unbekannte Daten derselben Art angewendet werden kann. Diese Vorgehensmethode des ML wird genutzt, wenn ein Prozess zu kompliziert ist um analytisch beschrieben zu werden, jedoch genügend Beispieldaten verfügbar sind. Dadurch sind Prognosen zu komplizierten Problematiken möglich, ohne dabei die Regeln oder den logischen Grund für dieses Endresultat wissen zu müssen (Döbel et al. 2018, S. 9). Aus diesem Grund ist es sinnvoll, ML bei Chatbots anzuwenden, um beispielsweise durch die Antworten und Reaktionen des Kunden Wissen über das Kundenverhalten zu sammeln, dieses zu verarbeiten und somit Verhaltensprognosen zu verbessern, ohne dabei die genauen Gründe für dieses Verhalten zu erfahren. ML wird im Kontext des Chatbots oft genutzt, um verschiedene Sprech- und Antwortweisen von Nutzern zu erlernen. Die ser Prozess wird auch Natural Language Processing genannt. Ein Beispiel für einen Chatbot, der mittels ML dazulernt ist der von Microsoft entwickelte Chatbot Xiaoice. Xiaoice entwickelt eine spezielle Persönlichkeit und einen Sinn für Humor, indem er das Internet systematisch nach realen Konversationen durchsucht und diese auswertet. Außerdem werden die Reaktionen der Nutzer aus den geführten Konversationen ebenfalls ausgewertet. Dies geschieht mittels ML ohne menschliche Anleitung (Darcy et al. 2016, S. 551). Xiaoice benutzt dabei ein spezielles Teilgebiet des ML, und zwar das Deep Learning, was soviel wie „Tiefes Lernen“ bedeutet (Singh 2018).
Quelle: Döbel et al. (2018, S. 26)
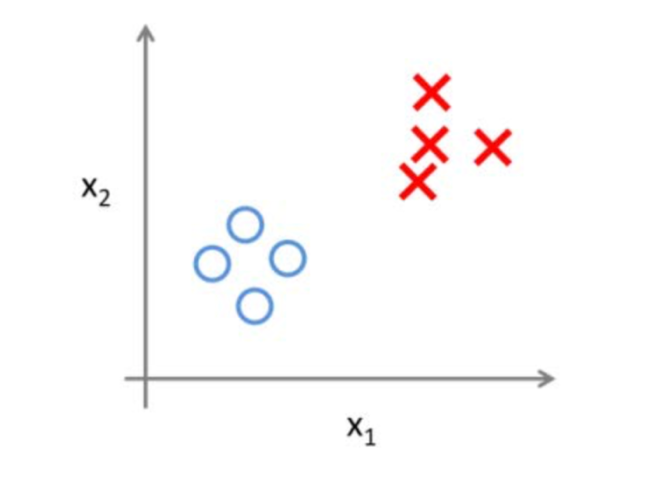
Im Nachfolgenden werden wichtige Lernverfahren des ML erläutert, um ein generelles Verständnis für ML und Deep Learning zu entwickeln. Man unterscheidet beim maschinellen Lernverfahren zwischen vielen verschiedenen Lernstilen, die für jeweils verschiedene Zwecke geeignet sind. Eine Form des ML ist das überwachte Lernen, bei dem die richtigen Antworten zu den Beispielen mitgeliefert werden. Dies impliziert eine intensivere Datenvorverarbeitung, um bestimmte Objekte zu klassifizieren und Werte vorherzusagen (siehe Abb. 4). Wenn beispielsweise der Nutzer Ziffern handschriftlich aufschreibt und diese erkannt werden sollen, benötigt der Lernalgorithmus eine Zuweisung zu den richtigen Ziffern, um diese in Zukunft automatisch zu erkennen. Ähnlich funktioniert es beim Markieren von Spam-Mails, die im weiteren Verlaufe automatisch als Spam erkannt werden. Wichtig ist es, die Qualität der Beispielsdaten hoch zu halten, da der Algorithmus ansonsten etwas Falsches lernt (Döbel et al. 2018, S. 26).
Quelle: Döbel et al. (2018, S. 27)
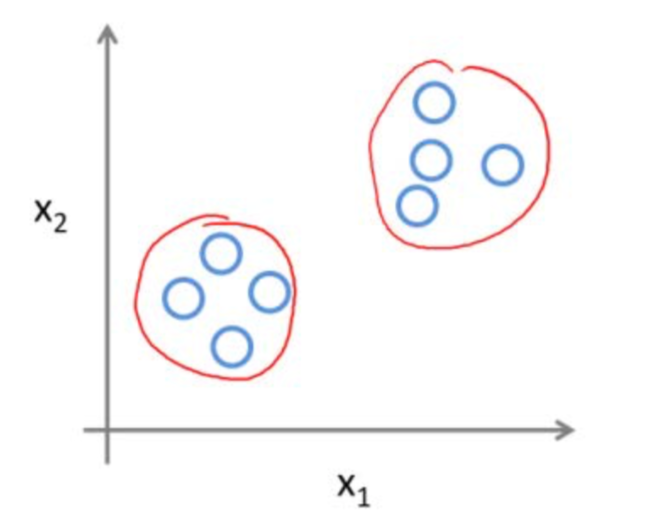
Beim unüberwachten Lernen wird meist mit sehr großen, unstrukturierten Datenmengen gearbeitet, deren Qualität oftmals nicht genau bekannt ist. Es werden deswegen meistens Cluster bzw. Gruppen gebildet und beispielsweise Kundendaten segmentiert, um Zielgruppen zu identifizieren, die man ansprechen möchte (siehe Abb. 5). Beim Clustering werden Cluster durch Ähnlichkeiten und Unterschiede gebildet, jedoch ohne zu wissen, was für konkrete Ähnlichkeiten diese Cluster ausmachen. Diese Cluster werden erst anschließend von Experten beispielsweise als „Spam“ identifiziert und gekennzeichnet. Nachdem man die wichtigsten Cluster identifiziert hat, kann man andere Daten diesen Clustern zuordnen (Döbel et al. 2018, S. 26-27).
Das semiüberwachte Lernen ist eine Mischung aus überwachtem und unüberwachtem Lernen. Dabei werden nur einige der Beispiele mit den richtigen Antworten geliefert um den Aufwand zu verringern. Es werden Lernalgorithmen benutzt, die Clustering und Klassifikationen miteinander kombinieren. Dazu werden zunächst Cluster erstellt und im weiteren Verlauf anhand wenigen Beispielantworten Cluster Klassen zugeordnet (Döbel et al. 2018, S. 28).
Quelle in Anlehnung an: Das (2017)
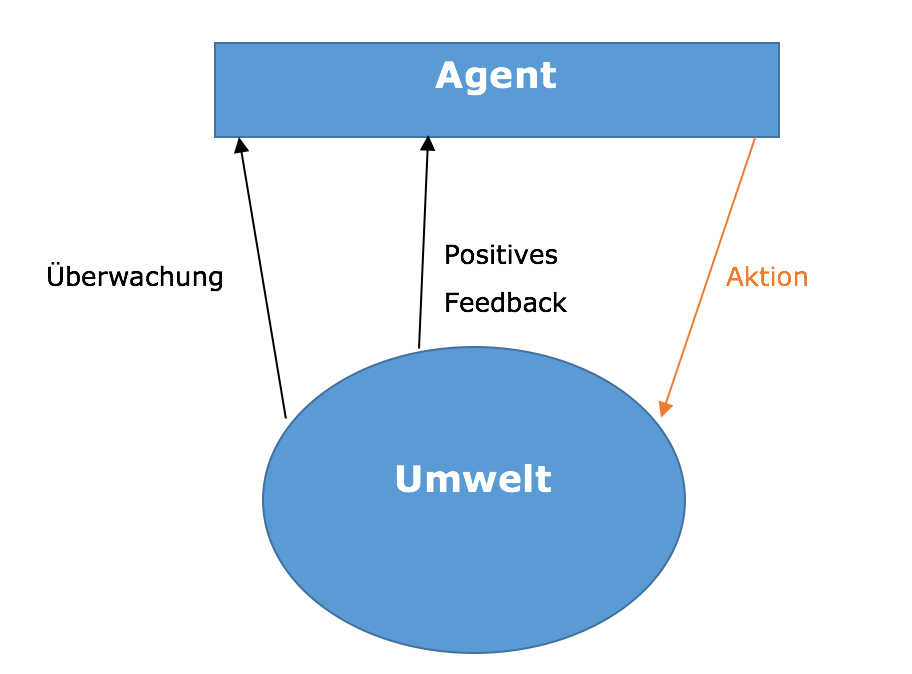
Eine weitere Methode stellt das bestärkende Lernen und sequentielle Entscheiden dar, bei der das System Feedbacks zu ihren Aktionen erhält, um die Erfolgsaussichten einzelner Situationen besser einschätzen zu können. Das Ziel ist es mittels dieser Vorgehensweise das positive Feedback und die Nutzenfunktion zu maximieren. Dies geschieht schrittweise und sequentiell (Döbel et al. 2018, S. 28).
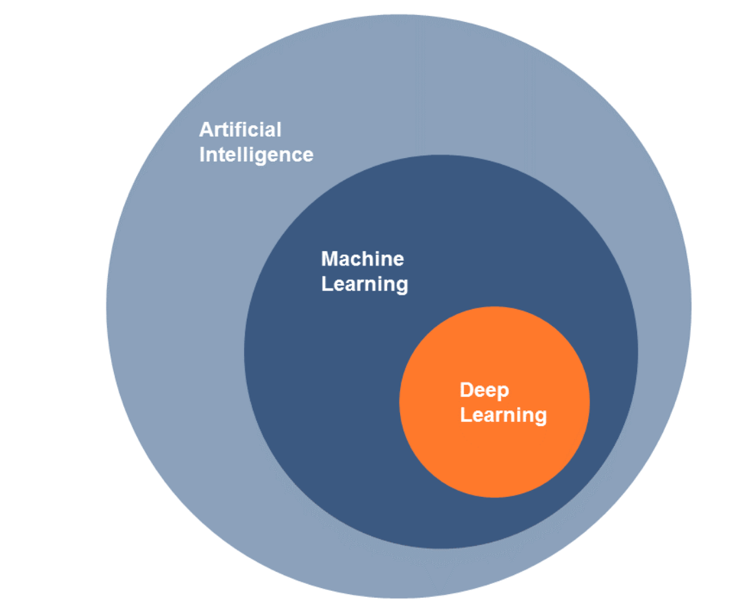
In Bezug auf Chatbots spielen Künstlichen Neuronale Netze sowie das sog. Deep Learning eine große Rolle. 1948 beschäftigten sich Warren McCulloch und Walter Pitts erstmals mit neuronalen Netzen (Rey und Beck 2005, S. 4). Abbildung 7 zeigt den Zusammenhang zwischen den Begriffen Künstliche Intelligenz (Artificial Intelligence), Machine Learning und Deep Learning, da diese fälschlicherweise in einigen Literaturen oder Beiträgen als Synonyme verwendet und nicht ordnungsgemäß voneinander unterschieden definiert werden. Deep Learning, das überwachte und auch das unüberwachte Lernen sind Methoden des Machine Learnings, welche wiederum ein Teilgebiet der Künstlichen Intelligenz darstellt. Der Begriff Deep Learning bezeichnet dabei eine spezielle unüberwachte Anwendungsform von Künstlich Neuronalen Netzen, deren Hidden-Ebenen vielschichtig und komplex sind (Tiedemann 2018).
Deep Learning
Quelle: Tiedemann (2018)
Als neuronale Netze werden Systeme bezeichnet, die die Organisationsprinzipien des Gehirns für sich nutzen. Sie bestehen aus einer Vielzahl unabhängiger, einfacher Prozessoren, die auch Neuronen genannt werden und mittels gewichteten Verbindungen Informationen miteinander austauschen. Diese Verbindungen bezeichnet man als synaptische Gewichte (Nauck et al. 2013, S. 1).
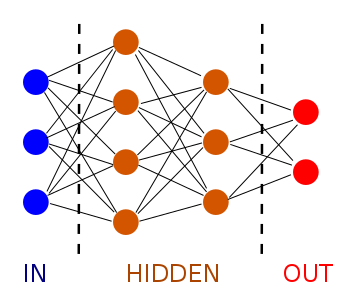
Abbildung 8: Darstellung eines neuronalen Netzes
Quelle: spiele-programmierer (2017)
Neuronale Netze bestehen aus mehreren Neuronen, die auch als Units, Einheiten oder Knoten bezeichnet werden. Sie nehmen Informationen aus der Umwelt oder von anderen Neuronen auf und senden diese in modifizierter Form weiter. Man unterscheidet dabei zwischen den in der Abbildung 8 dargestellten, blauen Input-Units, orangenen Hidden-Units und roten Output-Units. Die Input-Units beinhalten Signale oder Informationen, die von der Außenwelt empfangen wurden. Die Hidden-Units wiederum befinden sich zwischen Input- und Output-Units und beinhalten eine interne Repräsentation der Außenwelt. Output-Units geben Signale oder Informationen wieder an die Außenwelt weiter. Diese Units sind miteinander durch Kanten verbunden. Die Stärke dieser Verbindung wird durch ein Gewicht ausgedrückt. Ein positives Gewicht bringt beispielsweise zum Ausdruck, dass ein Neuron auf ein anderes Neuron einen erregenden Einfluss hat, während ein negatives Gewicht einen hemmenden Einfluss beschreibt. Ein Gewicht von Null bedeutet, dass kein Einfluss ausgeübt wird (Rey und Beck 2005, S. 5-6). Außerdem bestimmt eine Aktivierungsfunktion, wie stark das Signal von einem Unit zum nächsten weitergegeben werden soll (Döbel et al. 2018, S. 19). Das besondere an neuronalen Netzen ist, dass die interne Funktionsweise, also die Hidden-Inputs ignoriert werden. Aus diesem Grund werden diese Modelle auch Black-Box-Modelle genannt und eignen sich sehr gut, um aus Beobachtungen zu lernen, deren Prozesse zu komplex sind, um sie physikalisch zu beschreiben. Es handelt sich somit auch um eine Art des unüberwachten Lernens (Döbel et al. 2018, S. 72). Mithilfe von Deep Learning sind Chatbots beispielsweise in der Lage, mit jeder gestellten Frage dazuzulernen und so beispielsweise auch Dialekte zu erkennen (Tiedemann 2018). In diesem Zusammenhang werden auch weitere Arten von Neuronalen Netzwerken genutzt. Eine Form ist das Convolutional neural network, welches durch den Einsatz einer mathematischen Faltungsoperation wichtige lokale Merkmale erkennen kann. Beispielsweise können somit Augen erkannt werden, egal wo sich der Kopf innerhalb des Bildes befindet (LeCun et al. 1998, S. 2284). Rekurrente Neuronale Netze verarbeiten Eingaben weder parallel noch unabhängig voneinander, sondern berücksichtigen die jeweils vorherige Eingabe und arbeiten nacheinander. Dadurch entsteht eine Art Gedächtnis (Elman 1990, S. 184-185). Eine weitere Form ist das generativ gegnerische Netz, bei dem zwei neuronale Netze parallel trainiert werden. Das erste Netz ist der Generator, der stets neue Beispiele erzeugt, während das zweite Netz, der Diskriminator, versucht, die generierten Beispiele von realen Beispielen zu unterscheiden. Der Generator wird während des Prozesses über die Entscheidungsfindung des Diskriminators in Kenntnis gesetzt und erzeugt dadurch immer realitätsnähere Beispiele (Goodfellow et al. 2016, S. 94-96).
Machine Learning bei Chatbots
Das Natural Language Understanding und Natural Language Processing sind der Grund, warum ML vor allem bei Chatbots wichtig ist. Natural Language Understanding ist ein Teilgebiet des Natural Language Processing und beschreibt die Techniken zur Erkennung und Zuordnung der natürlichen Spracheingabe des Nutzers. Natural Language Processing umfasst generell die Fähigkeit von Computern, mit gesprochenem oder geschrieben Text arbeiten zu können. Dazu wird die Bedeutung aus einem Text extrahiert oder sogar ein neuer Text erzeugt, der lesbar, stilistisch natürlich und grammatikalisch korrekt ist. Ohne Natural Language Processing wären Computersysteme nicht in der Lage, natürliche Sprachen zu erkennen. Durch die unüberwachten Methoden des ML werden viele Möglichkeiten im Bereich des Natural Language Processing geschaffen (Gentsch 2017, S. 31).
Die Firma Dialogflow beschreibt dies mit folgendem Beispiel. Wetteranfragen könnten zum Beispiel wie folgt lauten:
„Was ist die Wettervorhersage für heute?“
„Wie ist das Wetter im Moment?“
„Was für eine Temperatur haben wir morgen in San Francisco?“
„Wie wird das Wetter am 21. sein?
Obwohl es sich hierbei lediglich um eine Wetteranfrage handelt, die in der Beantwortung wenig Recherche benötigt, kann die Formulierung dieser Frage sehr variieren. Das Dolmetschen und Verarbeiten dieser Frage erfordert sehr robuste Sprachparser. Sprachparser sind Programme, welche die Semantik des Satzes analysieren und die Nuancen der Sprache verstehen. Während ein Mensch jede dieser Fragen versteht, würde ein regelbasiertes Spracherkennungsprogramm ohne ML auf seine Grenzen stoßen, sobald man nicht jede einzelne Satz- und Wörterkombination vordefiniert hat. Da dies in der Praxis so gut wie kaum möglich ist, wird der Nutzer gezwungen, eine bekannte, standardisierte Anfrage in einer vorgegebenen Form zu stellen, damit sie vom System erkannt wird. Das wiederum hätte zur Folge, dass ein wichtiger Baustein der Benutzerfreundlichkeit verloren geht (Dialogflow 2018b).
Eine weitere Problematik zeigt der englische Satz „Time flies like an arrow“. Der Satz ist eindeutig und bedeutet sinngemäß, dass die Zeit wie im Fluge vergeht. Doch sobald die Wörter „Time“ mit „Fruit“ und das „arrow“ mit „banana“ ersetzt werden, lautet der Satz „Fruit flies like a banana“. Im ersten Satz bedeutete „flies“ noch soviel wie „vergehen“, wohingegen es im zweiten Satz zum Nomen „Fruit flies“, also „Fruchtfliegen“ wird. Außerdem verändert sich die Bedeutung der Präposition „like“ – „wie“ im zweiten Satz zu „mögen“. Ein Mensch wäre in der Lage, die Wortbedeutungen intuitiv zu erkennen, wohingegen ein Computersystem Natural Language Processing und Machine Learning-Algorithmen nutzen muss (Gentsch 2017, S. 32). Mithilfe von ML und vor allem unüberwachten Lernmethoden können jedoch mit der Zeit verschiedene Sprachstile, sobald sie öfter vorkommen automatisch erkannt und geclustert werden, ohne dass vorher Klassen definiert werden. Außerdem wird durch jede einzelne Anfrage das Sprachmodell weitertrainiert. Die Praxis zeigt, dass eine Kombination aus überwachten und unüberwachten Lernalgorithmen die besten Ergebnisse erzielt. Beispielsweise wäre ein Training mittels neuronaler Netze und Deep Learning möglich. Anschließend werden überwachte Modifizierungen vorgenommen, um die Spracherkennung zu optimieren (Radford et al. 2018, S. 8).
Recent Comments