In diesem Kapitel wird die Selektion einer Datenbank und Plattform für den Prototypen diskutiert. Im ersten Unterkapitel wird erläutert, warum sich die SAP HANA-Datenbank für die Implementierung des Prototyps eignet. Im zweiten Kapitel wird erläutert, warum sich Node.js für die Implementierung des Prototyps eignet.
SAP HANA
Im Rahmen der technischen Implementierung des Prototyps musste zunächst entschie-den werden, welche Datenbank und welche Anwendungsplattform genutzt werden sol-len. Im ersten Unterkapitel wird die SAP HANA-Datenbank vorgestellt und erläutert, warum sie sich für die Implementierung eignet. Im zweiten Unterkapitel wird diskutiert, welches Programmiermodell für den Prototyp genutzt werden soll.
SAP HANA-Datenbank
Bei der HANA-Datenbank handelt es sich um eine sogenannte In-Memory-Datenbank (Silvia et al. 2017, S. 19). Der Begriff In-Memory-Datenbank bedeutet, dass eine große Menge von Daten im Random-Access Memory (kurz: RAM) eines Computer gehalten werden können, womit eine hohe Performanz erreicht wird (Silvia et al. 2017, S. 20). Auf die Daten im Hauptspeicher (RAM) kann ca. 100.000-mal schneller zugegeriffen werden als auf die Daten einer Festplatte (Silvia et al. 2017, S. 23). Für die Haltung der Daten im Hauptspeicher gelten, wie bei herkömmlichen Datenbanken, die ACID-Regeln (Silvia et al. 2017, S. 24f). Um dem Aspekt der Dauerhaftigkeit (engl.: persistency) der ACID-Regeln Rechnung zu tragen, werden die auf der In-Memory-Datenbank ausgeführten Transaktionen auf einer Festplatte vermerkt (Silvia et al. 2017, S. 25). Diese Sicherung ist nötig, da es sich bei RAM um einen flüchtigen Speicher handelt, der verloren ginge, wenn beispielsweise ein Stromausfall stattfindet (Silvia et al. 2017, S. 25). Durch die Protokollierung der Transaktionen kann die In-Memory-Datenbank wiederhergestellt werden (Silvia et al. 2017, S. 25).
Das zweite zentrale Feature der HANA-Datenbank ist die Fähigkeit, die Datensätze in der Datenbank in Spalten statt in Zeilen zu organisieren (Silvia et al. 2017, S. 32). Im Folgenden wird erläutert, warum die Organisation in Spalten für Analysen besser geeignet ist. Die spaltenbasierte Speicherung unterscheidet sich von der zeilenbasierten Speicherung in der Art, wie die Datenbanktabellen gespeichert und gelesen werden (Silvia et al. 2017, S. 34)
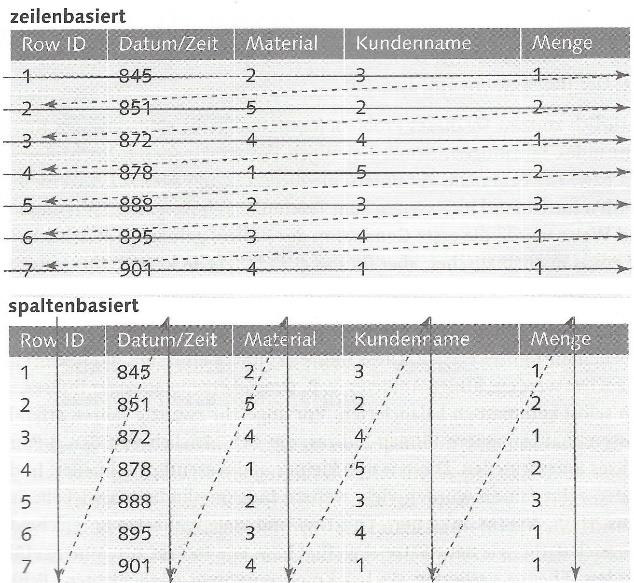
(Silvia et al. 2017, S. 34).
Während bei der zeilenbasierten Speicherung bei Tabellenzugriff alle Daten gelesen werden müssen, ist es bei der spaltenbasierten Speicherung möglich, nur die für eine Abfrage relevanten Spalten zu lesen, wobei jede Spalte zudem als Schlüssel oder Index der Abfrage genutzt werden kann (Silvia et al. 2017, S. 35). Ist die Spalte des Kundennamens beispielsweise nicht Teil einer Abfrage, wird diese Spalte nicht gelesen, womit die Abfrage schneller wird (Silvia et al. 2017, S. 34f). Beim zeilenbasierten Zugriff müssen hingegen alle Daten gelesen werden (Silvia et al. 2017, S. 35). Allerdings ist die spaltenbasierte Speicherung bezüglich der Aktualisierung und dem Einfügen von Daten weniger effizient als die zeilenbasierte Methode (Silvia et al. 2017, S. 35). Dieser Nachteil kann allerdings dadurch umgangen werden, dass die Aktualisierung der Datenbank außerhalb der Geschäftszeiten abgewickelt wird, sodass innerhab der Geschäftszeiten nur die performanten Lesezugriffe genutzt werden, was in Kapitel 4.5.1 näher erläutert wird. Die Entwickler können sich im Rahmen von SAP HANA zwischen dem zeilenbasierten und spaltenbasierten Ansatz bei der Erstellung einer Datenbanktabelle entscheiden, wobei SAP HANA allerdings insbesondere für den spaltenbasierten Ansatz optimiert ist (Kühnlein und Seubert 2016, S. 28 bis 30).
Durch die hohe Performanz der HANA-Datenbank und die damit verbundene Möglichkeit von Echtzeitanalysen, bietet sie sich für das Ziel eines automatisierten Preismanagements im Lebensmitteleinzelhandel an. Ein weiteres Argument für Nutzung der HANA-Datenbank ist, dass die SAP-Einzelhandelslösung SAP Retail, die u. a. von EDEKA, REWE, Aldi-Nord und Aldi-Süd genutzt wird (SAP SE 2007; REWE Systems o. J.; ALDI-Nord 2015; ALDI-Süd 2019), auf der HANA-Datenbank läuft (Anderer 2016, S. 21). Die HANA-Datenbank hat folglich im Rahmen der IT-Lösungen des Lebensmitteleinzelhandels bereits eine zentrale Bedeutung und es kann davon ausgegangen werden, dass bei den Einzelhändlern bereits Experise in diesem Breich vorhanden ist. Aus den genannten Gründen wurde sich für die Nutzung von SAP HANA entschieden.
Anwendungsplattformen und Programmiermodelle der HANA
Im Folgenden wird diskutiert, welche Plattform und welches Programmiermodell im Kontext der HANA-Datenbank gewählt werden soll. SAP HANA ist nicht nur eine Datenbank, sondern bietet auch eine Anwendungsplattform an (Silvia et al. 2017, S. 107). Diese Anwendungsplattform, die als XS Engine oder SAP HANA XS Classic bezeichnet wird, umfasst einen Web-Server und einen leichtgewichtigen Anwendungs-server, mit denen leichtgewichtige Web-Anwendungen entwickelt werden können (Silvia et al. 2017, S. 107 und S. 172). Als Programmiersprachen werden HTML5 und das sogenannte XS JavaScript genutzt, das einige auf die XS Engine zugeschnittene Sprachelemente von serverseitigem JavaScript umfasst (Kühnlein und Seubert 2016, S. 37).
Entwickler können sich entscheiden, ob sie dieses Programmiermodell des integrierten Anwendungsservers der HANA nutzen, was auch als native Entwicklung bezeichnet wird, oder ob sie die HANA lediglich als Datenbank nutzen, auf die mit einem externen An-wendungsserver zugegriffen wird (Kühnlein und Seubert 2016, S. 40). Im letzteren Fall wird der größte Teil der Anwendungslogik auf dem externen Anwendungsserver abgewickelt und nur datenintensive Operationen an die HANA-Datenbank delegiert (Kühnlein und Seubert 2016, S. 41). Die beiden Programmiermodelle werden in der folgenden Abbildung dargestellt.
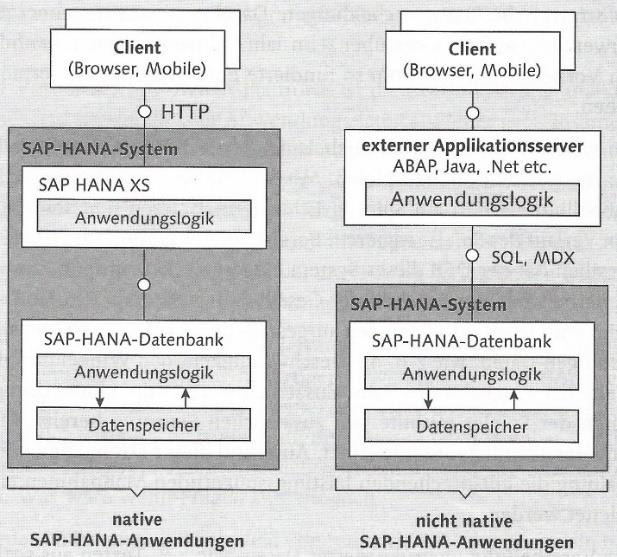
(Kühnlein und Seubert 2016, S. 40)
Die verschiedenen Arten von externen Anwendungsservern können mit bestimmten Protokollen bzw. Treibern auf die SQL-Funktionen der HANA zugreifen (Kühnlein und Seubert 2016, S. 41). Da im Rahmen der nativen Entwicklung für den Zugriff kein zusätzliches Protokoll benötigt wird, und somit die Anzahl von Architekturschichten
minimiert wird, ist der Performanz des nativen Programmiermodells höher, was von hoher Relevanz für Echtzeitanwendungen sein kann (Kühnlein und Seubert 2016, S. 62). Dieser Aspekt spricht dafür, den nativen Ansatz für den Prototyp zu nutzen.
Im Rahmen des Masterprojekts von Mansel et al. (2018) wurde allerdings herausgefun-den, dass der in der HANA integrierte leichtgewichtige Anwendungsserver nicht für die Umsetzung eines Web-Scrapings genutzt werden kann. Das liegt zum einen daran, dass im Rahmen der für den HANA-Anwendungsserver verfügbaren Sprache XS JavaScript nur bestimmte Sprachelemente der Gesamtsprache JavaScript vorhanden sind und zum anderen daran, dass es nicht möglich ist, beliebige externe Bibliotheken zu importieren, die beispielsweise das Parsen von HTML-Dokumenten stark vereinfachen (Mansel et al. 2018, S. 33f). Aus diesem Grund muss der Prototyp mit einem externen Anwendungs-servers umgesetzt werden. Im folgenden Unterkapitel wird Node.js vorgestellt und er-läutert, warum es sich zur Implementierung des externen Anwendungsservers in dieser Arbeit eignet.
Node.js
In diesem Kapitel wird Node.js vorgestellt. Im ersten Unterkapitel wird begründet, wa-rum Node.js als Plattform für die Implementierung des Prototyps eignet. Im zweiten Unterkapitel wird die Funktionsweise und Umsetzung der asynchronen Programmierung im Rahmen von Node.js erläutert. Im dritten Unterkapitel wird das im Rahmen von Node.js wichtigste Framework Express vorgestellt. Im letzten Unterkapitel wird thema-tisiert, wie in Node.js eine Schichtenarchitektur für die Webapplikation realisiert werden kann. Für das Verständnis der letzten drei Unterkapitel werden Basiskenntnisse in der Programmiersprache JavaScript vorausgesetzt.
Standard für performante serverseitige Webapplikationen
Der Prototyp in dieser Arbeit soll durch eine serverseitige Web-Applikation umgesetzt werden. Da der in dieser Arbeit implementierte Prototyp später in der Art erweitert wer-den soll, dass er die Preisinformationen von einer hohen Anzahl von Wettbewerber-Webseiten automatisiert scrapt (Kapitel 4.4), stellt die Performanz eine herausragende Anforderung an die zu wählende Plattform dar. Zudem muss die genutzte Plattform über eine geeignete Threading-Architektur verfügen, um die parallel arbeitenden Web-Scraper (Kapitel 4.4) performant bearbeiten zu können. Im Folgenden wird erläutert, inwiefern die Node.js-Plattform insbesondere bezüglich der Performanz und der Threa-ding-Architektur optimiert ist, und somit besonders für die Implementierung geeignet ist.
Bei Node.js handelt es sich um eine Plattform, die die Entwicklung von serverseitigen Webapplikationen mit JavaScript ermöglicht (Roden 2012, S. vii). Eines der wichtigsten Argumente für die Nutzung von JavaScript in Node.js war, dass für JavaScript verschie-dene optimierte JavaScript-Engines existieren (Springer 2018, S. 40). JavaScript-Engi-nes erfüllen die Aufgabe, den JavaScript-Code zu interpretieren und auszuführen (Roden 2012, S. vii; Springer 2018, S. 40). Das Ziel der optimierten Engines ist, die Performanz bei der Interpretation zu maximieren, was wiederum zu einer hohen Performanz der Webapplikationen führt (Roden 2012, S. vii; Springer 2018, S. 40). In Node.js wird die JavaScript-Engine-V8 von Google genutzt, die aktuell der performanteste aller Ja-vaScript-Compiler ist (Roden 2012, S. vii; Springer 2018, S. 40). Im Folgenden wird zusammengefasst, wie die V8-Engine diese äußerst hohe Performanz erreicht.
Die V8-Engine interpretiert den JavaScript-Quellcode bei seiner Ausführung nicht direkt, sondern übersetzt ihn zuerst in Maschinencode, der dann ausgeführt wird (Springer 2018, S. 41). Dieses Vorgehen führt zu einer Steigerung der Ausführungsgeschwindig-keit der JavaScript-Applikation (Springer 2018, S. 41). Es existiert zudem ein weiterer Compiler, der den erzeugten Maschinencode an kritischen Stellen zusätzlich optimiert, was insbesondere bei größeren Webapplikationen vorteilhaft ist (Springer 2018, S. 45). Zudem ist die Engine selbst in C++ geschrieben, was ebenfalls einer hohen Performanz Rechnung trägt (Springer 2018, S. 40). Des Weiteren wurde das Speichermodell der V8-Engine bezüglich der Performanz optimiert (Springer 2018, S. 41). Es wurde eine besondere Kennzeichnung von einerseits Verweisen und andererseits Integerwerten im Speicher eingeführt, sodass die beiden Typen sehr schnell unterschieden werden kön-nen, was in einer deutlichen Performanzsteigerung resultiert (Springer 2018, S. 41). Einen weiter Vorteil der V8-Engine ist, dass ein sehr performanter Garbage-Collection-Prozess eingeführt wurde, der insbesondere für langlaufende Webapplikationen benötigt wird (Springer 2018, S. 46).
Ein weiterer Performanzvorteil von Node.js geht aus dessen Single-Thread-Architektur hervor (Springer 2018, S. 399). Anstatt eingehende HTTP-Anfragen und HTTP-Antwor-ten jeweils als eigenen Thread zu bearbeiten, werden sie von einem einzelnen Thread verarbeitet (Roden 2012, S. 11f). Damit dieser Haupt-Thread bei aufwändigen und zeit-intensiven Aufgaben nicht blockiert, delegiert er diese Aufgaben an andere Ressourcen, und bearbeitet sie erst weiter, wenn eine Antwort der anderen Ressource für die ent-sprechende Aufgabe an ihn zurückgegeben wird (Roden 2012, S. 12). Diese nicht-blo-ckierende Aufgabenbewältigung wird durch asynchrone Programmierung möglich. Bis die Antwort einer externen Ressource vorliegt, bearbeitet der Haupt-Thread die anderen Anfragen und delegiert wiederum deren Aufgaben (Roden 2012, S. 12). Die anderen Ressourcen benachrichtigen den Haupt-Thread über die Abschließung einer Aufgabe durch einen sogenannten Callback (Roden 2012, S. 12). Durch diese Architektur ist Node.js deutlich skalierbarer und performanter als klassische Webserver (Roden 2012, S. 12). Zudem werden die im Rahmen der Multi-Thread-Programmierung auftretende Probleme bezüglich des Managements von parallelen Threads sowie der Synchronisie-rung dieser Threads vermieden (Springer 2018, S. 32).
Überträgt man die Single-Thread-Architektur und asynchrone Programmierung auf die in dieser Arbeit entwickelte Webapplikation, die später eine hohe Anzahl von Webseiten automatisiert scrapen, die extrahierten Daten transformieren und anschließend in die HANA-Datenbank schreiben soll, ergibt sich der folgende beispielhafte performante Ab-lauf. Der Start aller Scraper, die nach neuen dynamischen Preisdaten suchen sollen, wird durch eine bestimmte HTTP-Anfrage (mit dem Browser) an die Webapplikation an-gestoßen. Wenn der Haupt-Thread den Programmteil erreicht, in dem die einzelnen Web-Scraper, die jeweils als Funktion realisiert sind, gestartet werden, wird der Code der ersten Funktion durchlaufen, bis die HTTP-Anfrage der Webapplikation an die zu scrapende Webseite gestartet wird. Anstatt synchron auf die HTTP-Antwort der Webseite zu warten und zu blockieren, wird ein Callback registriert, und der Haupt-Thread bear-beitet die Funktionen der anderen Web-Scraper und schickt für diese bereits die HTTP-Anfragen ab. Wenn die HTTP-Antwort einer Webseite ankommt und der registrierte Call-back ausgelöst wird, springt der Haupt-Thread an die entsprechende Programmstelle und führt die Programmlogik des Scrapings aus, bis schließlich an die Stelle gekommen wird, wo die gescrapten Daten durch eine HTTP-Anfrage an die HANA-Cloud-Datenbank geschickt werden. Auch hier wird nicht wieder auf die Antwort der Datenbank gewartet und blockiert, sondern ein Callback registriert und mit der Arbeit an einer anderen Stelle fortgefahren.
Durch die Single-Thread-Architektur und die asynchrone Programmierung können die verschiedenen Web-Scraping-Prozesse und Datenbanktransaktionen folglich sehr per-formant bearbeitet werden. Ein weiterer Vorteil der Callback-Architektur ist, dass eine zur Übersichtlichkeit der Webapplikation beitragende Trennung von Präsentations-schicht, Anwendungsschicht und Datenbankzugriffsschicht in mehrere JavaScript-Da-teien und selbstdefinierte Module sehr organisch realisiert werden kann (Kapitel 4.3.2.4).
Während die hohe Performanz von Node.js den Hauptgrund für dessen Wahl als Platt-form in dieser Arbeit darstellt, zeichnet sich Node.js weiterhin durch die unkomplizierte Arbeitsweise und schnell realisierbare Ergebnisse aus. Wenn ein neues Node.js-Projekt angelegt wird, ist es direkt mit einem funktionierenden Web-Server verknüpft, der mit einem einzelnen Kommando in der Kommandozeile gestartet werden kann. Für den Web-Server sind keine Konfigurationen durchzuführen und er muss nicht manuell mit der Webapplikation verknüpft werden. Auch bezüglich des Paket- und Abhängigkeits-managements ist Node.js sehr einfach handhabbar und übersichtlich. Node.js nutzt da-für den sogenannten Node.js-Package-Manager (kurz: npm), der bei dem Anlegen eines Node.js-Projekts mitinstalliert wird, und der ein Paket- und Abhängigkeitsmanagement mit einfachen Kommandos in der Kommandozeile ermöglicht. Externe Bibliotheken kön-nen durch das Kommando npm install importiert werden und an-schließend direkt im Quellcode des Projektes genutzt werden. Auch das Versionsma-nagement von externen Bibliotheken wird durch den npm gemanagt und muss nicht manuell vorgenommen werden.
Ferner zeichnet sich die Quellcode-Programmierung im Rahmen von Node.js durch einen sehr einfachen und unkomplizierten Umgang mit dem HTTP-Protokoll aus. Dazu gehören der Empfang von HTTP-Anfragen, das Versenden von HTTP-Antworten sowie die Arbeit mit diesen Nachrichtentypen (Roden 2012, S. 13). Dieser unkomplizierte Umgang ist insbesondere für die Implementierung des Web-Scrapings komfortabel. Ferner wird von dem Management von Details bezüglich der HTTP-Kommunikation abstrahiert (Roden 2012, S. 13).
Ein weiterer Vorteil von Node.js ist, dass eine sehr umfassende und gut nachvollziehbare Dokumentation dieser Plattform existiert. Aufgrund der „Hypes“ um Node.js als neue Web-Technologie (Roden 2012, S. 1), existieren eine Vielzahl von aktuellen und um-fangreichen Publikationen um Node.js, wie beispielsweise Brown (2014), Roden (2012), Springer (2018) sowie Hughes-Croucher und Wilson (2012). Diese ausführlichen Werke, die die Architektur und Funktionsweise von Node.js aus mehreren individuellen Perspektiven erläutern, ermöglichen es, die Plattform differenziert und lückenlos nachzuvollziehen. Sie erlauben zudem eine kontinuierliche Quellenbelegung des technischen Teils. Eine derart umfassende Dokumentation war beispielsweise im Rahmen des Masterprojekt von Mansel et. al (2018) für Java Servlets nicht vorhanden. Dort musste vermehrt auf Blogs und Video-Tutorials zurückgegriffen werden, um ein vollständiges Verständnis des Themas zu erlangen.
Asynchrone Programmierung
Im Folgenden wird erklärt, wie die Callback-Architektur als Quellcode umgesetzt werden kann. Die folgende Abbildung zeigt ein Beispiel-Programm. Als zeitaufwändige bzw. blo-ckierende und somit als Callback zu registrierende Aufgabe wurde hier eine Datenbank-transaktion gewählt. Es wird davon ausgegangen, dass in der Variablen database eine Referenz auf eine Datenbank gespeichert wurde. Das erste Kommando des Programms ist die Konsolenausgabe des Textes Zeile1. Anschließend wird ein als String formuliertes SQL-Datenbankstatement in der Variablen sql_command gespeichert. In der dritten Zeile soll nun eine aufwändige Datenbanktransaktion durchgeführt werden. Die Daten-bank hat dafür die asynchrone Methode exec() definiert. Die Signatur dieser Methode ist derart definiert, dass als erster Parameter das SQL-Kommando erwartet wird. Der Name der übergebenen Variablen ist frei wählbar, da nur statisch definiert ist, dass der erste Parameter das SQL-Kommando ist. Als zweiten Parameter erwartet sie die Defini-tion einer sogenannten Callback-Funktion, die ausgeführt wird, sobald die Datenbank die aufwändige Datenbanktransaktion ausgeführt hat.
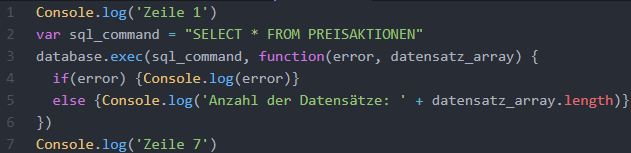
Bei den Parametern der Callback-Funktion handelt es sich um eine besondere Art von Parametern. Es handelt sich hier um Variablen, die es ermöglichen, sich auf den Kontext der asynchronen Datenbanktransaktion zu beziehen. Der erste Parameter ist derart de-finiert, dass er eine Fehlermeldung enthält, falls die Ausführung der Datenbanktransak-tion fehlerhaft war. Der zweite Parameter enthält ein Array von Datensätzen, falls die Datenbanktransaktion erfolgreich war. In dem Block (geschweiften Klammern) der Call-back-Funktion kann nun weitere Programmlogik definiert werden, die ausgeführt wer-den soll, sobald die Callback-Funktion aufgerufen wird, d. h. nachdem die ausgelagerte Aufgabe abgeschlossen ist. In dem Beispiel wird, falls ein Fehler bei der Datenbank-transaktion aufgetreten ist, die Fehlermeldung auf der Console ausgegeben. Falls kein Fehler aufgetreten ist, wird die Anzahl der Datensätze auf der Console ausgegeben, indem die Länge des resultierenden Arrays abgefragt wird.
Bezüglich der Ausführung ist festzuhalten, dass der Haupt-Thread, wenn er Zeile 3 er-reicht, die zeitaufwändige Aufgabe an eine externe Ressource (hier die Datenbank) de-legiert, und direkt mit der siebten Zeile fortfährt. Wenn die ausgelagerte Datenbank-transaktion, die einige Millisekunden dauert, abgeschlossen ist, wird der Haupt-Thread benachrichtigt, und er führt den Programmcode der Callback-Funktion aus. Es wird folg-lich auf der Konsole „Zeile 7“ ausgegeben, bevor die Fehlermeldung bzw. die Datensatz-anzahl auf der Konsole ausgegeben wird.
Express und Middlewares
Ein neu erstelltes Node.js-Projekt enthält eine bestimmte Basisfunktionalität (Roden 2012, S. 61). Um die Funktionalität zu erweitern, stehen sogenannte Module (externe Bibliotheken) bereit, die durch den Node.js-Package-Manager (kurz: npm) in das Projekt importiert werden können (Roden 2012, S. 61). Npm fungiert als Paketverwaltung von Node.js (Roden 2012, S. 61). Die Nutzung des npm mit der Kommandozeile wird in Kapitel 4.4 detaillierter erläutert. Die installierten Module können im Rahmen eines Ja-vaScript-Dokuments mit dem Quellcode require(‘‘) importiert werden (Brown 2014, S. 14). Die erste Zeile der folgenden Abbildung visualisiert den Import des Moduls „express“ und die Anbindung dieses Moduls an eine Konstante. Welcher Datentyp bzw. welche Datenstruktur mit require() importiert wird, hängt von der Defi-nition des exportierenden Moduls ab. Das Express-Modul gibt eine JavaScript-Funktion zurück, dessen Ausführung eine neue Express-Applikation zurückgibt (Springer 2018, S. 173). Die Referenz auf die Express-Applikation wird im Beispiel an die Konstante app gebunden.

Bei Express handelt es sich um das populärste und für viele Entwickler unverzichtbare Framework bzw. Modul im Rahmen von Node.js (Springer 2018, S. 171). Es hat das Ziel, die Entwicklung von Webapplikation zu erleichtern, indem es Node.js um eine Ar-chitektur erweitert, die die Überschaubarkeit und Geschwindigkeit von Webapplikation verbessert (Springer 2018, S. 171). Zudem bietet Express Methoden an, die es dem Programmierer ermöglichen, von dem Management wiederkehrender Standardaufgaben zu abstrahieren (Springer 2018, S. 172). Dazu gehören insbesondere die Methoden, die das Erstellen und Managen eines Webservers umsetzen (Springer 2018, S. 172). Zudem existieren Methoden, die die Verwaltung von HTTP-Anfrage- und HTTP-Antwort-Objek-ten stark vereinfachen (Springer 2018, S. 172). Ferner setzt Express das Routing der Webapplikation in übersichtlicher Weise um (Springer 2018, S. 172). Unter Routing wird das Management der in einer HTTP-Anfrage des Klienten vorhandenen URL (Pfad) ver-standen, die eine bestimmte Ressource des Servers referenziert.
Das Express-Framework ist derart angelegt, dass es bei der initialen Installation über einen kompakten und überschaubaren Funktionsumfang verfügt (Springer 2018, S. 171f). Diese Funktionalität lässt es sich mit sogenannten externen Modulen um um-fangreiche Funktionalität erweitern (Springer 2018, S. 171f). Auf diese Weise ist es möglich, nur die Funktionalität zu importieren, die tatsächlich in dem Projekt benötigt wird (Springer 2018, S. 171f).
Ein wichtiger Aspekt der Softwarearchitektur von Express ist, dass die Verarbeitung von eingehenden HTTP-Anfragen durch eine sogenannte Pipeline erfolgt (Brown 2014, S. 109). Im Rahmen dieser Pipeline wird eine bestimmte Reihenfolge von sogenannten Middleware-Komponenten definiert, die jeweils eine bestimmte Funktionalität kapseln (Brown 2014, S. 109). Externe Module können als Middleware verwendet werden. Aber auch eigene Middlewares können definiert werden. Wird eine HTTP-Anfrage vom Web-Server empfangen, durchläuft sie die verschiedenen Middleware-Komponenten und wird dadurch verarbeitet (Brown 2014, S. 109). Die letzte Middleware einer Pipeline musseine HTTP-Antwort formulieren und an den Klienten zurückschicken (Brown 2014, S. 109).
Für die jeweiligen Middlewares wird definiert, wie sie auf verschiedene HTTP-Anfragen reagieren sollen, bzw. ob sie überhaupt auf eine Anfrage, beispielsweise mit einer be-stimmten URL, reagieren (Brown 2014, S. 109). Somit können die Behandlungen von verschiedenen Anfragen, obwohl die chronologische Reihenfolge der durchlaufenen Mi-ddlewares festgelegt ist, unterschiedlich sein (Brown 2014, S. 109). Um eine beste-hende Middleware in die Pipeline einzufügen oder eine eigene Middleware zu definieren, wird app.use(…) verwendet, wenn app die Express-Applikation referenziert (Brown 2014, S. 111). Die genaue Nutzung von app.use() wird später vorgestellt.
Eine besondere Art von Middlewares stellen die sogenannten Routing-Middlewares dar (Brown 2014, S. 110). Routing-Middlewares haben insbesondere die Aufgabe, dem Kli-enten die Antwort bzw. die Ressource zurückzuschicken, die er angefragt hat (Brown 2014, S. 15). Die Routing-Middlewares behandeln, im Gegensatz zu den anderen Midd-lewares, nur HTTP-Anfragen, die eine spezielle HTTP-Methode, wie GET oder POST, und einen bestimmten URL-Pfad aufweisen, beispielsweise „/home“ (Brown 2014, S. 110). Um GET-Anfragen aufzufangen wird app.get() und um POST-Anfragen aufzufangen app.post() verwendet (Brown 2014, S. 111). Ein Beispiel einer Routing-Middleware wird in der folgenden Abbildung dargestellt. Der String-Parameter „/home“ definiert, dass Anfragen mit dem Pfad „/home“ aufgefangen werden. Der erste Parameter der Callback-Funktion, der hier request genannt wurde, referenziert die HTTP-Anfrage des Klienten, sodass beispielsweise der Body der Anfrage ausgelesen werden kann. Der zweite Para-meter referenziert ein von Express bereits vorbereitetes Objekt, das die HTTP-Antwort darstellt. Durch den Aufruf der Funktion send(), wird der definierte String als Body der HTTP-Antwort gesetzt und die HTTP-Antwort direkt an den Klienten geschickt.

Im Folgenden werden zwei vordefinierte Middlewares erläutert, die im Rahmen des Pro-totyps verwendet werden. Die Middlewares werden von externen Modulen definiert, die vorher ins Projekt importiert werden müssen. Es werden zum einen die theoretischen Grundlagen und zum anderen die Einbindung der beiden Middlewares in die Pipeline erläutert.
Handlebars-Middleware
Bei der Handlebars-Middleware handelt es sich um eine Middleware zur standardisierten Erstellung der Benutzeroberfläche von Webapplikation. Sie wird benötigt, da im Rahmen des Prototyps eine Benutzeroberfläche umgesetzt werden soll, mit der beispielsweise der Scraping-Prozess gestartet werden kann oder die Daten aus der Datenbank gelesen und angezeigt werden können. Die Handlebars-Middleware ist ein Framework, das die Trennung von Views und dem Kontext, der in den Views angezeigt werden soll, umsetzt (Brown 2014, S. 67f). Views werden auch als Vorlage (engl.: template) bezeichnet (Brown 2014, S. 67f). In der View, die durch HTML definiert ist, werden mehrere Platz-halter definiert, an deren Stelle später der an die View gesendete Kontext anzeigt wer-den soll (Brown 2014, S. 71). Die Handlebars-Middleware gibt vor, dass der Kontext in der View bzw. im HTML-Dokument durch eine doppelte geschweifte Klammer eingefasst werden muss (Brown 2014, S. 71). Die Variablenbezeichnung in den geschweiften Klammern muss mit dem Namen eines Objekts übereinstimmen, das im Kontext defi-niert wurde (Brown 2014, S. 71). Die folgende Abbildung illustriert, wie eine Vorlage (engl.: template) und ein Kontext zu einem Output zusammengesetzt werden.
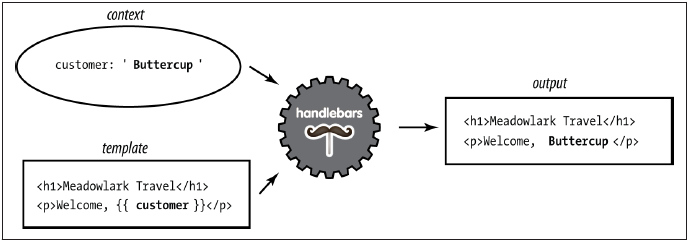
(Brown 2014, S. 71)
Die folgende Abbildung zeigt, wie die Handlebars-Middleware in ein Projekt importiert und zur Nutzung vorbereitet werden kann. Zunächst muss dem Express-Framework (app) mitgeteilt werden, wo sich die definierten Views befinden. Dazu kann die Methode set(‘views‘, …) der Express-Applikation verwendet werden. In diesem Projekt wurde für die Views im Unterordner Praesentationsschicht ein Unterordner views angelegt. Der folgende Code definiert, dass Dateien mit der Endung „.hbs“ Handlebar-Templates dar-stellen. Ferner wird festgelegt, dass für alle Handlebars als Standardlayout die Datei main_layout.hbs genutzt werden soll. Ein Standardlayout kann als gemeinsames Temp-late aller Views verstanden werden, in das alle Views eingebettet sind (Brown 2014, S. 74). Im Standardlayout wird in diesem Projekt die Navigationsleiste definiert, die für alle Views angezeigt werden soll. Es ist hier anzumerken, dass die Funktion engine() die Einbettung der Middleware in die Pipeline übernimmt, sodass hier nicht explizit app.use() verwendet werden muss.
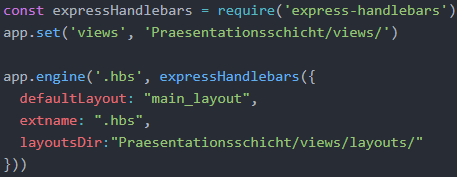
Body-Parser-Middleware
In der Webapplikation (Kapitel 4.4.1) existiert eine Web-Formular (engl.: form) mit fünf Knöpfen, die verschiedene Datenbankfunktionen auslösen. Web-Formulare, die bei ihrer Bestätigung mit einer POST-Anfrage an den Webserver gesendet werden, speichern die Eingaben des Benutzers in dem Body der HTTP-Anfrage mit einer bestimmten Codie-rung, der sogenannten URL-Codierung (Brown 2014, S. 89f). Die Body-Parser-Middle-ware wird benötigt, um die codierten Eingaben der eingehenden Form in Express ver-fügbar zu machen (Brown 2014, S. 89f). Sie parst die Informationen und speichert sie leicht zugreifbar in dem Anfrage-Objekt (Brown 2014, S. 89f). Wie dies genau funktio-niert, wird in Kapitel 4.4.1 näher erläutert. Die folgende Abbildung zeigt, wie die Body-Parser-Middleware importiert und mit app.use() in die Pipeline eingefügt wird.

Schichtenarchitektur
Um eine übersichtliche und wartbare Webapplikation zu erstellen, bietet sich die Eintei-lung der Webapplikation in drei Schichten an (Tutisani o. J.). Wenn die Schichten stan-dardisierte Schnittstellen definieren, ist es zudem möglich, verschiedene Implementie-rungen einer Schicht auszutauschen, womit die Schichten unabhängig voneinander sind (Tutisani o. J.). Die Einteilung in Schichten verbessert zudem die Wiederverwendbarkeit und Testbarkeit des Codes (Tutisani o. J.). Der Standard für Webapplikationen ist eine Einteilung in Präsentationsschicht, Anwendungsschicht und Datenzugriffsschicht (Tu-tisani o. J.).
Im Rahmen einer Webapplikation ist die Präsentationsschicht für den Empfang und das Routing von HTTP-Anfragen sowie die Weiterleitung dieser Anfragen an die entspre-chenden Middlewares der Anwendungsschicht zuständig (Tutisani o. J.). Zudem ist sie für das Zurücksenden einer HTTP-Antwort an den Klienten zuständig (Tutisani o. J.). Die Anwendungsschicht umfasst die Anwendungslogik der Webapplikation (Tutisani o. J.), was im Rahmen dieser Arbeit insbesondere die Umsetzung des Web-Scrapings umfassen wird. Die Anwendungsschicht ruft zudem die Datenzugriffsschicht auf (Tutisani o. J.). Auf der Datenzugriffsschicht wird die Interaktion mit der Datenbank reali-siert, beispielsweise das Schreiben von Daten in die Datenbank oder das Lesen von Daten aus der Datenbank (Tutisani o. J.).
Die Schichtenarchitektur kann im Rahmen von Node.js durch die Erstellung von eigenen Modulen umgesetzt werden, wobei jedes Modul jeweils einer JavaScript-Datei entspricht (Brown 2014, S. 34f). Im Rahmen eines Moduls können verschiedene Funktionalitäten durch Middlewares umgesetzt werden, die als JavaScript-Funktionen realisiert werden (Brown 2014, S. 112). Die einzelnen Middlewares eines Moduls können von einem an-deren Modul importiert werden (Brown 2014, S. 112). Die Middleware muss in dem exportierenden Modul mit module.exports. definiert werden (Brown 2014, S. 112).
Die folgende Abbildung illustriert die Definition einer beispielhaften Middleware. Es soll hier davon ausgegangen werden, dass die Middleware in einer JavaScript-Datei anwen-dungsschicht.js definiert ist, die die Anwendungsschicht repräsentiert. Um die asyn-chrone Architektur von Node.js einzuhalten, muss die Middleware als Callback-Funktion realisiert werden. Die Middleware erfüllt hier die Aufgabe der Addition von zwei Sum-manden, die der Middleware als Parameter übergeben werden. Bei dem dritten Para-meter callback handelt es sich hier nicht um eine weitere Callback-Funktion, sondern um einen Rückgabewert, der bei der Beendigung der Middleware zurückgegeben wird. Der Rückgabewert wird in callback(…) definiert, was in diesem Beispiel ein JavaScript-Objekt ist, dem als Eigenschaft summe der Wert der Variable summe zugewiesen wird.

In Anlehnung an (Brown 2014, S. 112)
Um die Middleware in einem anderen Modul bzw. einer anderen JavaScript-Datei benut-zen zu können, muss zunächst das exportierende Modul importiert werden. Es wird hier angenommen, dass anwendungsschicht.js in einem Ordner Anwendungsschicht definiert wurde. Das Modul kann dann mit require() importiert und in einer Variablen anwen-dungsschicht gespeichert werden, wie es in der folgenden Abbildung dargestellt ist. Die Middleware bildeSumme() kann anschließend aufgerufen werden. Es muss zudem eine Callback-Funktion definiert werden, die aufgerufen wird, wenn bildeSumme() abge-schlossen ist. Die Callback-Funktion enthält das von bildeSumme() zurückgegebene Ja-vaScript-Objekt als Kontext, das hier mit callbackData bezeichnet wird. Mit callback-Data.summe kann die zurückgegebene Summe verwendet werden.
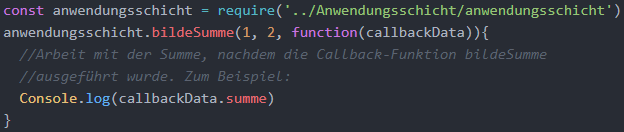
Recent Comments